
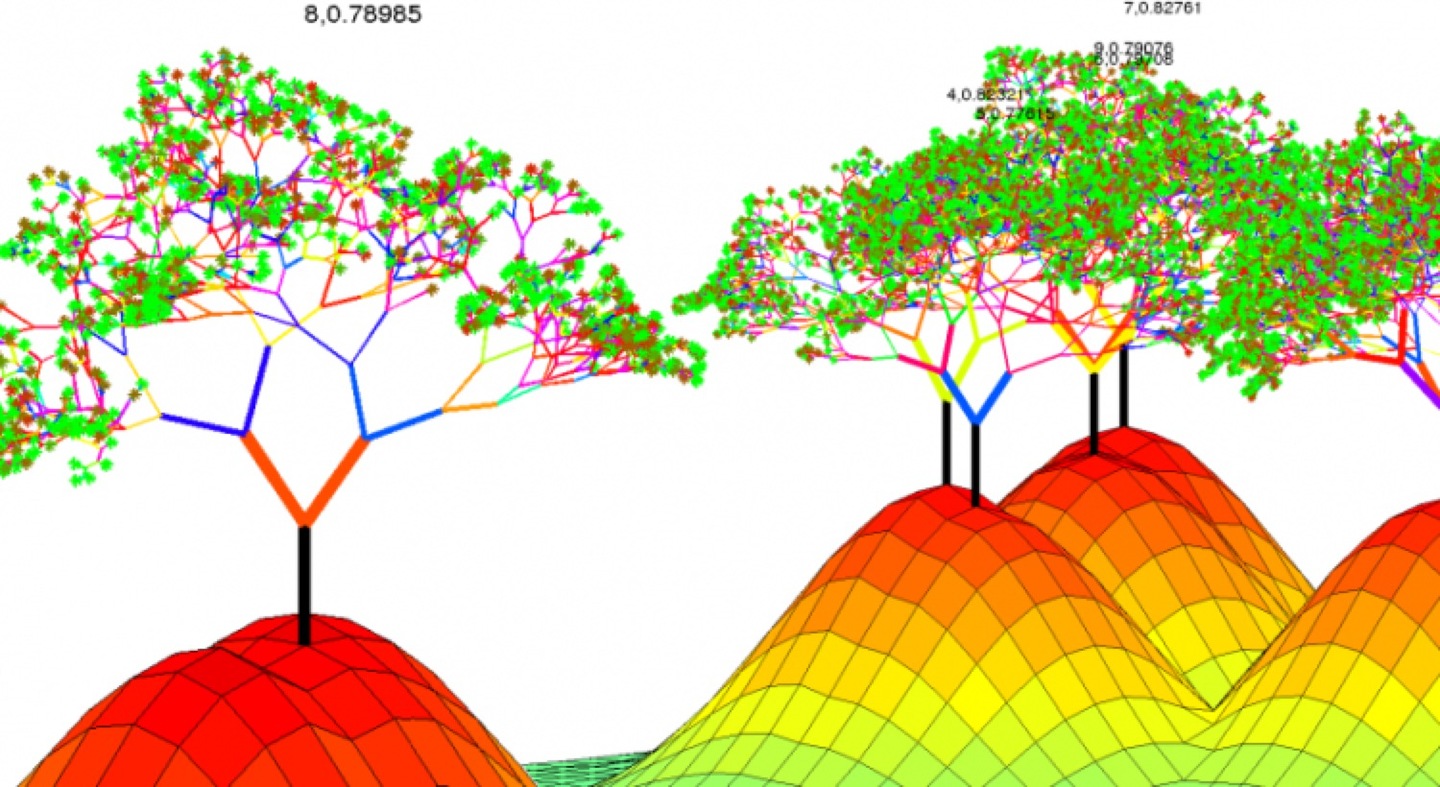
估计阅读时长: 9 分钟https://github.com/xieguigang/sciBASIC 在实际应用的机器学习方法里,GradientTree Boosting (GBDT)是一个在很多应用里都很出彩的技术。XGBoost是一套提升树可扩展的机器学习系统。XGBoost全名叫(eXtreme Gradient Boosting)极端梯度提升。它是大规模并行boosted tree的工具,XGBoost 所应用的算法就是 GBDT(gradient boosting decision tree)的改进,既可以用于分类也可以用于回归问题中。 Order by Date Name […]
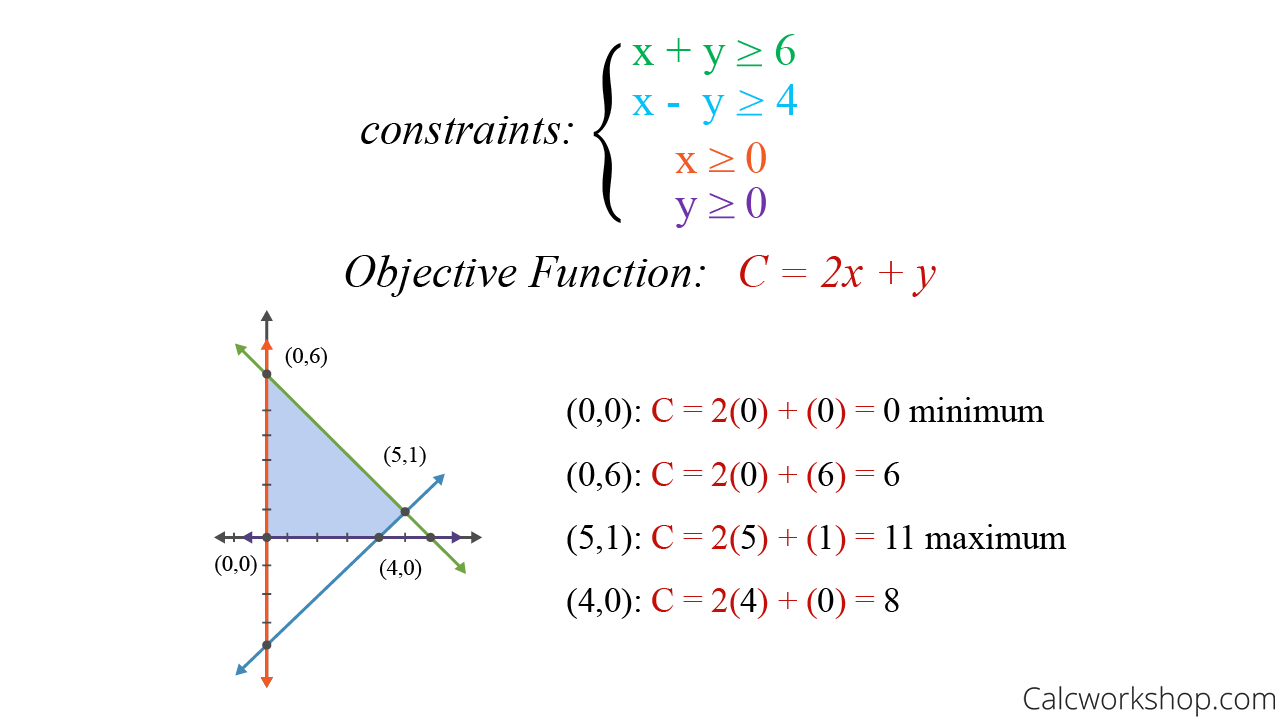
估计阅读时长: 30 分钟https://github.com/xieguigang/sciBASIC/ 线性规划(Linear programming,简称LP)方法起源于20世纪40年代,由美国数学家乔治·丹齐格(George Dantzig)提出,并设计了著名的“单纯形法”。这种优化算法是运筹学中研究较早、发展较快、应用广泛、方法较成熟的一个重要分支,它是辅助人们进行科学管理的一种数学方法。研究线性约束条件下线性目标函数的极值问题的数学理论和方法。通俗点的来讲,就是我们基于这一种数学优化技术,用于在一组线性约束条件下,求解线性目标函数的最大值或最小值(就是在“有限资源”和“一定规则”下,找到“最佳方案”的一种方法)。 Order by Date Name Attachments linear-programming-example • 22 kB • 876 click […]
