
文章阅读目录大纲
 https://github.com/rsharp-lang/bing-academic
https://github.com/rsharp-lang/bing-academic
我们在进行一个新的课题项目开始之前,会需要经历过一个开题立项的报告过程。在这个过程之中,我们需要收集与课题相关的信息,例如相关的知识背景信息,建立出一个与课题相关的知识网络。基于此知识网络进行课题的技术相关概念的梳理。
接我的上一篇博客文章,我们学习到了如何基于GraphQuery进行必应学术搜索的查询解析。那在这里,我们将会了解到如何基于上一篇文章中的GraphQuery查询结果的基础上进行知识网络的建立。
知识网络可视化
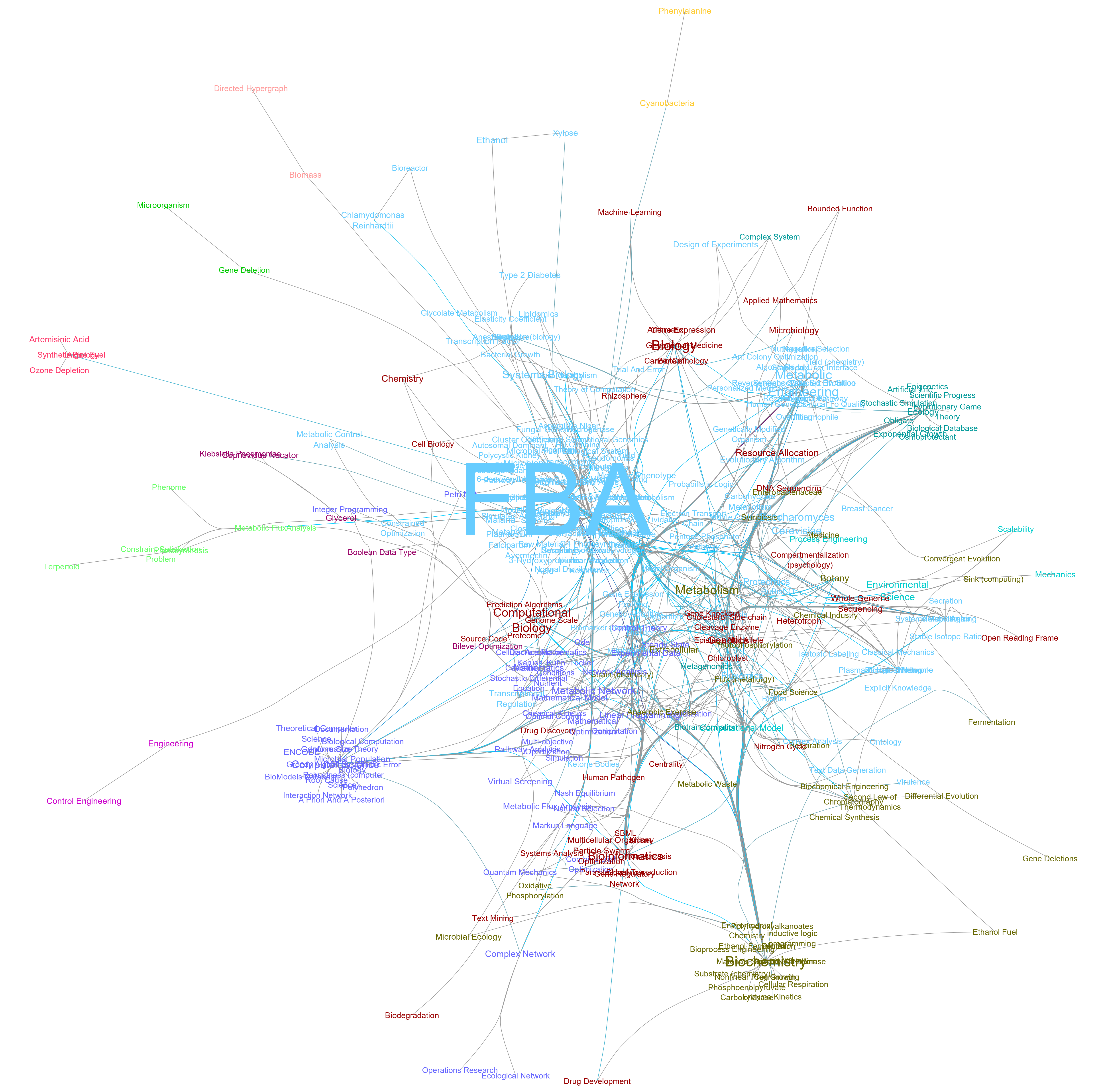
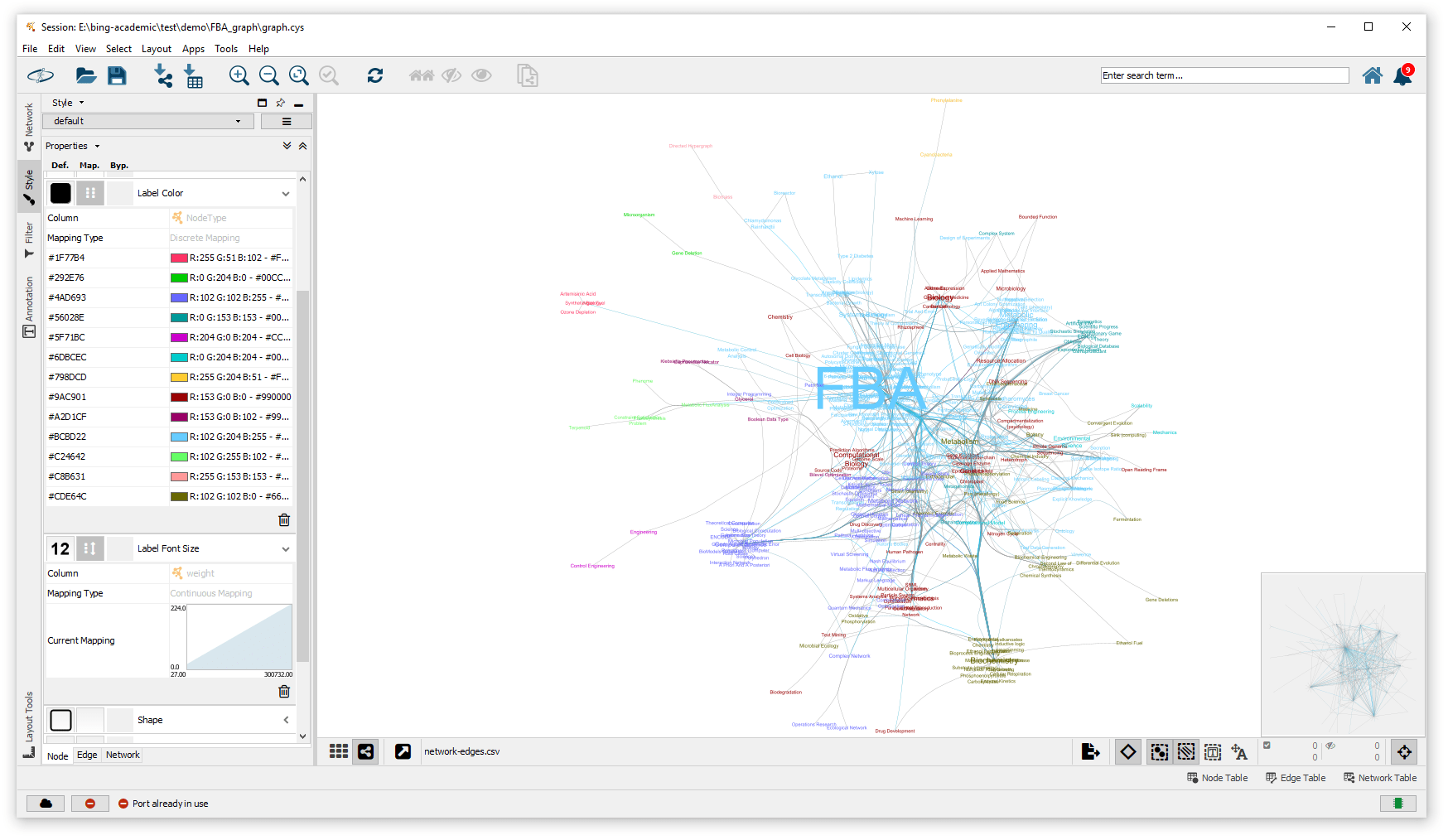
在这里我基于FBA(Flux Balance Analysis)文献查询结果来进行知识网络的建立。通过Cytoscape进行网络的可视化分析。首先在最开始给大家展示一下得到的知识网络的可视化结果。
通过上面的知识网络可视化图我们可以看得出来:由于我们查询的关键词就是FBA这个单词,所以在得到的所有文献中,FBA是我们所建立的知识网络中的绝对重点关键词。通过上面的网络图我们还可以看得到一些与FBA分析关联很紧密的代谢优化关键词,例如:Biochemistry,Bioinformatics,Metabolism,Metabolic Engineering,Computational Biology。
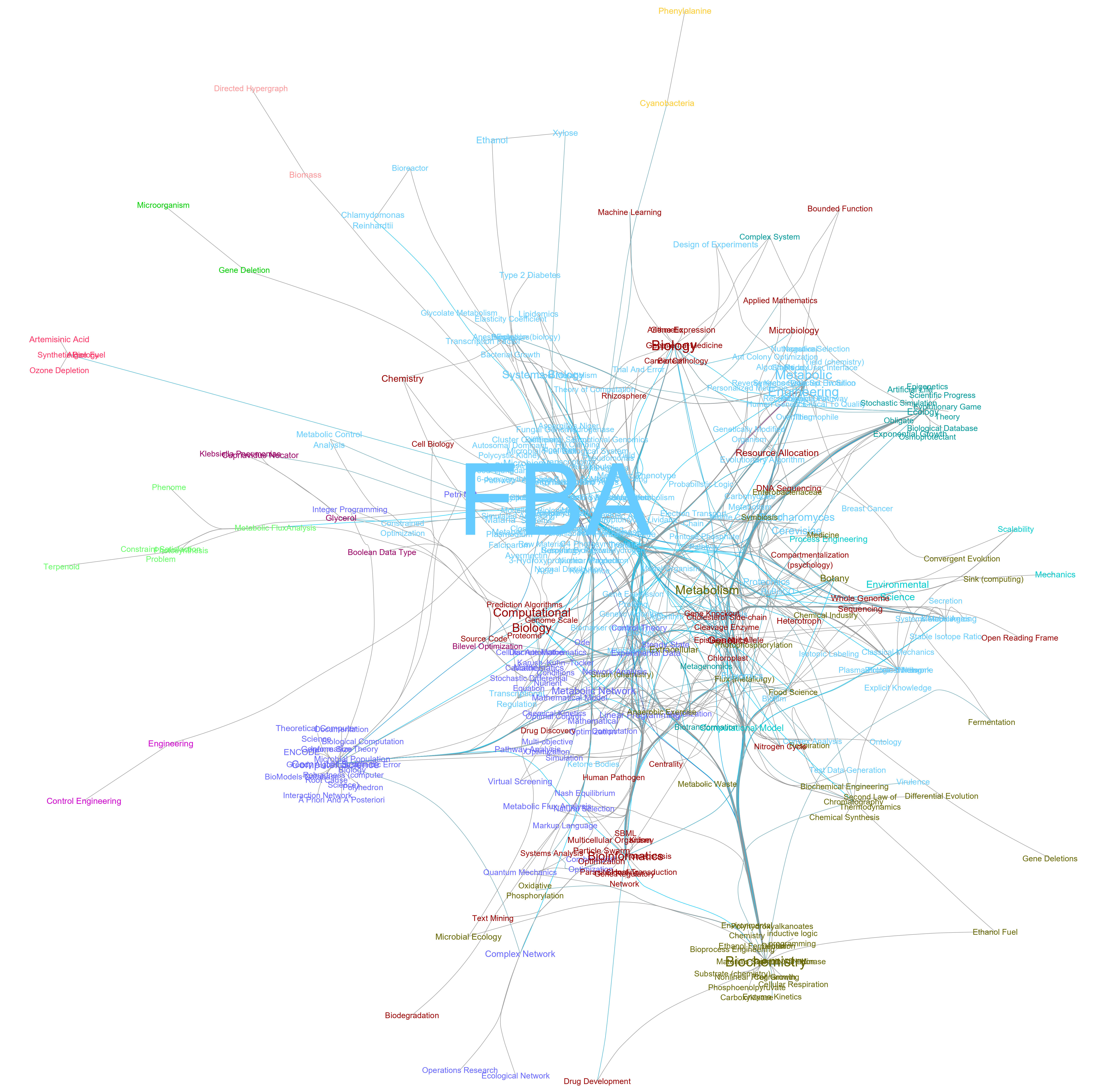
知识网络局部信息展示
可以看得出来,由于FBA方法是用于解决代谢优化相关的问题。所以对于FBA分析的研究一般会涉及到很多的生物化学系统的概念。所以在我们的知识网络可视化结果之中,可以看得到Biochemistry有着很大的相关性可视化结果。

