
估计阅读时长: 6 分钟之前在阅读一个使用rust语言编写的contour tracing算法模块的源代码的时候,其中有一个向量的左旋以及右旋的操作。这个操作的具体的含义是和在算法中的轮廓边缘像素的读取方向有关:因为访问方向是一个二维平面的概念,但是在代码中我们只能够使用一个一维的数组的来存储这个二维的信息。所以在这段rust代码之中,作者很巧妙的使用了向量的左旋以及右旋操作来实现一维数组中对二维平面上的方位的访问操作。 Order by Date Name Attachments RotateVector • 30 kB • 809 click 2021年9月16日Full • […]
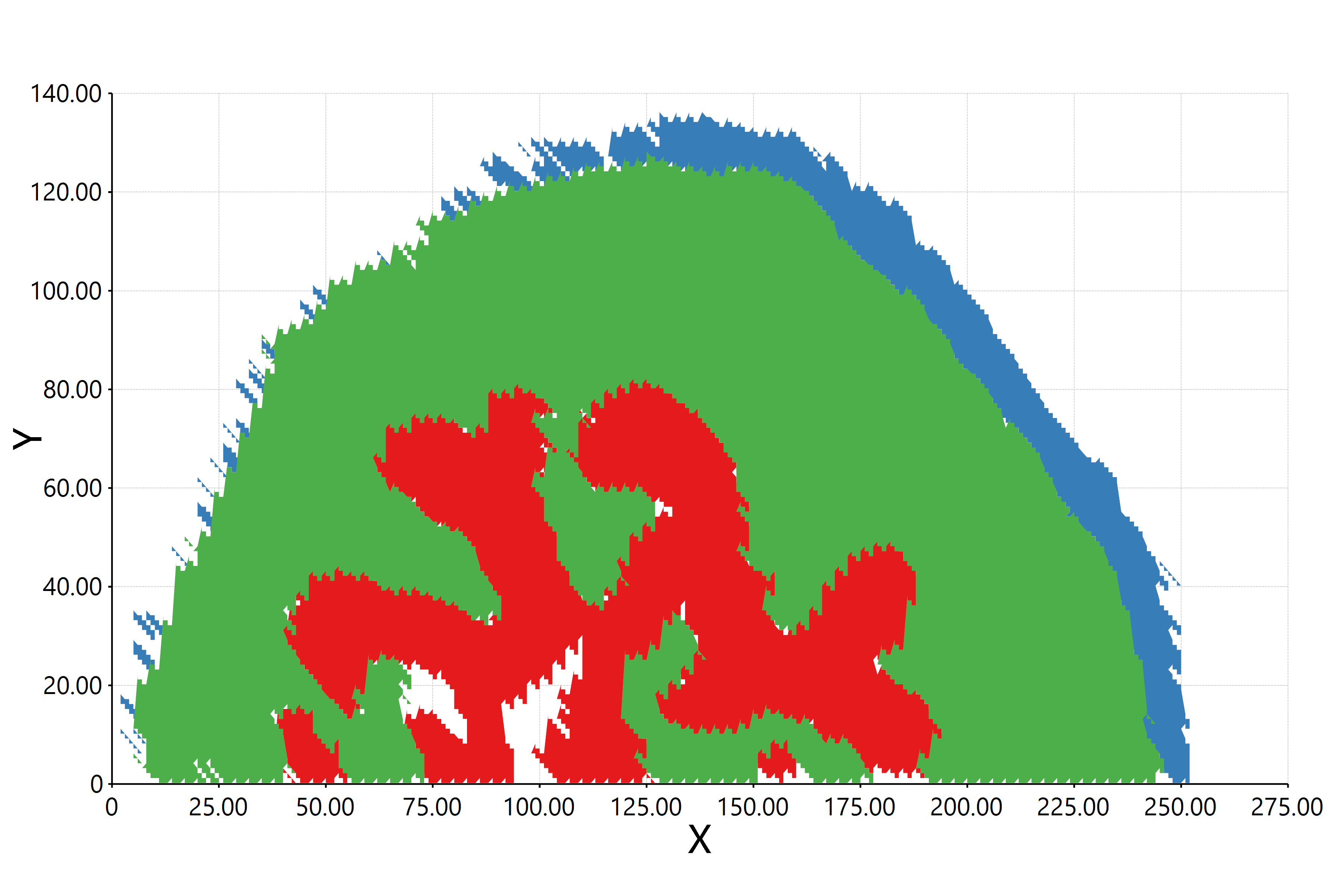
估计阅读时长: 11 分钟https://github.com/xieguigang/sciBASIC 最近在研究实现空间代谢组学中的一些特征区域的自动化划分分割。在得到了特征点集合之后,我们需要根据一些图像处理算法进行特征区域的提取操作。之前,我们尝试过基于绘制等高线图Marching Squares算法的方式来将特征点集合自动转换为特征区域的多边形,实现轮廓扫描获取的功能。但是实现的效果嘛,和实际的区域存在着一些较大的差异。 Order by Date Name Attachments HR2MSI mouse urinary bladder S096 - spatial regions […]

