
文章阅读目录大纲
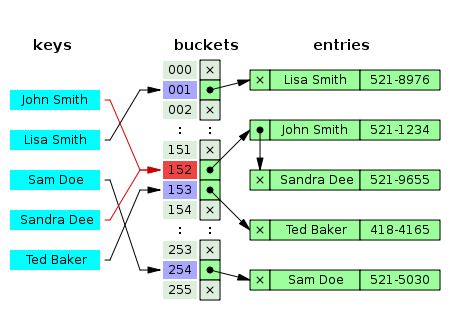
在之前的BioDeep代谢物数据库整合工作之中,所提取的代谢物注释信息的唯一编码是来自于数据库表之中的递增主键。由于数据库之中的递增主键的唯一编码值是与数据内容完全无关的数据,所以在基于图数据库做数据库整合的结果在两次整合操作之后,可能会因为先后输出顺序不一致的原因,得到的在关系型数据库中的唯一递增编号可能会完全不一样了。这个问题会对数据库更新操作造成非常大的困扰。
在最近的代谢物注释信息数据库整合工作之中,为了解决前面的工作所遇到的这个问题,引入了FNV-1a哈希算法来确保所获取得到的代谢物注释信息数据集在多次整合操作之后任然能够获取得到唯一并且相同的唯一编号。
FNV-1a哈希算法
FNV哈希被设计为快速,同时保持较低的冲突率。FNV算法允许一个快速散列大量的数据,同时保持合理的碰撞率。FNV散列的高度分散性使其非常适合散列几乎相同的字符串,例如URL,主机名,文件名,文本,IP地址等。
The basis of the FNV hash algorithm was taken from an idea sent as reviewer comments to the IEEE POSIX P1003.2 committee by Glenn Fowler and Phong Vo back in 1991. In a subsequent ballot round: Landon Curt Noll improved on their algorithm. Some people tried this hash and found that it worked rather well. In an Email message to Landon, they named it the ``Fowler/Noll/Vo'' or FNV hash.
FNV hashes are designed to be fast while maintaining a low collision rate. The FNV speed allows one to quickly hash lots of data while maintaining a reasonable collision rate. The high dispersion of the FNV hashes makes them well suited for hashing nearly identical strings such as URLs, hostnames, filenames, text, IP addresses, etc.
source: http://www.isthe.com/chongo/tech/comp/fnv/index.html
从算法网站上获取得到的FNV-1a哈希算法的伪代码如下所示:
hash := FNV_offset_basis
for each byte_of_data to be hashed do
hash := hash XOR byte_of_data
hash := hash × FNV_prime
return hash将上面的伪代码实现为VB代码的话,如下所示:
Public Function GetHashCode(targets As IEnumerable(Of Object)) As Integer
Const offset As Integer = 2166136261
Const prime As Integer = 16777619
Return targets.Aggregate(
seed:=offset,
func:=Function(hashCode As Integer, value As Object)
If value Is Nothing Then
Return (hashCode Xor 0) * prime
Else
Return (hashCode Xor getHashValue(value)) * prime
End If
End Function)
End Function通过上面的算法,我们就可以基于任意一组数据计算出该输入的数据序列所对应的FNV-1a哈希值。
骨感的现实
上面的哈希函数的调用非常的简单,但是细心的你会发现,我们所输入的数据是一个Object类型的枚举序列,而这个哈希计算函数所能够接受的计算数据类型则是Integer类型的32位整形数。所以大家可以发现在计算XOR操作的表达式部分是存在有一个getHashValue
在这个getHashValue函数的编写思路非常简单,如果Object数Integer类型,则直接返回Integer参与哈希值计算。但是如果数据是String类型的呢?我们可能首先想到的是字符串本身的GetHashCode函数调用。但是这个会存在一个问题:.NET环境之中的GetHashCode函数所计算得到的哈希码只能够保证在当前程序进程内是唯一且相同的。这就会导致,即使是相同的两个字符串的值,在两个程序进程间,调用GetHashCode函数,将会得到不一样的哈希值。
字符串唯一哈希值
在这里,为了确保不管重复执行数据库重建脚本多少次,相同的字符串计算得到的哈希值是一致的,参考了《Why is string.GetHashCode() different each time I run my program in .NET Core?》文章里面的方法编写了一个用于保证相同的字符串计算出相同的哈希值的计算函数:
Public Function GetDeterministicHashCode(str As String) As Integer
Dim hash1 As Integer = (5381 << 16) + 5381
Dim hash2 As Integer = hash1
For i As Integer = 0 To str.Length - 1 Step 2
hash1 = (hash1 << 5) + hash1 Xor AscW(str(i))
If i = str.Length - 1 Then
Exit For
Else
hash2 = (hash2 << 5) + hash2 Xor AscW(str(i + 1))
End If
Next
Return hash1 + hash2 * 1566083941
End Function上面的函数可以保证将相同的字符串计算为相同的Integer哈希值,但是可能没有办法保证不出现哈希冲突。那现在我们将GetDeterministicHashCode
R#
R#将上面所实现的两个哈希函数导出为R#
- strHashcode用于计算字符串的唯一哈希值,这个哈希值在相同的字符串输入值间保持一致,但是不能够保证哈希值没有冲突
- FNV1aHashcode函数基于一组输入的数据计算出某一个对象的唯一哈希值,并且可以保证较少的哈希值冲突的情况出现在我们的数据库中
<ExportAPI("strHashcode")>
Public Function stringHashCode(str As String) As Integer
Return str.GetDeterministicHashCode
End Function
<ExportAPI("FNV1aHashcode")>
Public Function FNV1aHash(<RRawVectorArgument> [set] As Object, Optional env As Environment = Nothing) As Integer
Return FNV1a.GetHashCode(getObjectSet([set], env))
End Function数据库哈希测试

现在假设我们已经将代谢物注释信息图数据库导出为如上所示的一张二维表之后,我们就可以根据特定的列数据进行代谢物注释信息的唯一哈希值的计算操作了。下面使用R#脚本代码来为大家演示整个计算过程:
# unique hash code test
dataset = read.csv(`${@dir}/metadata.csv`, row.names = 1);
index = dataset[, ["cas", "kegg", "formula", "inchikey", "hmdb","chebi","lipidmaps"]];
cat("\n\n");
print("view content index data:");
print(index);首先我们来看一下进行哈希计算的索引列信息有哪些:

可以看到有这些数据库交叉引用的信息可以让我们应用于数据库唯一哈希索引的计算,下面我们只需要简单的对上面的索引数据进行FNV-1a哈希值计算操作即可:
hashSet = index
|> as.list(byrow = TRUE)
|> sapply(function(obj) {
toString(abs(FNV1aHashcode(obj)), format ="F0");
});
cat("\n\n");
print("get unique reference id of the metadataset:");
print(`BioDeep_${str_pad(hashSet, 10, pad = "0")}`);
# [1] "BioDeep_0575054657" "BioDeep_1600502933" "BioDeep_0835306603"
# [4] "BioDeep_0806957015" "BioDeep_0200517077" "BioDeep_0123575871"
# [7] "BioDeep_1261152084" "BioDeep_1297237314" "BioDeep_0003467586"
# [10] "BioDeep_1436769182" "BioDeep_0131846530"
- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

No responses yet