
文章阅读目录大纲
 https://mzkit.org/
https://mzkit.org/
代谢组文章整个坎坷的发表经历中,大家可能都会遇到的一个老大难问题就是我们有时候会需要从原始数据中得到物质注释结果的二级质谱图数据。对于熟悉xcms程序包的同学,获取二级质谱图可能会比较容易:无非就是加载原始数据,然后按照m/z和rt找到对应的二级scan就好了。但是,这种方法会需要编写脚本来完成。
对于更多的老师同学而言,我们则更希望可以通过鼠标点击的方式就可以得到二级质谱图。正好这里就有一款代谢组学原始数据查看利器mzkit可以介绍个大家。
就像我们将大象装进冰箱里面需要经过打开冰箱,把大象放进冰箱,关上冰箱门这三个步骤一样。在mzkit程序之中,得到一个二级质谱图原始数据,我们也只需要经过三个步骤:
- 打开原始数据文件
- 选择目标离子
- 导出质谱图信息
下面,我就来为大家细细道来:
打开原始数据文件
首先我们需要找到软件左上角的Ribbon菜单中的一个黄色的文件夹按钮。就在左上角的位置,很显眼的:

然后点击它,之后就会弹出一个文件对话框,让我们选择需要进行查看的目标原始数据文件:

在mzkit软件之中,几乎支持所有主流的开源原始数据文件格式,以及赛默飞的Raw文件,还有一个就是诺米代谢我们自家的mzPack原始数据文件。在这里,我们选择一个mzML格式的原始数据文件,然后点确定打开这个文件。
对于raw文件和mzPack原始数据文件,因为是二进制文件,一般可以立马被打开。对于mzXML/mzML文件,则会需要等一会时间等mzkit程序加载完原始数据。

嗯嗯嗯,在导入了这个mzML格式的原始数据文件之后,我们在文件浏览器【File Explorer】中,可以看到我们的文件已经出现在文件树里面了。我们可以直接在目标文件上通过右键菜单,查看BPC/TIC色谱图:
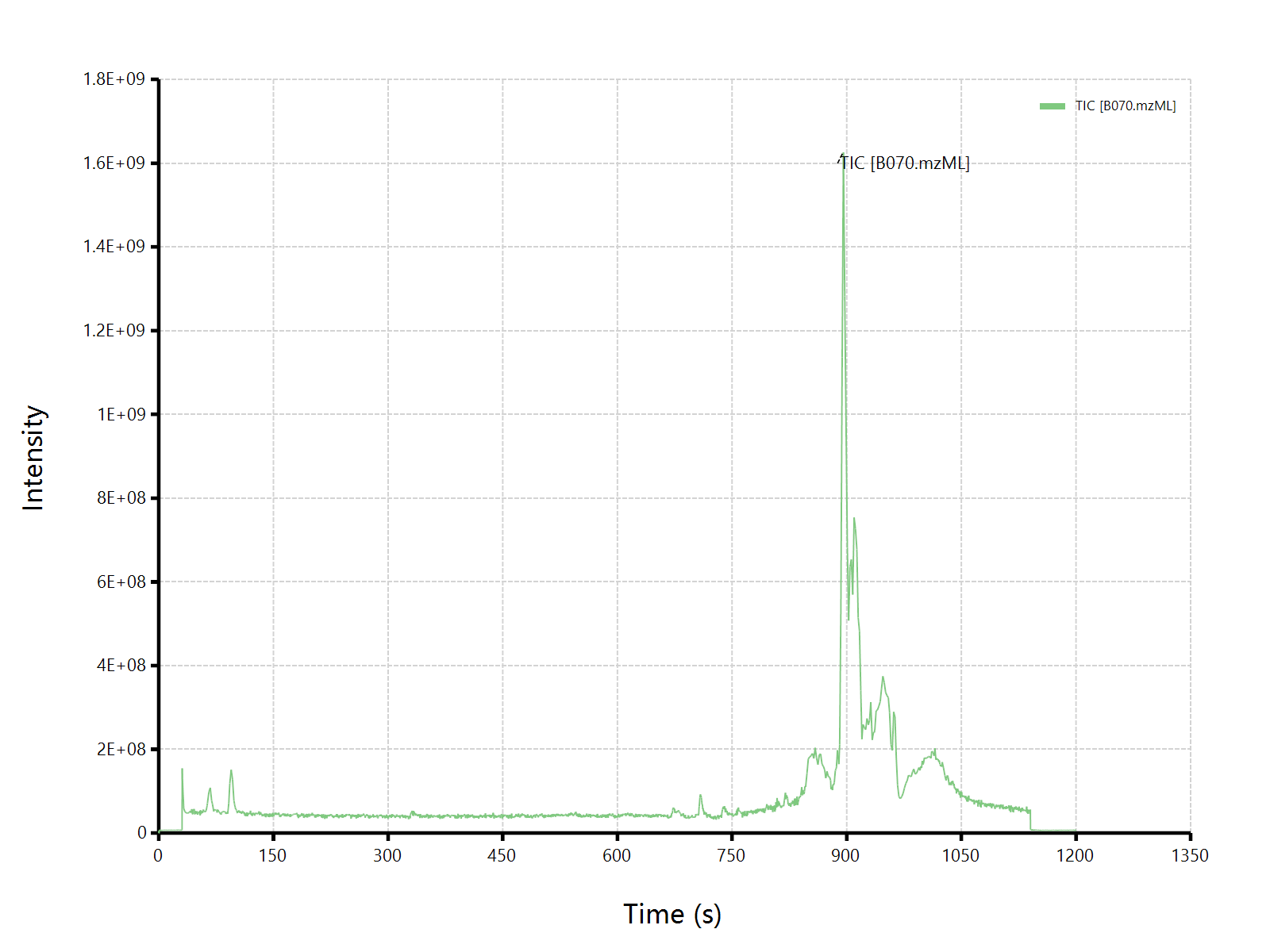
TIC色谱图是将每一个scan时间点上的所有离子的响应度加起来的总和对保留时间作图。BPC色谱图的话,则是每一个scan中最高的信号响应度对保留时间作图。
选择目标离子
我们在文件浏览器中选中我们的目标原始数据文件之后,可以在特性浏览器【Features Explorer】中看到原始数据文件中的所有质谱扫描结果都显示出来了。在特性浏览器之中,质谱图数据默认是以扫描树的形式组织在一起的:一级扫描帧会包含有topN离子的二级扫描帧结果。接下来,我们需要通过右键菜单从扫描帧视图切换到离子列表视图。