估计阅读时长: 15 分钟https://github.com/xieguigang/sciBASIC 最近在空间代谢组学中的质谱成像应用开发过程中,会需要使用到一些图像处理算法对原始的质谱成像结果图片进行诸如平滑,放大等处理。顺着图像平滑的算法搜索,通过搜索引擎找到了一个年代比较久远的图像处理算法博客文章,将其中的图像算法重新实现了一下,在这里分享给大家。 Order by Date Name Attachments lena • 558 kB • 749 click 2021年9月10日lenalena • […]
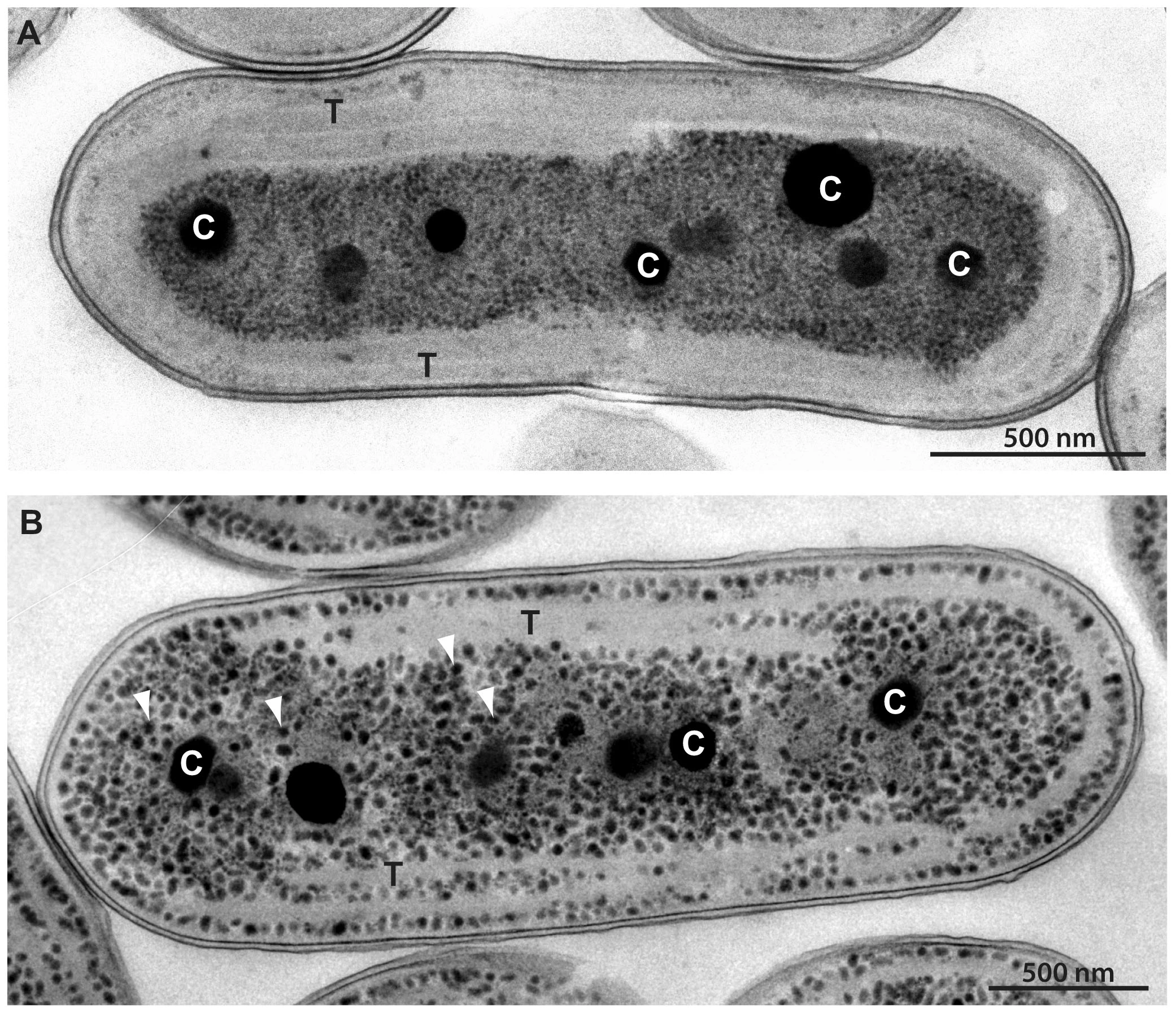
估计阅读时长: 10 分钟https://gcmodeller.org/ 流平衡分析(flux balance analysis)是一种可以用来构建和模拟分析基因组级别的代谢网络的数学方法。流平衡分析是系统生物学(system biology)的一个重要的分析手段。不同于以湿实验的代谢通量分析(metabolic flux analysis, MFA),FBA是用数学方法对代谢网络里的代谢流进行拟合分析。 Order by Date Name Attachments Electron micrographs of […]
