
文章阅读目录大纲
 https://github.com/rsharp-lang/R-sharp
https://github.com/rsharp-lang/R-sharp
对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签。如神经网络得到诸如0.5,0.8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的归为0类,大于等于0.4的归为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1或0.2等等。
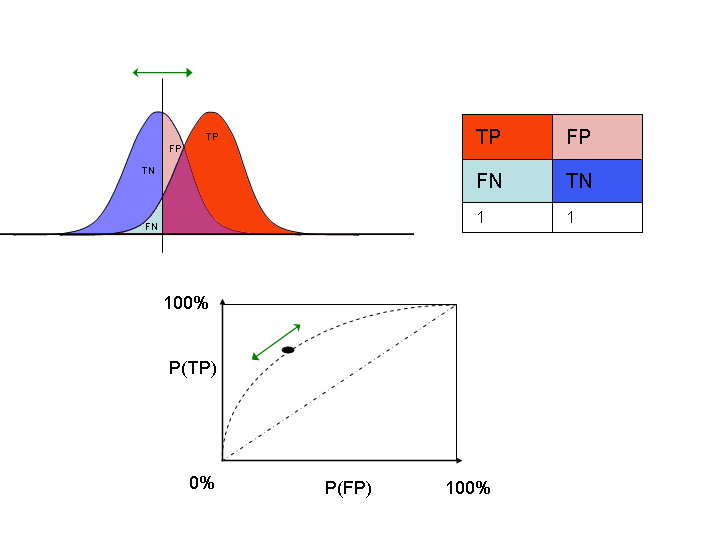
同时,由于分类算法的缺陷,算法输出的结果可能会在阳性和阴性分类结果之间存在一部分的重叠。所以我们会需要使用一种方法来进行我们的算法的准确度的评估。ROC曲线正是这样的一种评估我们的分类算法的性能的方法。
取不同的阈值,最后得到的分类情况也就不同。
ROC介绍
根据上面的描述和示意图中,我们也可以看得到:由于算法的缺陷,阳性结果可能会和阴性结果存在一部分的重叠。当我们将分类的阈值垂直线向左右移动的时候,可以得到不同的阈值。这样子,在不同的阈值下,假阳性率与假阴性率也在发生不同的变化。所以我们可以看得出来,ROC曲线的绘制就是选择阈值与计算当前阈值下假阳性率与真阳性率变化的过程。
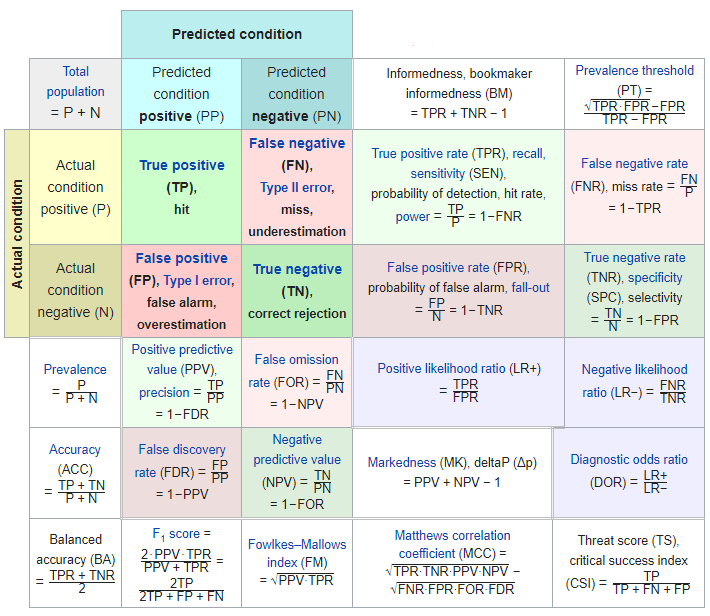
对于一个二元分类问题,我们只能够预测目标为目标分类或者不是目标分类,所以我们可以根据分类结果得到一个表格:
| 预测为正样本:+1 | 预测为负样本:-1 | |
|---|---|---|
| 原正样本:+1 | 真阳(TP) | 假阴(FN) |
| 原负样本:-1 | 假阳(FP) | 真阴(TN) |
上面所示的混淆矩阵在计算ROC曲线的时候起着非常重要的作用,因为ROC曲线绘制的时候所需要的X与Y轴的数据都会需要从这个矩阵中得到。对于ROC曲线,其X轴与Y轴的数据分别为True Positive Rate(真阳率,TPR)、False Positive Rate(伪阳率,FPR)。
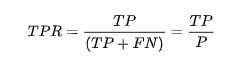
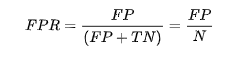
在得到了一个二元分类的结果集合之后,我们可以通过下面的代码在给定的阈值水平上计算出一个混淆矩阵:
Dim TP As Integer
Dim FP As Integer
Dim TN As Integer
Dim FN As Integer
Dim All%
For Each n As T In entity
Dim validate = getValidate(n)
Dim predict = getPredict(n)
If validate = True Then
If predict = True Then
TP += 1
Else
FN += 1
End If
Else
If predict = True Then
FP += 1
Else
TN += 1
End If
End If
All += 1
Next在上面的函数之中,getValidate函数是用于计算得到当前对象的真实标签结果;getPredict函数是用于计算得到当前对象的预测标签结果。则根据这两个函数的计算结果,我们就可以根据定义计算出一个用于ROC绘图所需要的混淆矩阵了。
AUC值计算
AUC(Area Under Curve)的本质含义反映的是对于任意一对正负例样本,模型将正样本预测为正例的可能性大于将负例预测为正例的可能性的概率。我们可以从AUC的英文全称知道,其含义为曲线下方的面积,很明显,当AUC的面积越大,我们的分类器的假阳性越低,真阳性率越高。AUC值的一个简单的计算方法就是将计算ROC得到的不同阈值下的由TPR和FPR这两个指标构成的坐标所产生的无数个小矩形的和。
