
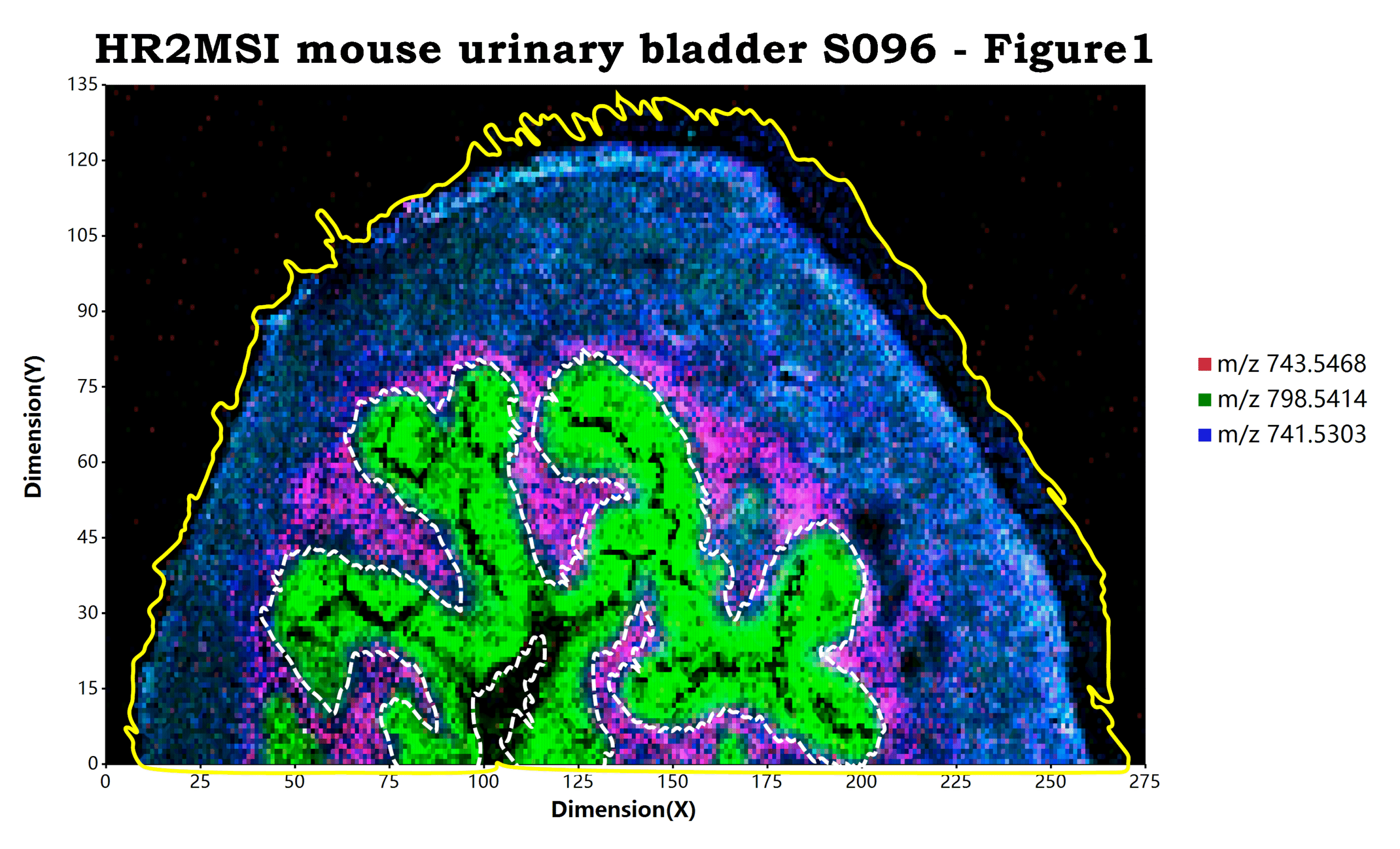
估计阅读时长: 10 分钟目前经过改进和优化之后的基于mzkit代码库底层的msimaging质谱成像软件包在样本可视化上进行了非常多的改进,诸如: 添加样本原始背景叠加 目前进行质谱成像可视化,程序包不仅仅可以使用任意rgb纯色来作为可视化的背景。目前还可以支持直接使用原始数据的背景作为质谱成像的显示背景。进行这个显示的秘诀就在于简单的在脚本中添加一个TIC背景图层:geom_MSIbackground("TIC") ggplot(msi_data, padding = "padding: 200px 600px 200px 250px;") + geom_MSIbackground("TIC") # rendering of […]

估计阅读时长: 4 分钟假设我们现在拥有魔兽世界游戏的GM权限,那么我们可以怎样来组织一场有一千个玩家参加的PvP战斗呢? Order by Date Name Attachments 762191341 • 619 kB • 866 click 2025年6月7日AddonList • 35 […]

估计阅读时长: 10 分钟 https://github.com/rsharp-lang/athena 在这博客篇文章中的Idea来自于最近进行AI Agent的开发:希望可以有一个方便的框架,能够让我像写普通的R#程序包的方式,为大语言模型编写对应的工具包,实现AI Agent功能。经过了大概一天的摸索,搞定了这样子的AI Agent的框架。我将这个框架取名为雅典娜系统。关于这个系统的名称,我们首先来看看DeepSeek是怎么说的: “我现在正在开发一个和大语言模型助手相关的工具,这个工具可以完成通过自然语言聊天的方式调用相应的工具完成生信数据分析,我需要为这个项目取一个名称,要求这个项目的名称应该是符合下面的需求的:女孩英文名称,和智慧相关的,和科学相关的。为我列举一些候选名称” 根据你的需求(女孩英文名、智慧与科学相关),结合搜索结果中的历史文化名人和寓意,以下是推荐的候选名称及来源解析: 名字 寓意 关联 Athena 源自希腊神话的智慧女神,象征智慧与科学战略。 雅典娜不仅是智慧化身,也代表理性思维,适合强调数据分析与策略的项目。 Clara 拉丁语“明亮、清晰”,象征清晰的科学思维。 […]

