

估计阅读时长: 7 分钟Boids算法(也称鸟群/鱼群算法)是Craig Reynolds于1986年提出的群体行为模拟模型,通过三条局部规则模拟鸟类、鱼群等生物群体的自组织运动。在Boids算法中,整个过程通过个体(称为“boid”)的局部交互实现全局有序行为,无需中央控制。每条规则计算个体与邻居的相互作用力,最终合力决定运动方向。Boids算法的精髓在于用局部规则涌现全局智能,其简洁性、可扩展性使其成为连接生物行为与工程控制的桥梁。从《蝙蝠侠》的蝙蝠群到无人机编队表演,从游戏生态到交通优化,Boids持续证明:自然界的简单规则,足以驱动复杂系统的有序演化。 Order by Date Name Attachments Boids • 28 MB • 803 click 2025年8月10日Boids • […]

估计阅读时长: 24 分钟假若现在有两条Fasta序列放在你面前,现在需要你进行这两条Fasta序列的相似度计算分析。如果对于我而言,大学刚毕业刚入门生物信息学的时候,可能只能够想到通过blast比对的方式进行序列相似性计算分析。基于blast比对方式可以找到生物学意义上的序列相似性结果,但是计算的效率会比较低。假设现在让你使用这些序列进行机器学习建模分析,或者基于传统数学意义上的基于相似度的无监督聚类分析的时候,面对这些长度上长短不一的生物序列数据,可能会比较蒙圈,因为传统的数学分析方法都要求我们分析的目标至少应该是等长的向量数据。 Order by Date Name Attachments Fasta-A • 544 kB • 930 click 2023年6月29日visualize • 45 […]

估计阅读时长: 11 分钟给定一组n个字符串数组,找到包含给定集合中每个字符串的最小字符串作为子字符串。我们可以假设这个字符串数组中没有字符串是另一个字符串的子字符串。那么基于上面的描述,我们就可以得到下面所示的问题求解目标: let arr[] = ["catg", "ctaagt", "gcta", "ttca", "atgcatc"] // output: gctaagttcatgcatc 上面的问题描述实际上是一个最短超字符串问题(shortest common superstring) Order […]
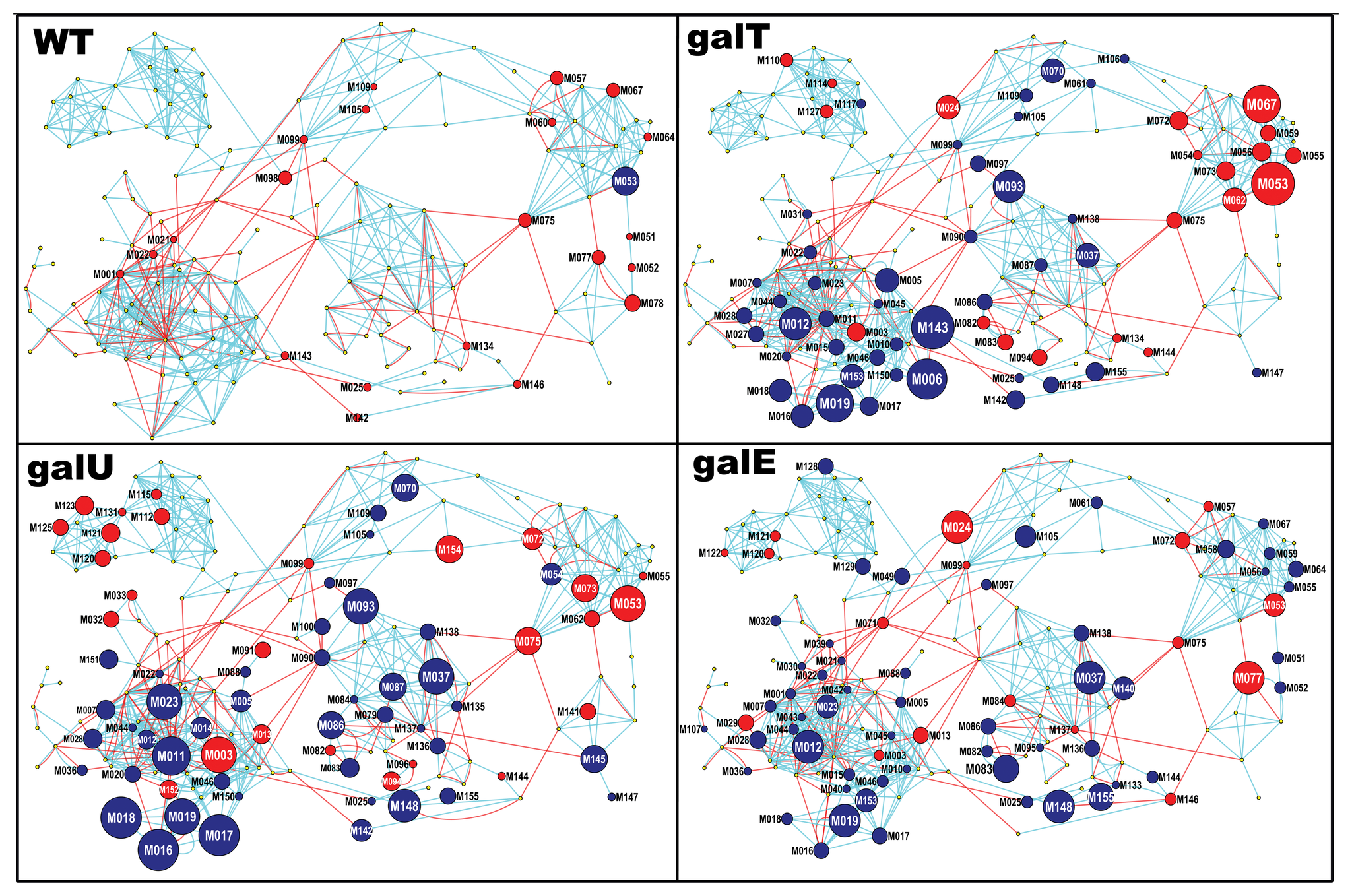
估计阅读时长: 5 分钟在工作之中可能会遇到需要进行两个网络图对象之间的相似度计算的情形:例如在质谱数据分析的化学信息学计算工作之中,我们在解析SMILES字符串得到分子图之后,可以基于图相似度比较计算方法来比较计算两个代谢物分子图之间的结构上的相似度。 Attachments pone.0078360.g003 • 2 MB • 1043 click 2022年8月6日https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0078360
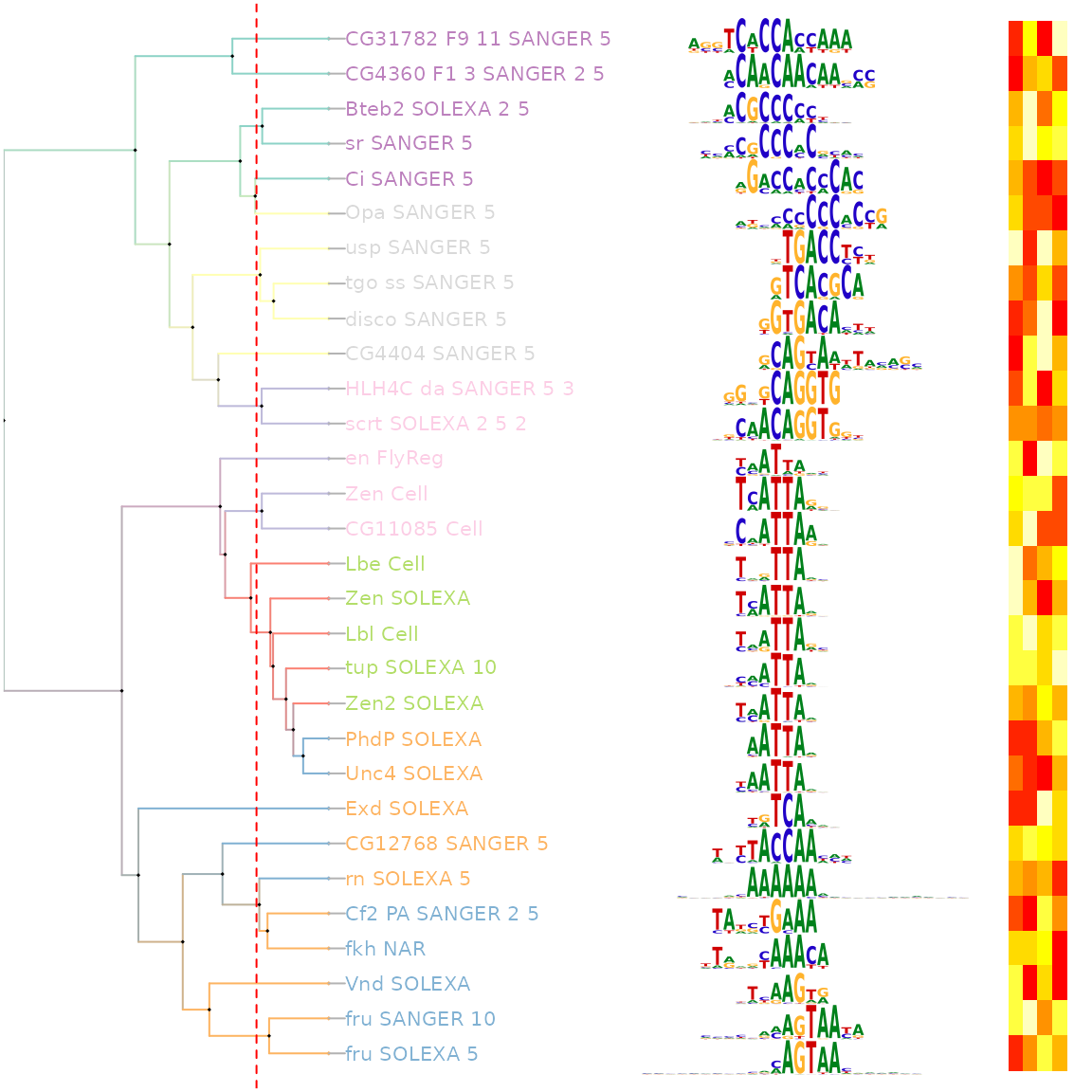