估计阅读时长: 9 分钟https://github.com/xieguigang/sciBASIC 在实际应用的机器学习方法里,GradientTree Boosting (GBDT)是一个在很多应用里都很出彩的技术。XGBoost是一套提升树可扩展的机器学习系统。XGBoost全名叫(eXtreme Gradient Boosting)极端梯度提升。它是大规模并行boosted tree的工具,XGBoost 所应用的算法就是 GBDT(gradient boosting decision tree)的改进,既可以用于分类也可以用于回归问题中。 Order by Date Name […]
估计阅读时长: 7 分钟https://github.com/rsharp-lang/bing-academic 我们在进行一个新的课题项目开始之前,会需要经历过一个开题立项的报告过程。在这个过程之中,我们需要收集与课题相关的信息,例如相关的知识背景信息,建立出一个与课题相关的知识网络。基于此知识网络进行课题的技术相关概念的梳理。 Order by Date Name Attachments v2-8119594eef2838042df8fb5af0523c0c_720w • 126 kB • 836 click 2021年8月15日v2-96d82f034d4084cf1ed6eb4784f36ed4_r • […]
估计阅读时长: 9 分钟https://github.com/rsharp-lang/bing-academic 必应学术是由微软必应团队联合微软研究院打造的免费学术搜索产品。旨在为广大研究人员提供海量的学术资源,并提供智能的语义搜索服务。目前已涵盖多学科学术论文、国际会议、权威期刊、知名学者等方面。搜索位置:http://cn.bing.com/academic。 Order by Date Name Attachments Bing_Logo • 14 kB • 726 click 2021年8月14日html-compression • […]
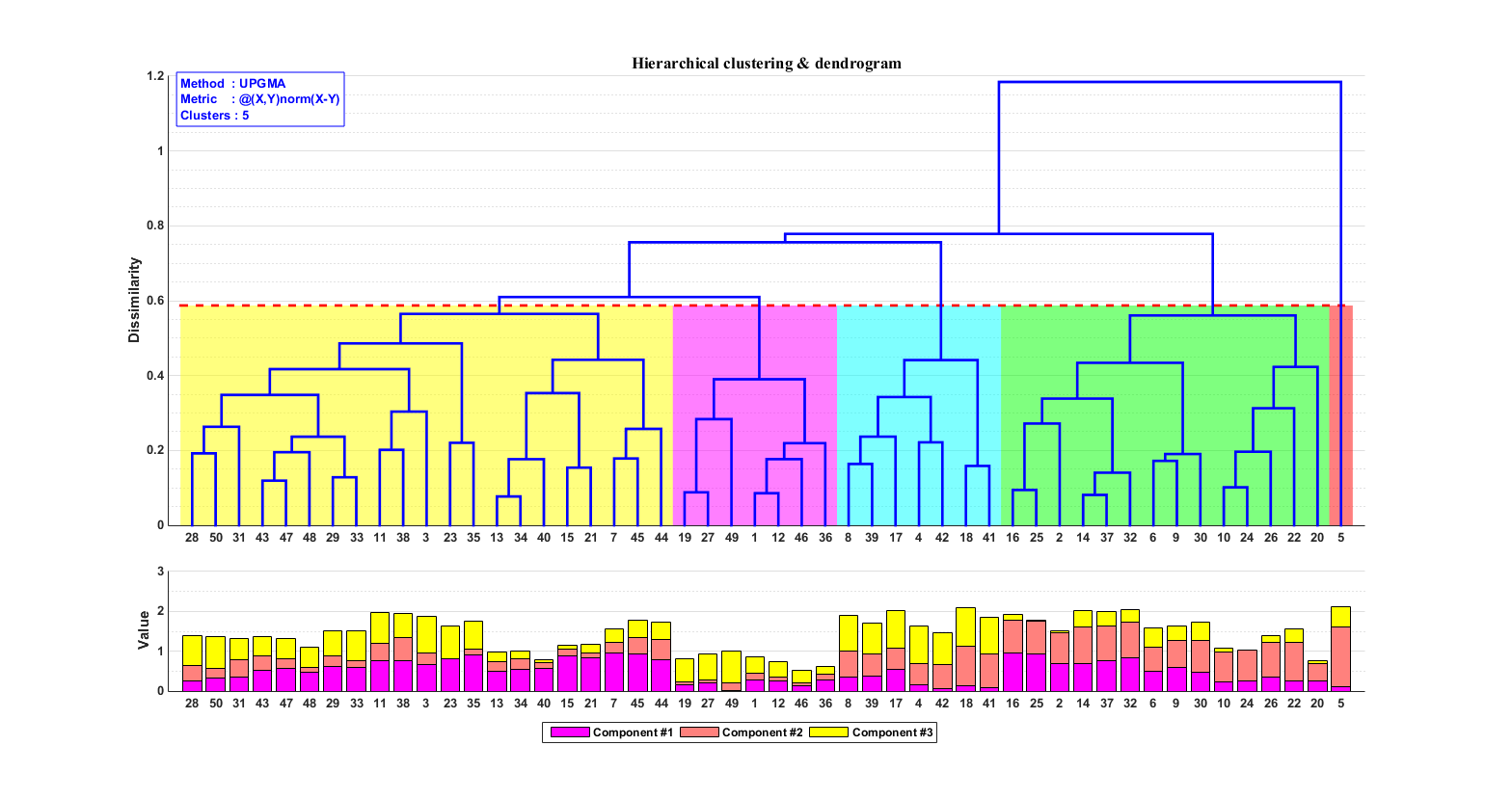
估计阅读时长: 14 分钟https://github.com/xieguigang/sciBASIC 层次聚类通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。基于层次聚类分析,我们可以初步可视化我们的一些原始数据: 例如对样本的层次聚类分类,可以让我们了解到样本在分组之间以及分组内的异质性。 对生物序列进行基于相似度的层次聚类分析,我们可以了解到序列之间的相似性程度或者进化关系 Order by Date Name Attachments metabolome • 14 kB • 849 click […]
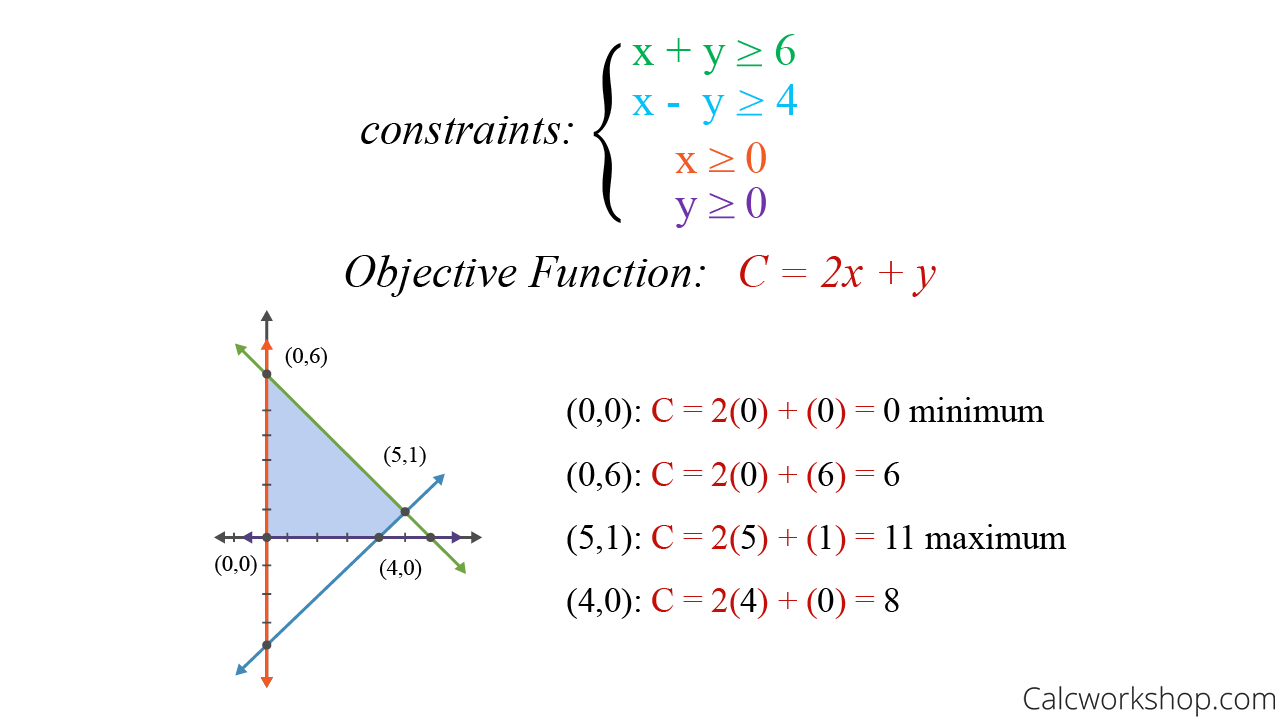