估计阅读时长: 8 分钟https://github.com/xieguigang/sciBASIC 在进行无监督聚类分析的方法之中,我们在算法代码之中一般会遇到求解与某一个样本数据点最相似的数据点的计算过程。对于这个计算过程,一般而言我们是基于欧几里得距离来完成的。 Order by Date Name Attachments Visual a KDtree Search • 274 kB • 862 […]
估计阅读时长: 8 分钟https://github.com/xieguigang/sciBASIC/tree/master/Data_science/Mathematica/SignalProcessing 进行峰识别是在代谢组学原始数据分析之中进行定量分析的很重要的一环。在代谢组学之中,定量分析分为靶向定量,以及非靶向定量计算这两大部分。 Order by Date Name Attachments Figure12.36 • 50 kB • 820 click 2021年7月10日view_signal • […]
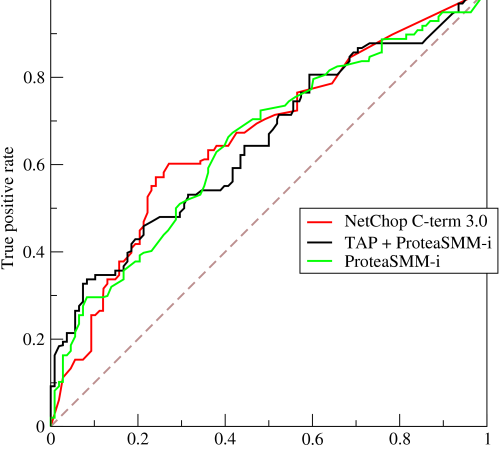
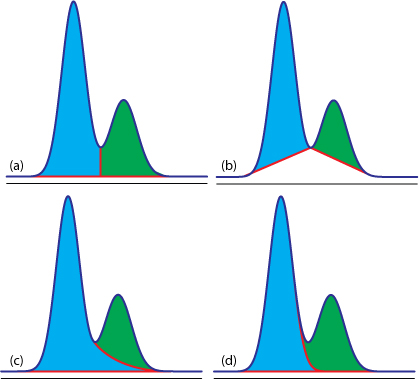
