
文章阅读目录大纲
 https://github.com/xieguigang/sciBASIC/tree/master/Data_science/Mathematica/SignalProcessing
https://github.com/xieguigang/sciBASIC/tree/master/Data_science/Mathematica/SignalProcessing
进行峰识别是在代谢组学原始数据分析之中进行定量分析的很重要的一环。在代谢组学之中,定量分析分为靶向定量,以及非靶向定量计算这两大部分。
- 对于靶向定量计算,我们只需要按照MRM的离子对得到对应的离子对目标的TIC进行峰识别;或者在GCMS靶向定量计算中,通过定量离子进行在SIM模式下取得对应的XIC进行峰识别
- 对于非靶向定量计算而言,虽然非靶向数据相较于靶向数据非常复杂。但是我们任然可以通过将一级质谱原始数据转换为XIC色谱图之后进行峰识别操作。
我们在完成了峰识别操作之后,就可以依照识别的目标峰进行峰面积计算。基于峰面积信息完成定量分析计算过程。
通过累加线进行峰识别
对于一个峰信号数据,一个最简单的识别方法就是找到一个信号最高点之后,逐步往左右两边查找分别找到两个最低点。这样子通过左右两边的最低点和中间的最高点就可以确定一个峰。但是这种情况我们只能够用于处理非常简单的信号,例如信号之间都是相互独立的,并且信号内不可以存在小峰。这种方法非常容易产生局部小峰的识别结果。
/\
/ \
/\/ \
_____/ \______通过上面的简单峰识别,我们可能会找出两个峰。但是实际上我们的信号数据中可能只存在一个峰。
那有没有一个相对简单并且可以避免上述问题的峰识别方法呢?还真有,假若我们将信号数据逐步累加起来,会发现一个比较有意思的现象,例如:

我们首先从一个最简单的信号开始学习这个算法。在Excel之中,我们将原始信号和信号数据的累加线放在一起的话,可以看见:
- 空信号区域的累加线的值基本无变化,无变化意味着这一段区间内的累加线基本与X坐标轴平行
- 当累加线到达峰的左边的时候,累加线会突然逐步增大。这个时候累加线的斜率是大于零的
- 当累加线到达峰的右边的时候,累加线又会重新趋向于与X坐标轴平行
我们根据这个累加线,对我们的原始信号数据切换了一个视角,事情仿佛就变得很简单了:我们只需要从累加线中找出斜率不为零的片段就可以完成峰识别了。
对于局部的小峰的过滤,我们只需要通过对斜率变化设置一个阈值就可以过滤掉了。
累加线算法的VisualBasic代码实现
通过上一个小结我们了解到了通过信号累加线是如何实现峰识别的原理。在这里我们就可以总结出在我们的代码之中需要识别哪些步骤了:
- 首先,我们就需要从原始的信号数据之中计算出累加线数据
- 然后,从累加线中计算出一个斜率数据
- 之后,将斜率数据中大于阈值的区域都给拿出来
- 将区域重新映射回原始信号数据中就得到所有的信号峰数据了。
那,我们现在首先来看累加线的计算实现代码:
<Extension>
Public Function AccumulateLine(signals As ITimeSignal(), baseline As Double) As Vector2D()
Dim accumulate#
Dim sumALL# = Aggregate t As ITimeSignal In signals
Let x As Double = t.intensity - baseline
Where x > 0
Into Sum(x)
Dim ay As Func(Of Double, Double) =
Function(into As Double) As Double
into -= baseline
accumulate += If(into < 0, 0, into)
Return (accumulate / sumALL) * 100
End Function
Dim accumulates As Vector2D() = signals _
.Select(Function(tick)
Return New Vector2D(tick.time, ay(tick.intensity))
End Function) _
.ToArray
Return accumulates
End Function之后的斜率计算,我们可以通过sin值的定义来完成:
Private Iterator Function sin(line As Vector2D()) As IEnumerable(Of Vector2D)
Dim A As Vector2D
Dim B As Vector2D
Dim sinA, sinC As Double
For Each con As SlideWindow(Of Vector2D) In line.SlideWindows(winSize:=2, offset:=1)
If con.Length = 2 Then
A = con.First
B = con.Last
sinA = B.y - A.y
sinC = EuclideanDistance(New Double() {A.x, A.y}, New Double() {B.x, B.y})
' B
' /|
' / |
' / |
' A ---- X
Yield New Vector2D(A.x, sinA / sinC)
End If
Next