估计阅读时长: 30 分钟https://github.com/xieguigang/sciBASIC/ 线性规划(Linear programming,简称LP)方法起源于20世纪40年代,由美国数学家乔治·丹齐格(George Dantzig)提出,并设计了著名的“单纯形法”。这种优化算法是运筹学中研究较早、发展较快、应用广泛、方法较成熟的一个重要分支,它是辅助人们进行科学管理的一种数学方法。研究线性约束条件下线性目标函数的极值问题的数学理论和方法。通俗点的来讲,就是我们基于这一种数学优化技术,用于在一组线性约束条件下,求解线性目标函数的最大值或最小值(就是在“有限资源”和“一定规则”下,找到“最佳方案”的一种方法)。 Order by Date Name Attachments linear-programming-example • 22 kB • 891 click […]
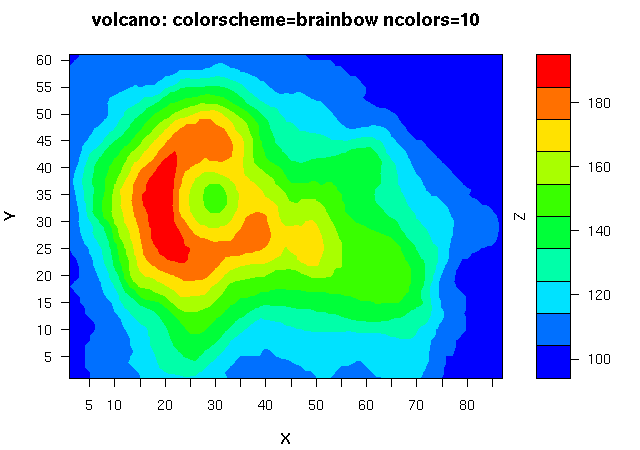
估计阅读时长: 16 分钟https://github.com/xieguigang/sciBASIC 等高线指的是地形图上高程相等的相邻各点所连成的闭合曲线。把地面上海拔高度相同的点连成的闭合曲线,并垂直投影到一个水平面上,并按比例缩绘在图纸上,就得到等高线。 Order by Date Name Attachments 1_Contour • 487 kB • 990 click 2021年6月30日Ms1Contour • […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?