同时,由于进行FBA分析,会需要用到一系列的计算方法来完成整个分析过程,例如:代谢网络建模,系统方程建模,线性规划求解等计算算法。所以与FBA相关的知识之中,计算生物学的概念也占着很大的一部分比重。有趣的是,我们还发现了与药物研发相关的FBA研究的知识点,例如Drug Discover, Virtual Screening。推测FBA与药物研发相关的问题可能是通过药物对代谢网路的扰动这方面的观点来进行分析的。
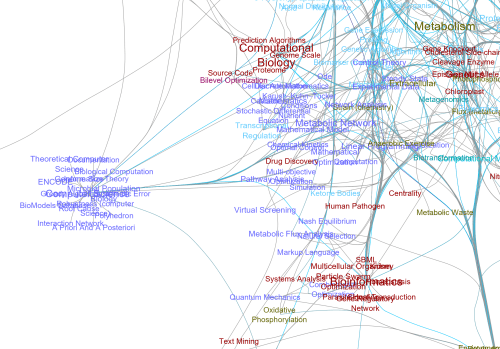
由于FBA方法也是一种常用的代谢工程优化算法,所以我们也看到了在FBA方法相关的研究中,Metabolic Engineering相关的概念也展现了很大的比重。基于FBA方法进行代谢工程优化,可以看到的相关知识点就是通过建立Genetically Modification来实现代谢网络的修正,之后进行FBA方法预测代谢网络的修正效果。

R#脚本代码构建知识网络
现在大家是不是对于亲自建立自己的研究的知识网络拳拳欲试了呢?下面就来详细的讲解基于R#脚本建立知识网络的过程吧。首先我们需要有相关的知识数据,知识数据我们可以通过上一篇博客文章中了解到的必应学术查询来完成:

通过对必应学术查询相关的知识点,我们可以整理得到一系列的查询结果用于后续的知识网络的构建。在开始讲解代码之前,我们先来看一些知识数据的基本组成结构是怎样的:
{
"guid": "f90f3af810bb9e282720a8ec86bc2726",
"title": "What is flux balance analysis",
"authors": [
{"name": "Jeffrey D Orth", "guid": "2129044226"},
{"name": "Ines Thiele", "guid": "2015971504"},
{"name": "Bernhard O Palsson", "guid": "2068736320"}
],
"year": "2010",
"journal": "· Nature Biotechnology",
"cites": 2885,
