
估计阅读时长: 30 分钟https://github.com/xieguigang/Moira LBM(格子玻尔兹曼方法)凭借其介观模型特性,在流体模拟领域展现出显著技术优势:其碰撞与迁移过程仅依赖局部数据,天然适配GPU并行计算,CUDA实现可达成10–100倍加速比;处理复杂几何边界时无需生成体网格,通过格点标记固体并配合反弹边界即可高效实现,尤其适用于多孔介质等场景;同时,通过扩展分布函数可灵活耦合多物理场,例如引入温度分布函数模拟传热,或采用伪势模型捕获多相流中的相分离现象。尽管在高速或高粘度流动中存在局限,但通过MRT算法优化及GPU硬件加速,LBM已成为微流动、多孔介质、多相流等复杂流体模拟的理想工具,在航空工程等领域已有成功应用案例,其应用前景持续拓展。 Order by Date Name Attachments frame-00093 • 2 MB • 850 click 2025年8月9日ffmpeg • […]
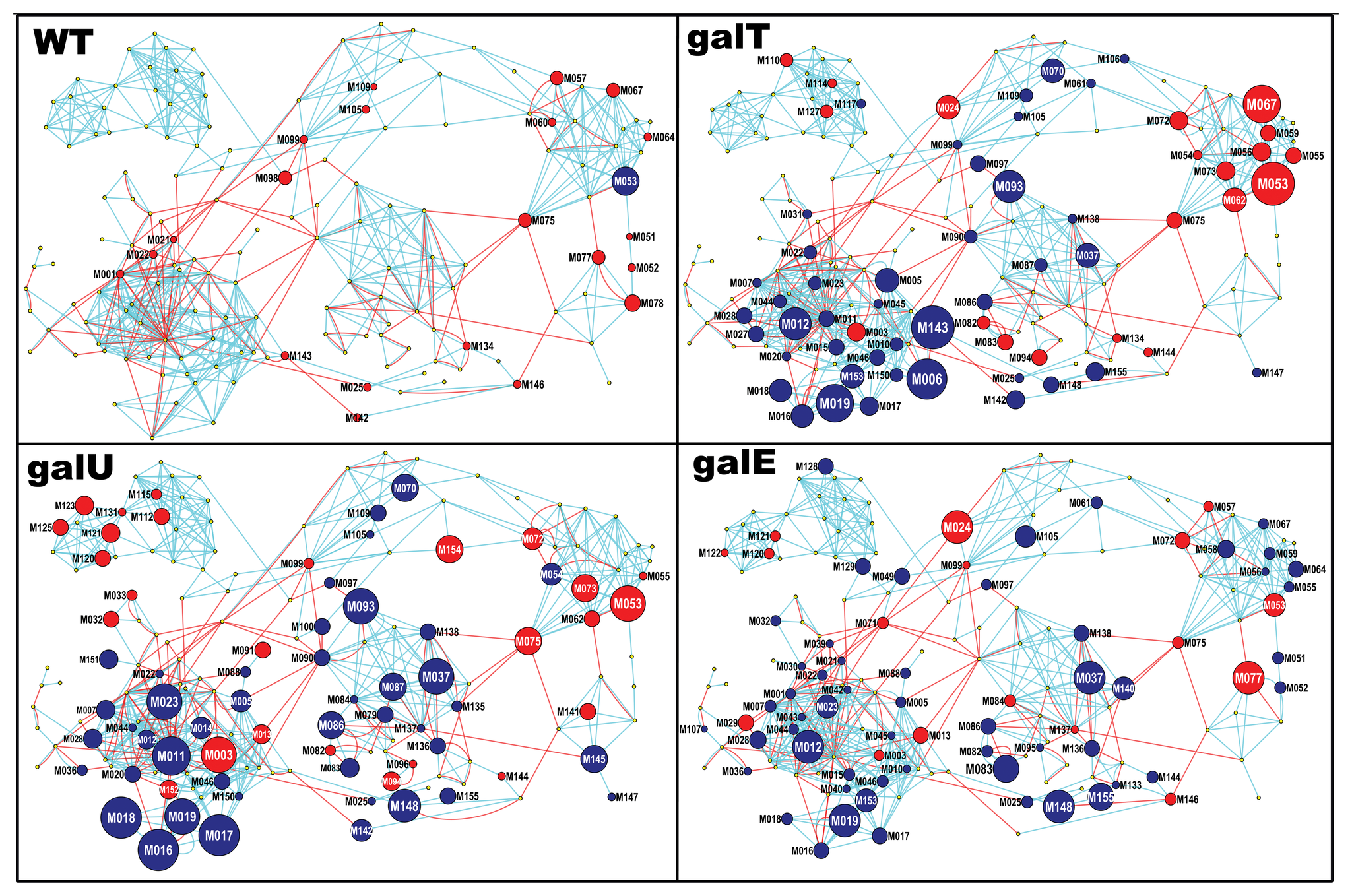
估计阅读时长: 5 分钟在工作之中可能会遇到需要进行两个网络图对象之间的相似度计算的情形:例如在质谱数据分析的化学信息学计算工作之中,我们在解析SMILES字符串得到分子图之后,可以基于图相似度比较计算方法来比较计算两个代谢物分子图之间的结构上的相似度。 