估计阅读时长: 9 分钟因为一种单一的编程语言并不会覆盖到所有的适用场景的原因,在一个软件工程项目之中,采用多种语言进行混合编程是一种很常见的协作方式。例如,脚本化的语言,其非常适合于进行最顶层的应用开发,就像胶水一样用于将各种组件进行粘贴,但是脚本化的语言自身因为是基于其他的语言所构建,所以执行效率一般不会太好。对于底层组件,我们一般就会需要使用静态编译类型的非托管语言创建用于高性能数据处理的模块。对于这种需求的底层模块,我们一般可以采用C/C++/Rust来编写。 Order by Date Name Attachments rust • 162 kB • 942 click 2023年3月25日dyn-load • 67 […]
估计阅读时长: 5 分钟在BILIBILI上观看视频:《【BioNovoGene Mzkit教程】代谢组学原始数据处理基础》 最近我在B站的视频页面下发现了这样的一条评论,面对质谱数据分析领域内的初学者的求教,其实自己也是非常的诚惶诚恐的。因为在视频中所使用的脚本语言是自己开发的一门新语言,所以可能给一些初学者造成了一部分的困扰哈哈😅😄😅😅。首先先对这个粉丝说一声抱歉哈。 针对上述的提问,我的回答大概是有以下的几点: Order by Date Name Attachments question_20230223 • 17 kB • 876 click […]
估计阅读时长: 31 分钟Like the original R language it does, the R# system just provides a runtime to running […]

估计阅读时长: 69 分钟Read on CodeProject: https://www.codeproject.com/Articles/5338916/Introducing-Rsharp-language With many years of do scientific computing works by VB.NET language, I'm […]
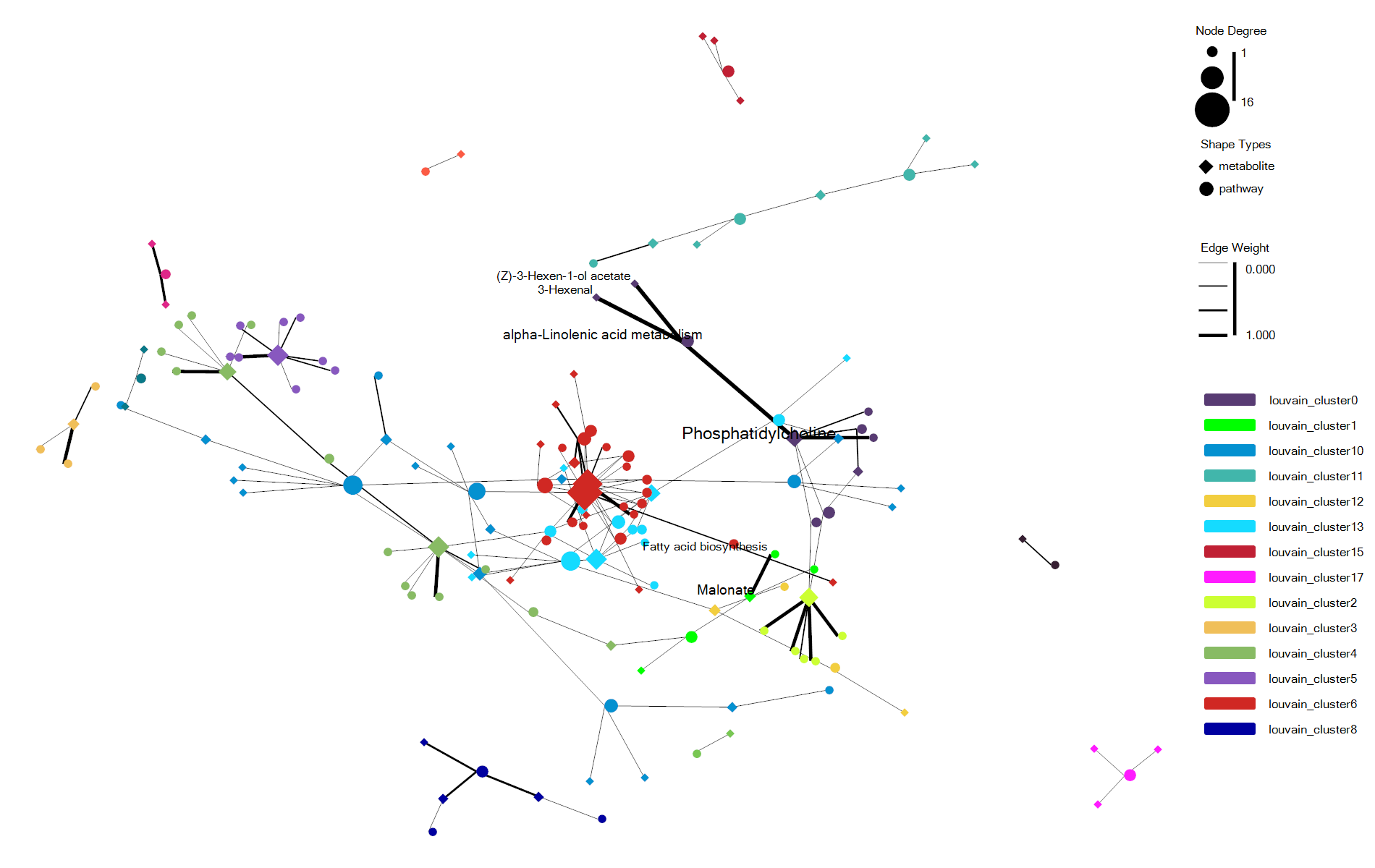