"abstract": "Flux balance analysis is a mathematical approach for analyzing the flow of metabolites through a metabolic network. This primer covers the theoretical basis of the approach, several practical examples …",
"keywords": [
{"word": "Flow (psychology)", "guid": "75673492"},
{"word": "Biology", "guid": "86803240"},
{"word": "Flux Balance Analysis", "guid": "167091322"}
]
}首先,我们能需要使用相应的函数来处理知识信息的IO读取,因为信息文件是JSON格式的,所以我们会需要使用到JSON包做解析操作。在这里遍历出所有json文件之后做json字符串解析,完成加载知识库数据:
require(JSON);
const loading = list.files(`${dirname(@script)}/FBA`, pattern = "*.json")
|> lapply(function(path) {
json_decode(readText(path))
})
;接着呢,就是基于单篇论文的关键词信息进行网络的建立了。在这里我们将同一篇文献中出现的关键词都连为一条线的方式构建出网络,使用文献的引用总数作为文献对应的关键词的权重数据用来映射关键词在网络可视化中的标签文本大小:
require(igraph);
const g = empty.network();
const pushWordVertex as function(word, cites) {
if (length(g |> getElementByID(word)) == 0) {
g :> add.node(label = word);
}
mass(g, word) = {
const node = g |> getElementByID(word);
const ndata = as.object(as.object(node)$data);
ndata$mass + ifelse(cites == 0, 1, cites);
}
}
const pushArticle as function(article) {
const words as string = sapply(article$keywords, w -> w$word);
const cites as integer = as.integer(article$cites);
const firstWord as string = splitKeyword(words[1]);
print(article$title);
pushWordVertex(firstWord, cites);
for(word in words[2:length(words)]) {
word = splitKeyword(word);
pushWordVertex(word, cites);
if (!(g |> has.edge(firstWord, word))) {
g |> add.edge(firstWord, word);
}
g |> weight(firstWord, word, g |> weight(firstWord, word) + 1);
}
}上面所的代码所描述的知识网络的建立过程就是:假设一篇相关的文章中,有关键词列表A,B和C,那么我们就可以建立网络连接:A - B以及B - C。通过不断地遍历整个知识库,那么我们就可以基于上面的关键词列表连接关系建立起整个知识网络信息。
因为文章的引用数量可能相差非常大,这个导致相关的关键词的权重的差异会非常大,所以我们在这里通过分位数进行一下权重的调整限制,使网络可视化的结果更加优雅一些:
const q = quantile(unlist(mass(g)));
const i as boolean = unlist(mass(g)) < q[["50%"]];