估计阅读时长: 8 分钟https://github.com/rsharp-lang/R-sharp 对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签。如神经网络得到诸如0.5,0.8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的归为0类,大于等于0.4的归为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1或0.2等等。 Order by Date Name Attachments ROC • 221 kB • 872 click 2021年6月28日Roccurves • […]
估计阅读时长: 23 分钟https://github.com/rsharp-lang/R-sharp 降维是将数据由高维约减到低维的过程而用来揭示数据的本质低维结构。它作为克服“维数灾难”的途径在这些相关领域中扮演着重要的角色。在过去的几十年里,有大量的降维方法被不断地提出并被深入研究,其中常用的包括传统的降维算法如PCA和MDS;流形学习算法如UMAP、t-SNE、ISOMAP、LE以及LTSA等。 Order by Date Name Attachments MNIST-LabelledVectorArray-60000x100 • 230 kB • 964 click 2021年6月27日MNIST-LabelledVectorArray-60000x100Euclidean_Distance • […]

估计阅读时长: 13 分钟https://github.com/xieguigang/voyager-1 旅行者一号是一艘由NASA在1977年9月5日发射的宇宙飞船,其只比旅行者2号晚16天发射。旅行者一号除了担负着研究我们的太阳系的任务之外,在这艘飞船之上还搭载着一张我们尝试对外界介绍我们的文明的一张名片为“地球之音”的铜质镀金激光唱片,这张金唱片承载着人类与宇宙星系沟通的使命。 Order by Date Name Attachments 1080px-The_Sounds_of_Earth_Record_Cover_-_GPN-2000-001978 • 330 kB • 877 click 2021年6月18日scripting • […]

估计阅读时长: 15 分钟进行生物化学代谢反应网络的模拟计算,可以分为三种技术路线:基于线性规划做优化的FBA方法,基于常微分方程组求解的动力学模拟方法,以及最近发展的基于图神经网络做模拟计算的深度学习计算方法。在下面的表格中,在这里进行比较和总结了上面所提到的三种计算分析方法各自的计算原理和应用领域: 计算方法 原理 优势 适用场景 通量平衡分析(FBA) 基于约束条件(如化学计量矩阵、酶容量限制)和线性规划,在假设代谢网络处于稳态(即代谢物浓度不变)的前提下,计算代谢通量的分布,通常以最大化特定目标(如生物量生长)进行优化 1. 无需详细的酶动力学参数,特别适合大规模网络研究。2. 计算速度快,可系统性地预测基因敲除或环境扰动下的表型变化。3. 广泛应用于指导代谢工程,优化目标产物合成。 