完成视图切换之后,在我们的原始数据之中,所有的具有二级质谱图的离子都显示出来了。接着呢,我们就可以根据目标m/z找出目标离子就可以啦。

在这里,我们找到一个目标离子,然后可以通过右键菜单显示这个二级质谱图相关的属性:

属性窗口默认是出现在mzkit软件的右边的位置
通过这个窗口我们可以大概的了解到目标离子的一些质谱图信息,例如极性,裂解能量,裂解方式等
导出质谱图信息
在选择好我们的离子之后呢,我们就可以导出目标质谱图的信息了。我们可以在看图的位置点击右键,可以看到有三个Copy菜单可以供我们用来做输出导出:

- Copy Matrix 将质谱图矩阵数据复制到剪切板中
- Copy Plot Image 将二级质谱图可视化结果图片复制到剪切板中
- Copy Properties 将我们上面所展示的质谱图属性信息复制到剪切板中
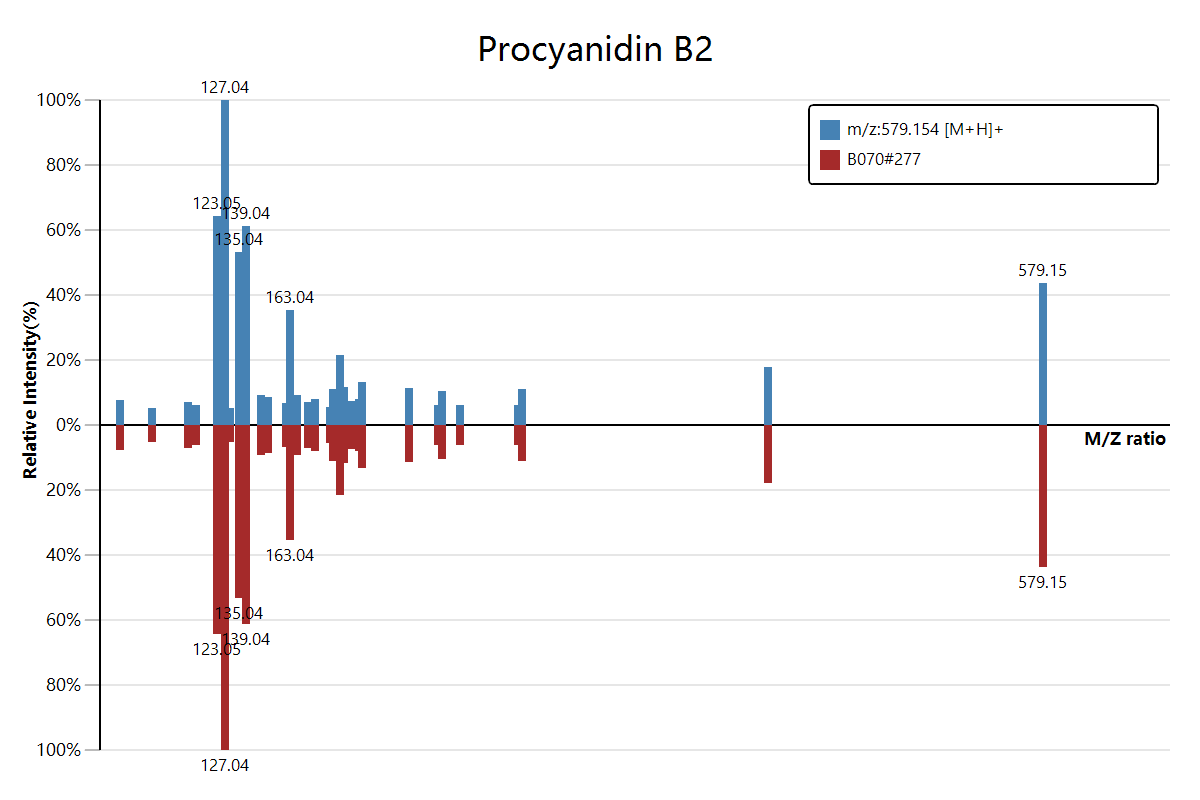
在这里展示一下通过上面的复制菜单直接复制我们的质谱数据到Excel表格中的结果:
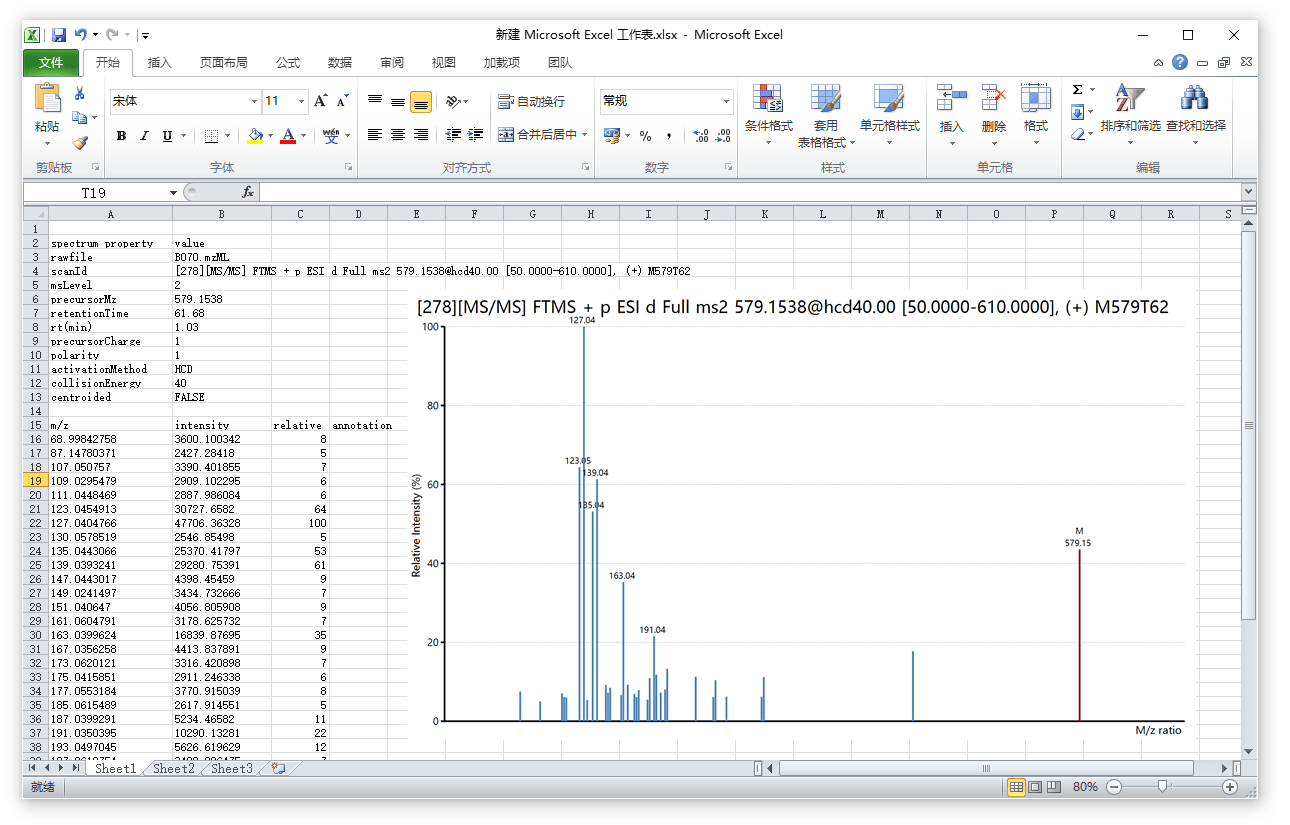
当然,如果各位老师和同学需要保存为文件的话,可以选择【Copy Data】菜单下面的【Export Data】选项用来将结果数据直接保存为文件。
- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

No responses yet