估计阅读时长: 7 分钟https://github.com/rsharp-lang/ggplot 在进行复杂关系的数据集进行可视化的时候,通过网络图的方式进行数据可视化可以让我们非常直观的借助于网络节点的聚集程度之类的布局信息了解到我们的复杂数据的关系结构信息。最近将R#语言之中的ggplot包进行网络可视化的代码库进行了一些更新。基于此功能更新工作,目前在ggplot程序包之中成功集成了ggraph程序包类似的网络可视化功能。在这里做了一些总结分享给大家。 Order by Date Name Attachments enrichNetwork_ggraph • 70 kB • 960 click 2022年6月1日enrichNetwork_ggraph2 • […]
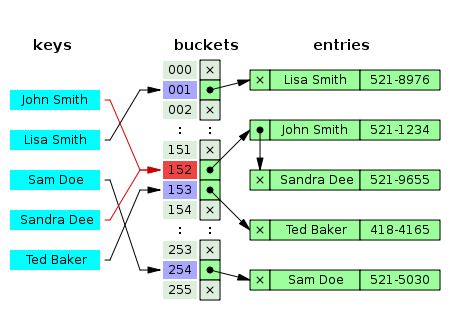
估计阅读时长: 8 分钟在之前的BioDeep代谢物数据库整合工作之中,所提取的代谢物注释信息的唯一编码是来自于数据库表之中的递增主键。由于数据库之中的递增主键的唯一编码值是与数据内容完全无关的数据,所以在基于图数据库做数据库整合的结果在两次整合操作之后,可能会因为先后输出顺序不一致的原因,得到的在关系型数据库中的唯一递增编号可能会完全不一样了。这个问题会对数据库更新操作造成非常大的困扰。 Order by Date Name Attachments 450px-Hash_table_5_0_1_1_1_1_1_LL • 26 kB • 914 click 2022年4月16日metadata-table • 58 […]
估计阅读时长: 5 分钟目前我们根据质谱数据进行代谢物ROI注释分析,很大一部分的工作是建立在已经可以被纯化的化合物的纯标准品所建立的标准品库数据的比对操作之上的。但是依赖于质谱参考谱图数据库所完成的代谢物注释分析,也仅能够得到很小的一部分结果,因为能够纯化或者合成的化合物在整个自然界中目前只占比较小的一部分。并且购买标准品也会需要耗费大量的实验室资金预算。 Order by Date Name Attachments The-Periodic-Table • 2 MB • 1028 click 2022年3月20日Leucine[M+H]+ • 33 […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?