End Function在这里,我构建出了一个滑窗,得到一前一后的两个相邻的AB数据点。因为相邻的两个数据点我们是知道他们的坐标位置的。所以我们可以直接计算出AB两个点之间的欧几里得距离作为直角三角形的斜边长度。至于直角三角形的对边,直接B的Y减掉A的Y就可以了。最后,对边比上斜边就可以计算出sin值用来表示斜率了。
很显然,我们在上面计算出来的sin斜率值是角度越大,值越趋向于1的,角度越小,值越倾向于0。比较符合我们的直觉认识。如果在这里使用cos值,因为cos(90)=0
所以,我们后面只需要按照设定好的阈值,将sin斜率大于阈值的片段都挑出来,就可以得到对应的峰数据区域片段了:
Private Iterator Function filterBySinAngles(angles As Vector2D()) As IEnumerable(Of SeqValue(Of Vector2D()))
Dim buffer As New List(Of Vector2D)
Dim i As i32 = 0
For Each a As Vector2D In angles
If a.y <= sin_angle Then
If buffer > 0 Then
buffer += a
Yield New SeqValue(Of Vector2D()) With {
.i = ++i,
.value = buffer.PopAll
}
End If
Else
buffer += a
End If
Next
If buffer > 0 Then
Yield New SeqValue(Of Vector2D()) With {
.i = ++i,
.value = buffer.PopAll
}
End If
End Function上面的这一段函数代码实现的功能很简单:就是将斜率大于阈值的部分添加进入buffer之中;然后遇到小于斜率阈值的地方就将buffer中的数据输出就好了。
通过上面的函数,我们就可以得到一个region对象的集合。我们对这个集合中的每一个region对象,按照片段的第一个元素和最后一个元素所确定的时间范围,取出原始信号数据,就完成峰识别过程了:
rtmin = region.value.First.x - dt
rtmax = region.value.Last.x + dt
area = line((time >= rtmin) & (time <= rtmax))
' 因为Y是累加曲线的值,所以可以近似的看作为峰面积积分值
' 在这里将区间的上限的积分值减去区间的下限的积分值即可得到当前的这个区间的积分值(近似于定积分)
Yield New SignalPeak With {
.integration = area.Last.y - area.First.y,
.region = rawSignals((time >= rtmin) & (time <= rtmax)),
.baseline = baseline
}上面所描述的算法过程,完整的源代码大家可以阅读Algorithm.vb这个源代码文件。
R#脚本中使用峰识别
在R#脚本环境之中,我将上面的峰识别方法封装为一个函数,可以供大家用于峰识别计算。这个函数位于signalKit之中的signalProcessing包模块之中。使用这个R#脚本函数的时候,一般只需要传递进入一个信号数据对象即可。
' imports "signalProcessing" from "signalKit";
<ExportAPI("findpeaks")>
Public Function FindAllSignalPeaks(signal As GeneralSignal,
Optional baseline As Double = 0.65,
Optional cutoff As Double = 3) As SignalPeak()
Return New ElevationAlgorithm(cutoff, baseline) _
.FindAllSignalPeaks(signal) _
.ToArray
End Function首先我们来看一下测试的原始数据。我们可以在Excel表格之中插入一个散点图来可视化我们的信号数据:
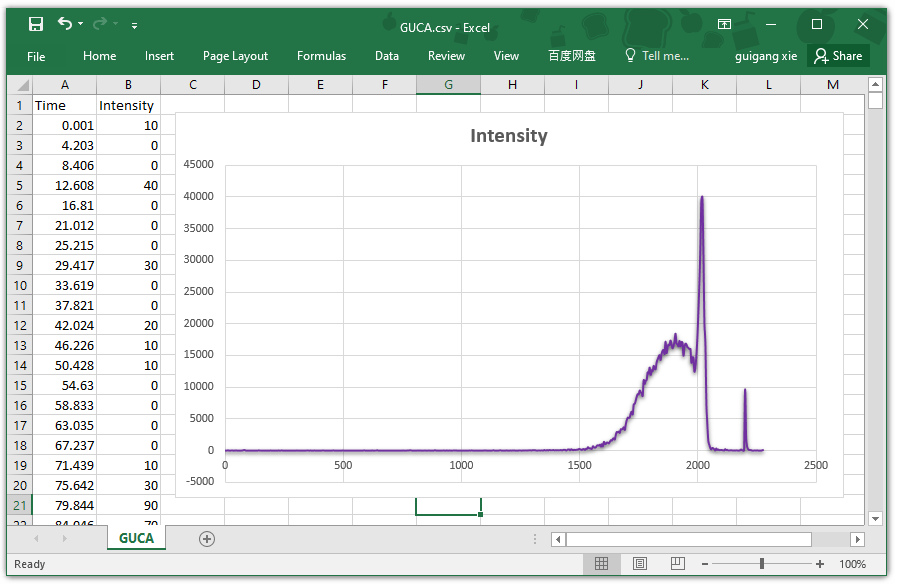
首先,我们从肉眼可以看见,目标信号可能存在有两个峰:第一个峰状态比较差,范围是1900到2100秒左右;第二个峰为就是一个比较窄和矮一些的尖峰,信号范围大概是2100到2200秒左右。
在R#脚本之中,可以直接通过findpeaks
imports "signalProcessing" from "signalKit";
`${dirname(@script)}/GUCA.csv`
|> read.csv
|> (function(signal) as.signal(signal[, "Time"], signal[, "Intensity"]))
|> findpeaks(
baseline = 0.7,
cutoff = 8
)
|> as.data.frame
|> t
|> print
;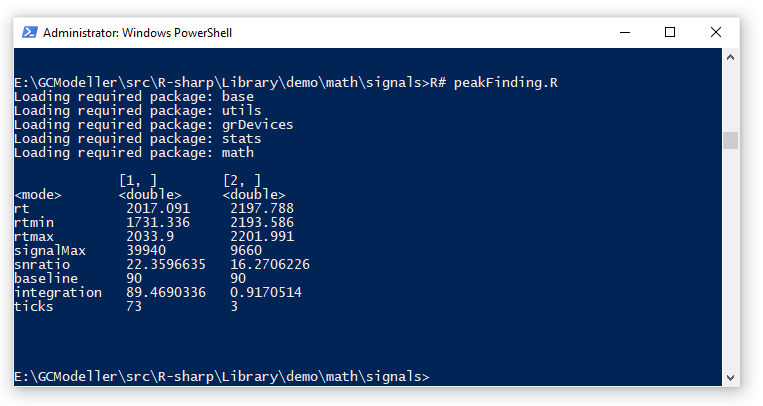
从执行的结果来看,除了第一个峰因为旁边的噪声的影响,峰识别的结果稍微宽了一些。第二个峰的识别结果是很正确的。
- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

One response
[…] 对于将上面所展示的XIC谱图里面所出现的峰的保留时间段位置给解析出来的操作,就是峰查找的操作了。进行峰查找操作,我们可以基于信号累加算法来实现。 […]