估计阅读时长: 12 分钟Motif是一段典型的序列或者一个结构。一般情况下是指构成任何一种特征序列的基本结构。通俗来讲,即是有特征的短序列,一般认为它是拥有生物学功能的保守序列,可能包含特异性的结合位点,或者是涉及某一个特定生物学过程的有共性的序列区段。比如蛋白质的序列特异性结合位点,如核酸酶和转录因子。 Order by Date Name Attachments Smith-Waterman-Algorithm-Example-Step3 • 8 kB • 1029 click 2022年6月7日motifPilesHeatmap-1 • 227 […]
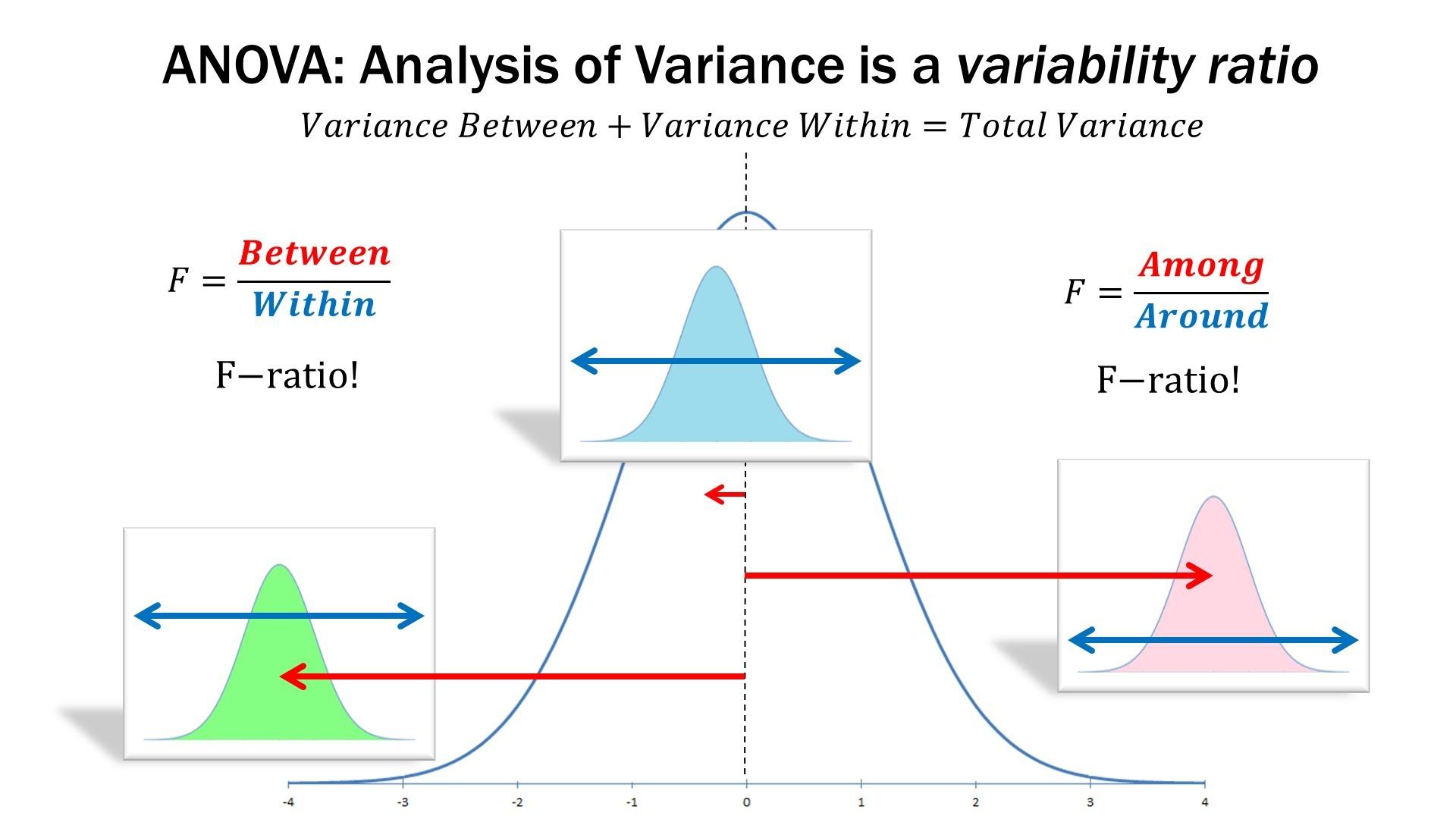
估计阅读时长: 14 分钟一般而言,如果我们在进行组学数据分析的时候,如果想要比较两组数据之间是否存在有差异性,一般是对两两比较的两组数据进行T-检验。但是在代谢组学数据分析领域内,则很多的组学数据分析情况为比较两组以上的数据,寻找差异的biomarker。那这个时候就需要使用上ANOVA统计检验方法了。 