Attachments pone.0078360.g003 • 2 MB • 1022 click 2022年8月6日https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0078360

估计阅读时长: 69 分钟Read on CodeProject: https://www.codeproject.com/Articles/5338916/Introducing-Rsharp-language With many years of do scientific computing works by VB.NET language, I'm […]
估计阅读时长: 14 分钟https://github.com/rsharp-lang/ggplot 在完成了前面所提到的ANOVA检验模块的代码开发编写工作之后,之前一直悬在我心里面的完善R#语言的ggplot统计作图功能的愿望现在终于实现了。在R#语言之中通过使用ggplot代码库进行相应的数据统计分析作图,目前已经变得和R语言之中的ggplot2程序包那样同样的简单和漂亮。 Order by Date Name Attachments myeloma_bar • 196 kB • 1077 click 2022年5月29日myeloma_box • […]
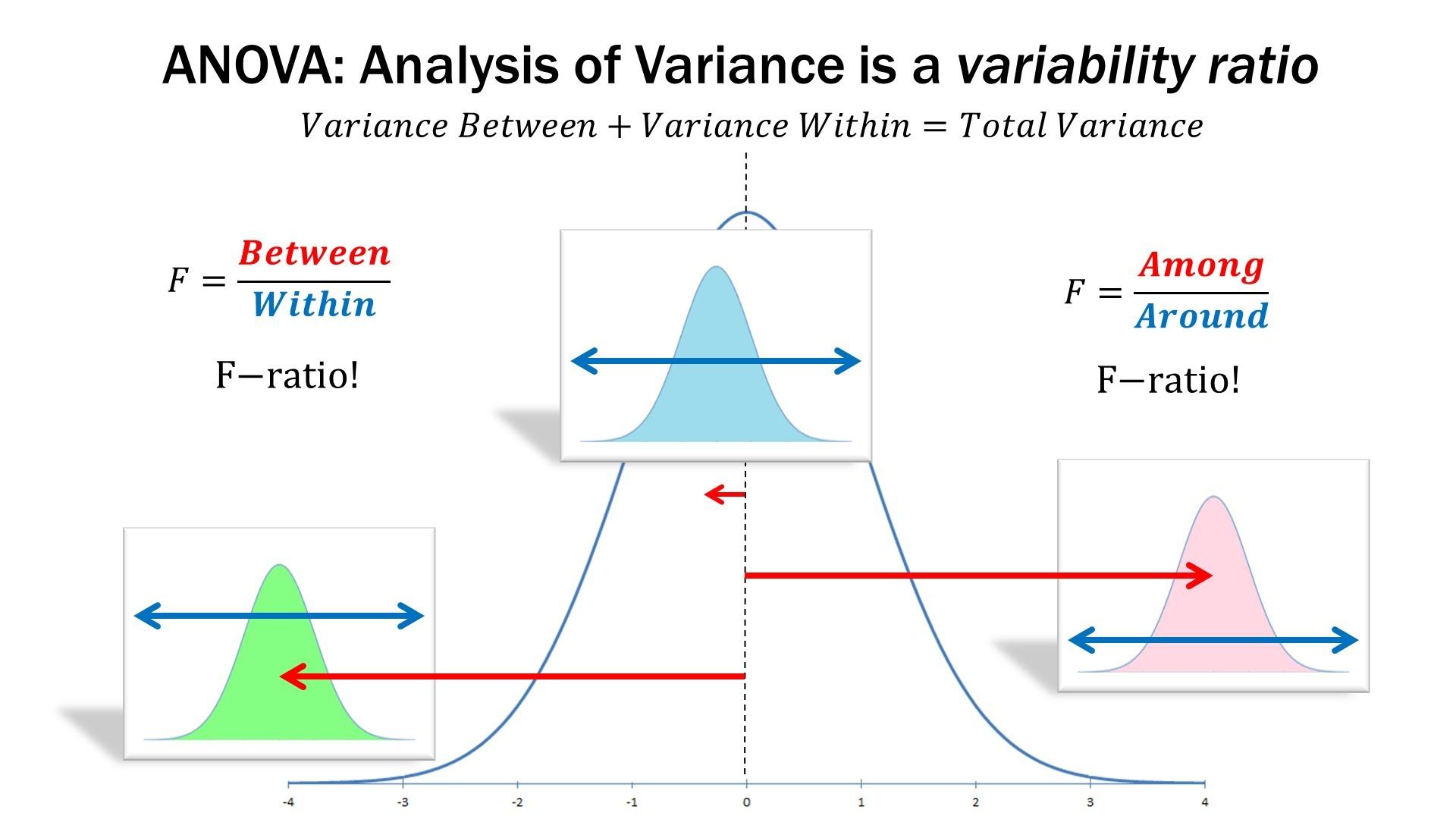
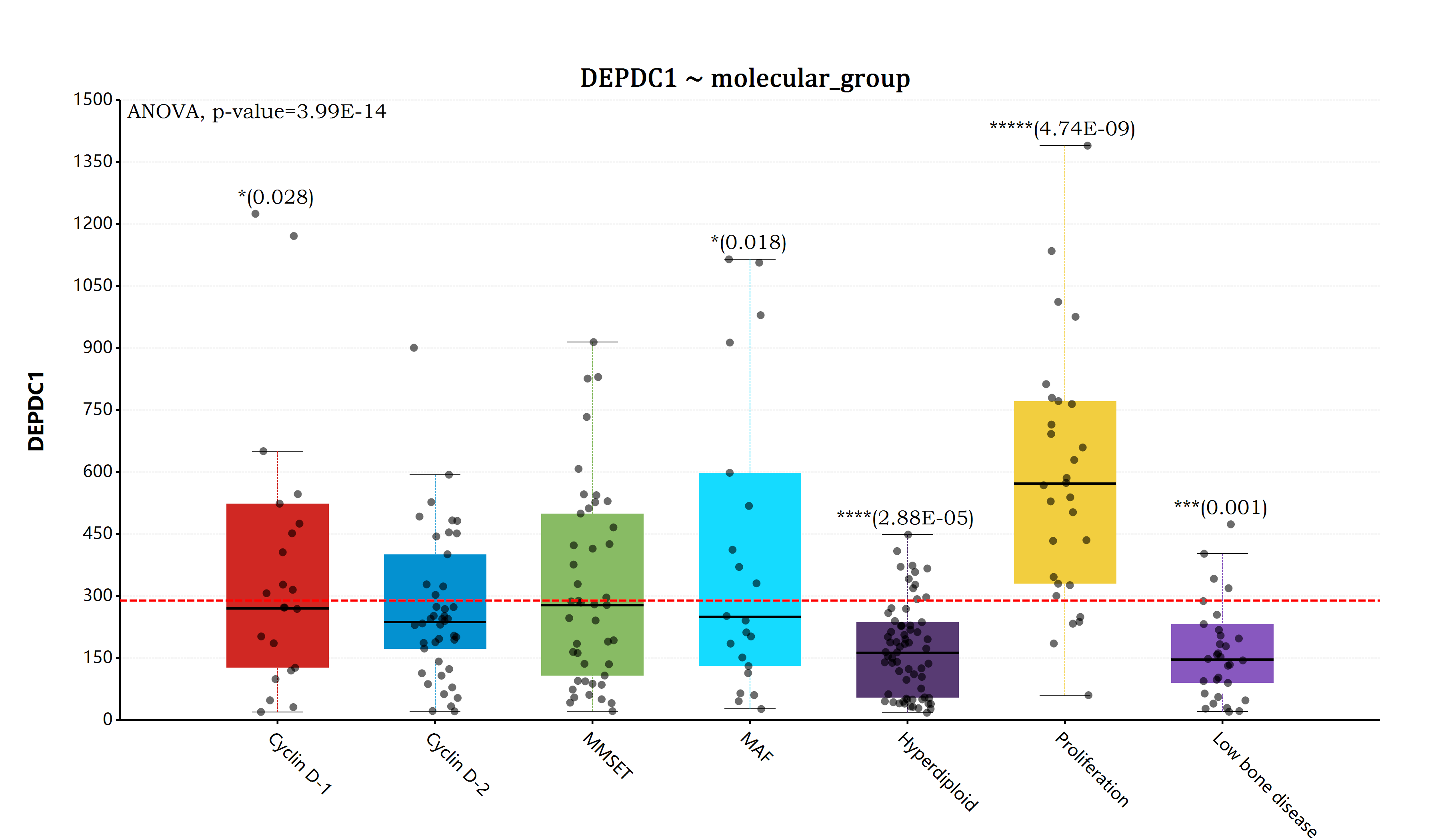
估计阅读时长: 14 分钟一般而言,如果我们在进行组学数据分析的时候,如果想要比较两组数据之间是否存在有差异性,一般是对两两比较的两组数据进行T-检验。但是在代谢组学数据分析领域内,则很多的组学数据分析情况为比较两组以上的数据,寻找差异的biomarker。那这个时候就需要使用上ANOVA统计检验方法了。 Order by Date Name Attachments anova • 105 kB • 1228 click 2022年5月28日ANOVA-screen • 27 […]
估计阅读时长: 7 分钟F统计量是群体遗传学中由Sewall Wright提出的重要统计量,用于衡量遗传变异在群体中的分布情况。它提供了对群体遗传结构和遗传分化的定量描述。F统计量主要有三种类型:Fis、Fit和Fst,分别反映个体内的、总体的和群体间的遗传分化。F统计量在群体遗传学中通常指的是Fst(Fixation Index,固定指数),它是一个衡量群体间遗传差异的指标。Fst的值范围从0到1,其中0表示群体间没有差异,1表示群体间完全分离。在群体遗传学研究中,Fst常用于评估群体的遗传多样性、群体间的迁移率以及自然选择的压力等。 Order by Date Name Attachments 41598_2021_92984_Fig1_HTML • 2 MB • 1035 click 2022年5月28日p1 […]