追求快速评估和全局优化:如果你的研究目标是在基因组尺度上快速评估微生物在不同条件下的生长或产物合成潜力,并且难以获取详细的动力学参数,FBA是一个非常实用的起点 动力学模拟 基于质量作用定律等构建常微分方程组(ODEs),描述每个代谢物浓度随时间变化的动力学过程,通过数值方法求解方程组 1. 能够捕捉代谢物浓度和通量的瞬态动态变化,揭示更精细的调控机制2. […]
估计阅读时长: 10 分钟https://github.com/xieguigang/sciBASIC 根据积分表达式,微分方程的数值解关键在于微分方程的初值及计算微分方程式在tm(上一时刻)与tm+d(下一时刻)与坐标轴围成面积,若这个面积计算得越准确则得到的数值解也就越精确。微分表达式中与坐标轴围成的面积可表示如下,在实施算法的时候可以结合这个图更加直观点: 从上面的示意图可以看出,一段需要进行面积积分的曲线实际上是由多个梯形构成的多边形。那我们实际上只需要将这些梯形的面积都求出来,然后加起来就好了。 这里的梯形分割就是一种欧拉逼近的思想,欧拉逼近的几何意义,就是我们可以使用一段折线来近似的逼近一条曲线。 利用欧拉逼近,我们可以将一个精确的微分方程曲线 近似的使用线段来表示 Order by Date Name Attachments ODE_Trapezoidal • 30 kB • […]

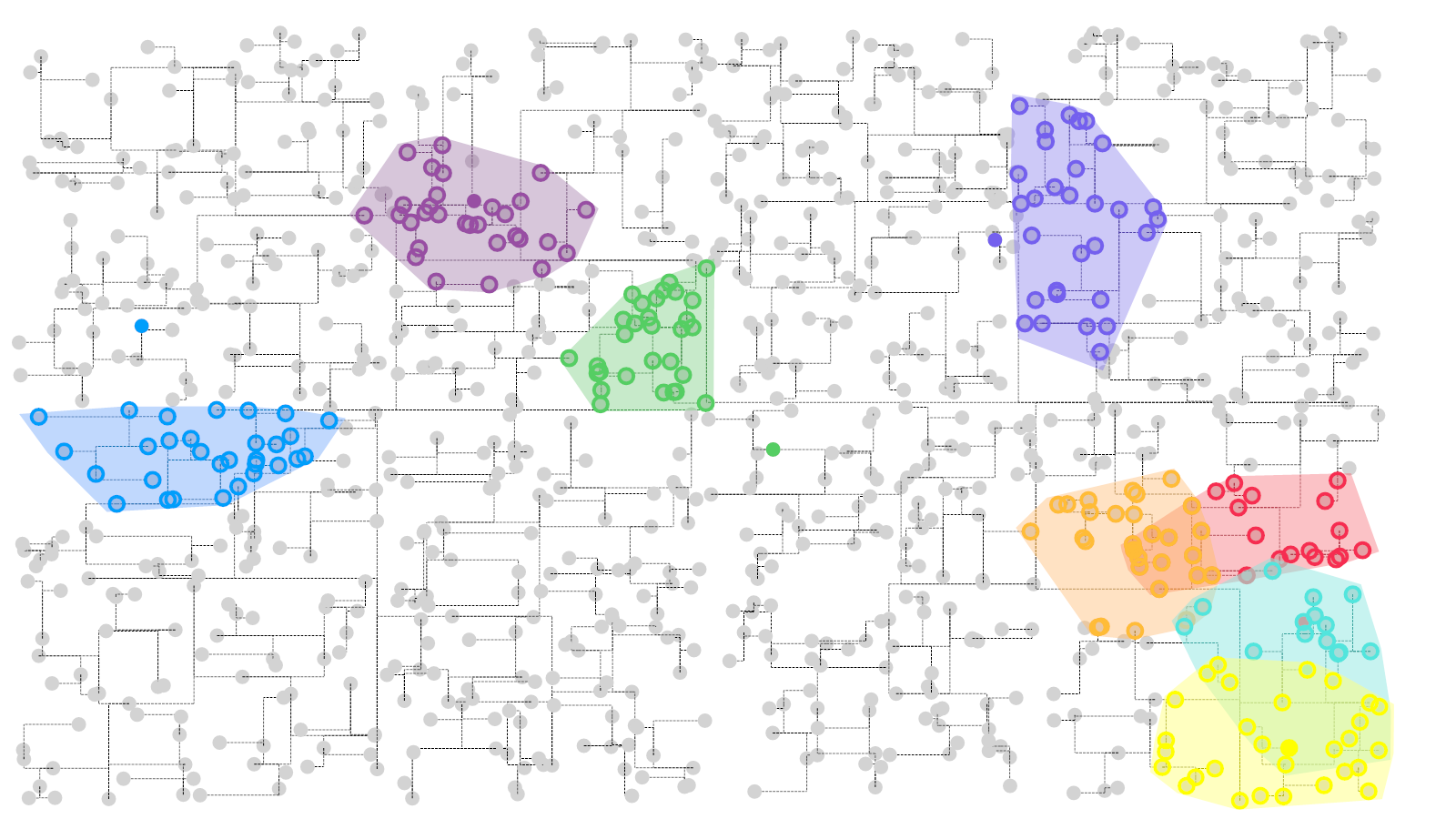
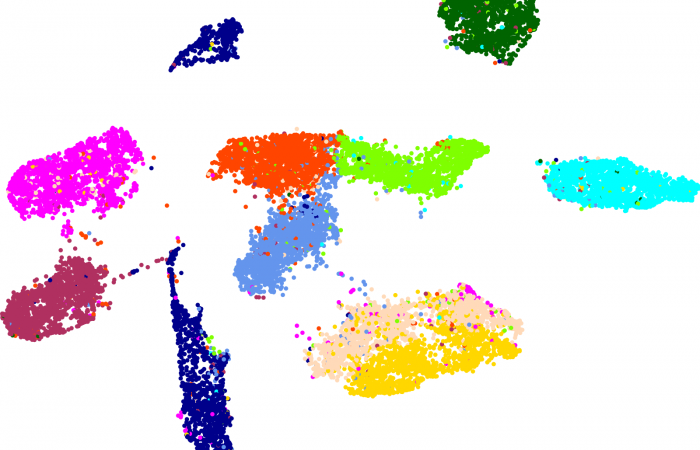
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?