Order by Date Name Attachments anova • 105 kB • 1249 click 2022年5月28日ANOVA-screen • 27 […]
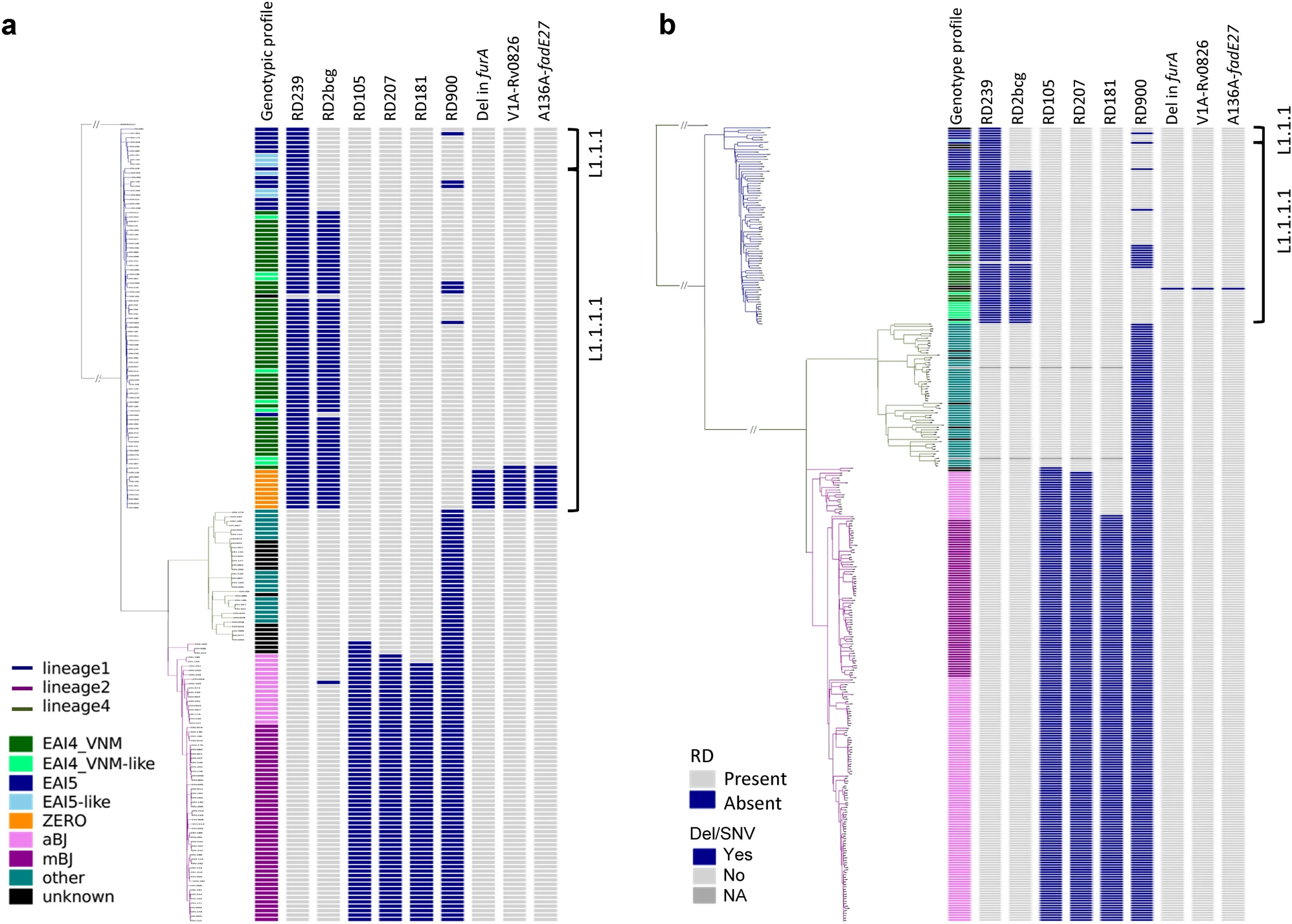
估计阅读时长: 7 分钟F统计量是群体遗传学中由Sewall Wright提出的重要统计量,用于衡量遗传变异在群体中的分布情况。它提供了对群体遗传结构和遗传分化的定量描述。F统计量主要有三种类型:Fis、Fit和Fst,分别反映个体内的、总体的和群体间的遗传分化。F统计量在群体遗传学中通常指的是Fst(Fixation Index,固定指数),它是一个衡量群体间遗传差异的指标。Fst的值范围从0到1,其中0表示群体间没有差异,1表示群体间完全分离。在群体遗传学研究中,Fst常用于评估群体的遗传多样性、群体间的迁移率以及自然选择的压力等。 Order by Date Name Attachments 41598_2021_92984_Fig1_HTML • 2 MB • 1053 click 2022年5月28日p1 […]