估计阅读时长: 5 分钟目前我们根据质谱数据进行代谢物ROI注释分析,很大一部分的工作是建立在已经可以被纯化的化合物的纯标准品所建立的标准品库数据的比对操作之上的。但是依赖于质谱参考谱图数据库所完成的代谢物注释分析,也仅能够得到很小的一部分结果,因为能够纯化或者合成的化合物在整个自然界中目前只占比较小的一部分。并且购买标准品也会需要耗费大量的实验室资金预算。 Order by Date Name Attachments The-Periodic-Table • 2 MB • 1013 click 2022年3月20日Leucine[M+H]+ • 33 […]

估计阅读时长: 10 分钟https://github.com/xieguigang/ms-imaging Order by Date Name Attachments HR2MSI_mouse_urinary_bladder_S096_RGB • 7 MB • 1057 click 2021年11月13日peerj-cs-07-585 • 16 […]
估计阅读时长: 17 分钟https://github.com/xieguigang/sciBASIC/tree/master/gr/Microsoft.VisualBasic.Imaging/Drawing3D 因为大家大多数都是从小接受电子游戏,所以长大了之后能够自己从零开始开发一个完整的3维图形引擎是每一个男程序员的梦想。这个就像玩机械的男人的梦想就是自己从头开始组装一辆汽车。还好这个梦想我在几年前就已经实现了。 Order by Date Name Attachments Cube3D_VB.NET • 4 MB • 1070 click 2021年9月19日Cube_screenshot • […]
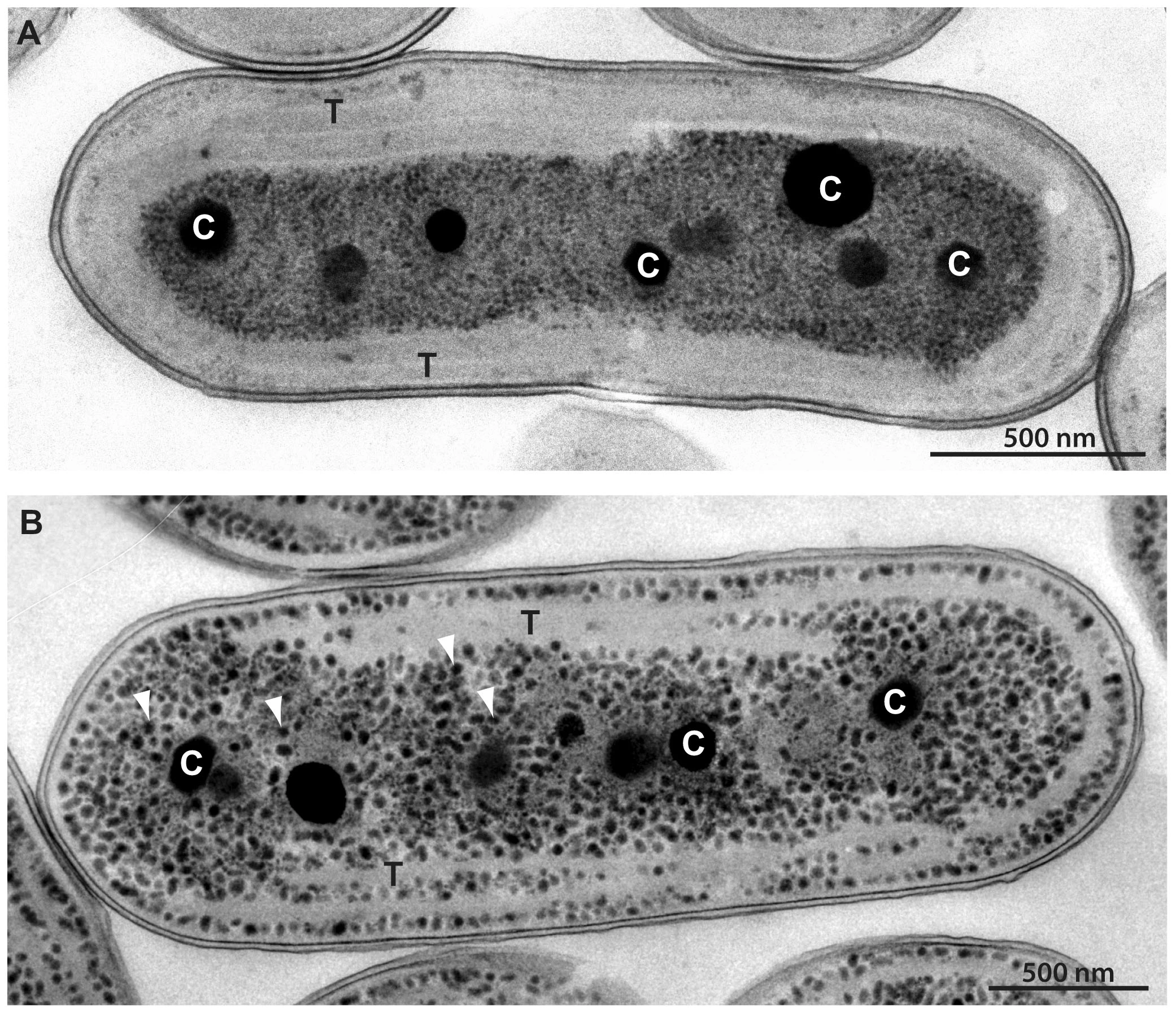
估计阅读时长: 10 分钟https://gcmodeller.org/ 流平衡分析(flux balance analysis)是一种可以用来构建和模拟分析基因组级别的代谢网络的数学方法。流平衡分析是系统生物学(system biology)的一个重要的分析手段。不同于以湿实验的代谢通量分析(metabolic flux analysis, MFA),FBA是用数学方法对代谢网络里的代谢流进行拟合分析。 Order by Date Name Attachments Electron micrographs of […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?