const j as boolean = unlist(mass(g)) > q[["75%"]];
print("Words of cites count less than 50% quantile:");
print(sum(i));
print("Words of cites count greater than 75% quantile:");
print(sum(j));
mass(g, NULL) = lapply(mass(g), x -> ifelse(x < q[["50%"]], q[["50%"]], x));最后呢,基于louvain算法对我们的知识网络做一下分区处理,将相关的知识点分成不同的分组方便进行理解。完成分组之后,通过save.network函数保存一下结果网络即可:
g
|> connected_graph
|> louvain_cluster
|> (function(g) {
# set node color by class
class(g) = colors("scibasic.category31()", length(unique(class(g))), character = TRUE)[factor(class(g))];
g;
})
|> save.network(`${dirname(@script)}/FBA_graph/`)
;Cytoscape软件可视化
在终端中通过R#
接着呢,我们就只需要将得到的两个结果表格导入到Cytoscape程序软件之中生成网络图,输出调整过样式的网络可视化图即可。
可以从这里下载DEMO网络可视化文件:FBA_graph.zip
- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

One response
[…] FBA分析的一些相关知识库信息的建立,大家可以阅读之前写的两篇博客文章:《数据可视化】基于必应学术搜索的知识网络可视化》和《GraphQuery】使用GraphQuery查询必应学术》 […]