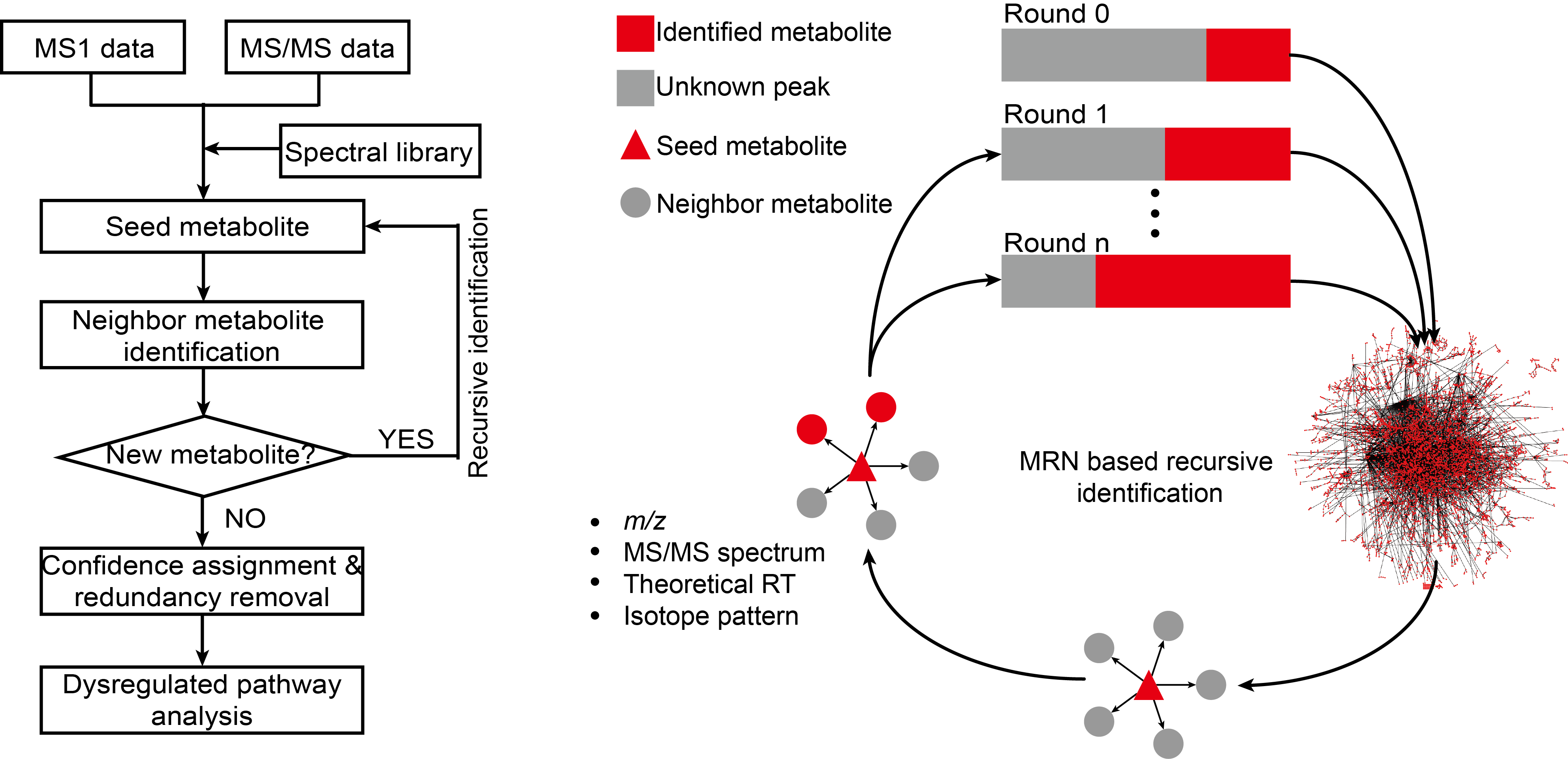
估计阅读时长: 6 分钟访问在线服务: http://metdna.zhulab.cn/ Metabolite identification is the long-standing challenge for liquid chromatography-mass spectrometry (LC-MS)-based untargeted metabolomics. Here, […]
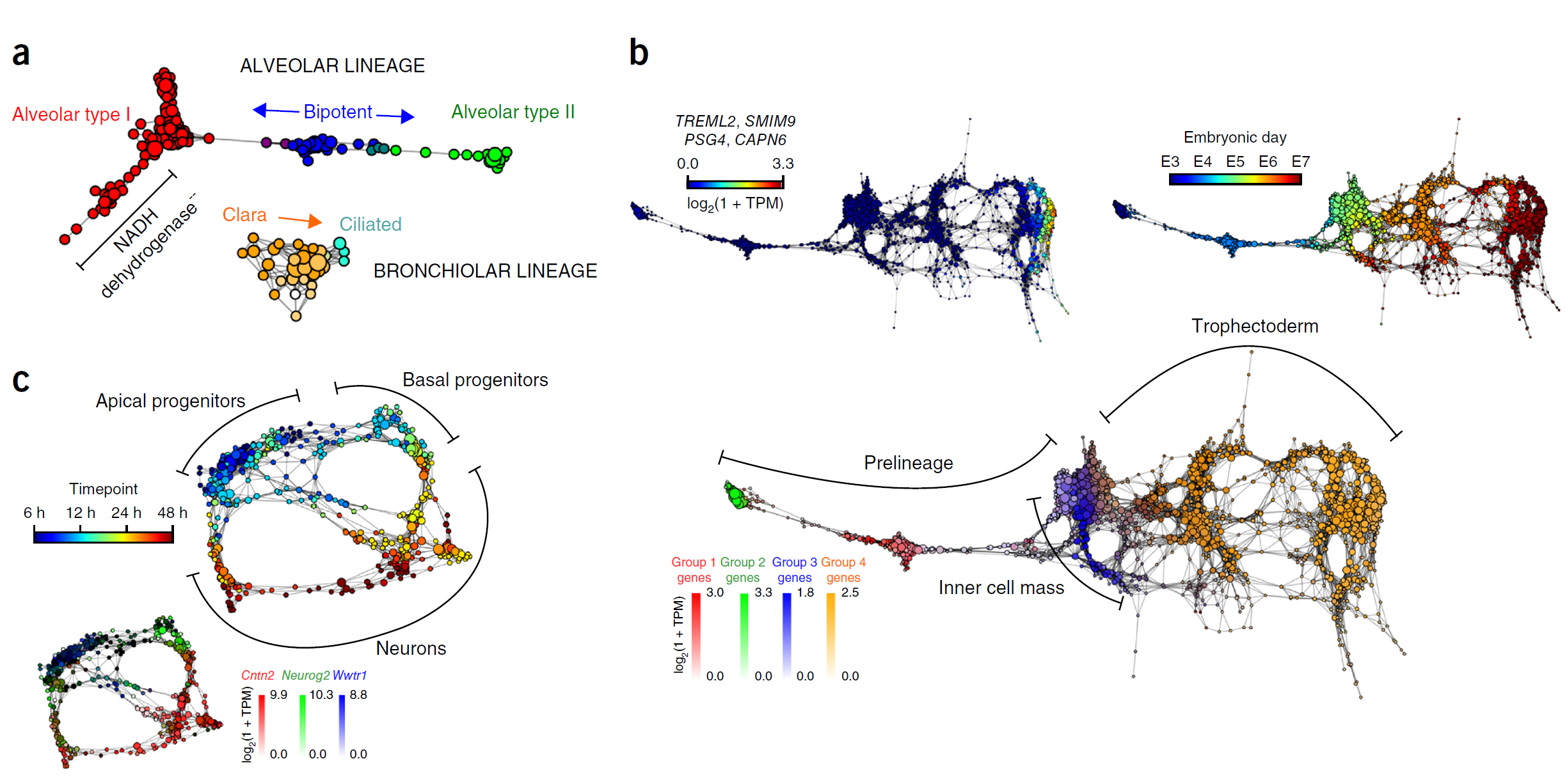
估计阅读时长: 14 分钟单细胞分析方法学习文献打卡记录: 【单细胞组学】PhenoGraph单细胞分型 【单细胞分析方法】VeTra:基于RNA速度的轨迹推断工具 【单细胞分析方法】单细胞图嵌入 Order by Date Name Attachments Cellular populations during motor neuron differentiation • […]
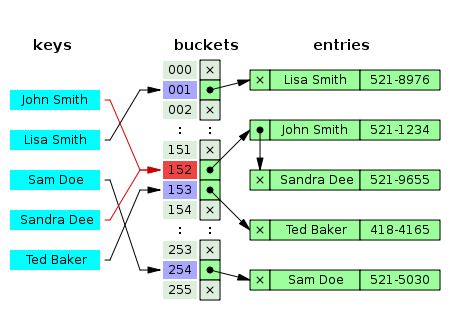
估计阅读时长: 8 分钟在之前的BioDeep代谢物数据库整合工作之中,所提取的代谢物注释信息的唯一编码是来自于数据库表之中的递增主键。由于数据库之中的递增主键的唯一编码值是与数据内容完全无关的数据,所以在基于图数据库做数据库整合的结果在两次整合操作之后,可能会因为先后输出顺序不一致的原因,得到的在关系型数据库中的唯一递增编号可能会完全不一样了。这个问题会对数据库更新操作造成非常大的困扰。 Order by Date Name Attachments 450px-Hash_table_5_0_1_1_1_1_1_LL • 26 kB • 916 click 2022年4月16日metadata-table • 58 […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?