一般,一个好的分类器,其AUC应该至少大于0.5。当然,这个AUC值的结果越高,表明我们的分类器性能越好。对于通过AUC值来评价我们的分类器的性能,一般有:
0.9 ~ 1.0(优秀)
0.8 ~ 0.9(良好)
0.7 ~ 0.8(一般)
0.6 ~ 0.7(很差)
0.5 ~ 0.6(无法区分)在R语言中进行ROC分析
library(ROCR);
# predictions为预测标签,labels为真实标签
pred <- prediction(predictions, labels);
perf <- performance(pred, "tpr", "fpr");
auc <- performance(pred, 'auc');
auc <- unlist(slot(auc,"y.values"));
plot(perf,
xlim = c(0,1),
ylim = c(0,1),
col = 'red',
main = paste("ROC curve (", "AUC = ",auc,")"),
lwd = 2,
cex.main = 1.3,
cex.lab = 1.2,
cex.axis = 1.2,
font = 1.2
);
abline(0, 1);我们在R语言之中可以通过一个名为ROCR的程序包进行ROC计算分析,我们执行上面的脚本代码,一般可以得到与下图类似的ROC曲线图:
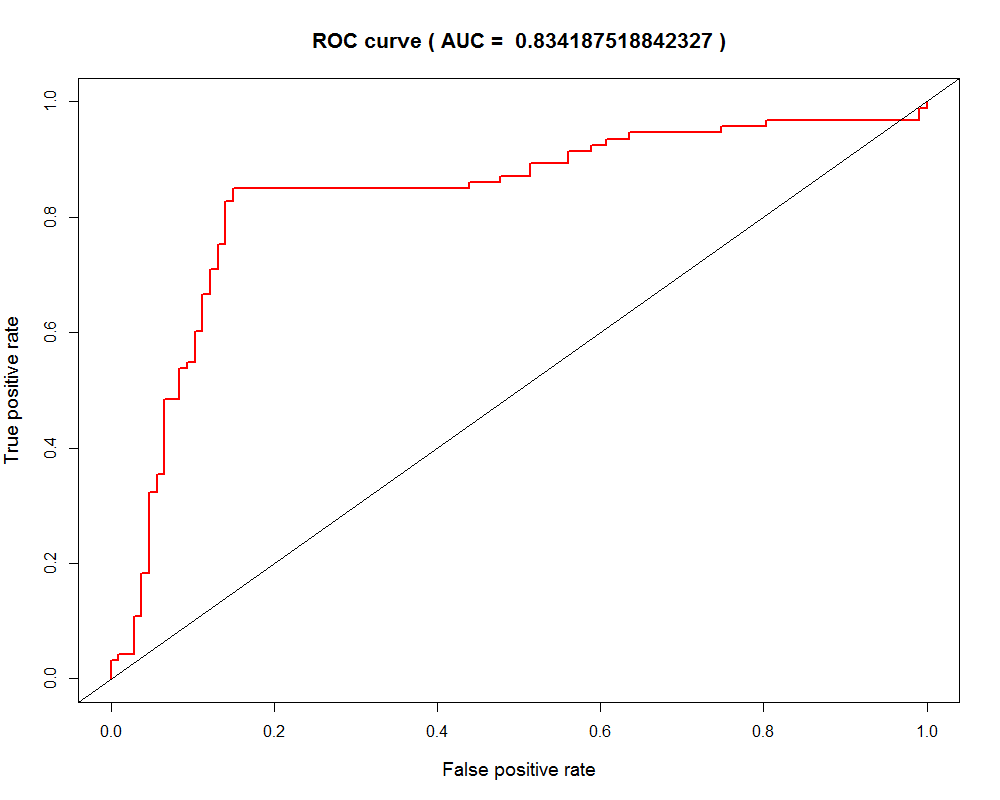
ROC曲线越凸越近左上角表明其诊断价值越大,利于不同指标间的比较。曲线下面积可评价诊断准确性。
可以看得到,我们得到的ROC图,横坐标为假阳率即(FP/(FP+TN));纵坐标为真阳率即(TP/(TP+FN));因为我们肯定会希望我们的分类器真阳性率很高,假阳性率为零。所以ROC曲线越靠近左上角,表示分类器的分类效果越好。
在R#语言中进行ROC计算分析
在R#环境之中进行ROC的计算分析,可以使用MLkit程序包模块自带的数据方法验证程序包中的ROC计算函数。下面介绍在R#语言中做ROC验证的一些主要函数:
- prediction 这个函数的作用与R语言之中的
ROCR - AUC 这个函数的作用,通过其名字就可以看得出来,是计算ROC分析中的AUC值的。其接受的计算参数来自于prediction函数的参数返回值。
imports "validation" from "MLkit";
# predictions is the score value of the predictions
# and labels is the real data labels, should be a logical vector that
# equals to predictions vector in size
const pred <- prediction(predictions, labels);
const auc <- AUC(pred);我们下面看一个demo来了解上面的两个函数是如何使用的。首先我们来查看一下测试用的数据集:
const url = "github://rsharp-lang/R-sharp/blob/master/Library/demo/machineLearning/umap/ROC.csv";
const data = read.csv(file = url);
str(data);
print(head(data));
# 'data.frame': 200 obs. of 2 variables:
# $ V1 : num [1:200] 0.6125478 0.364271 0.4321361 0.1402911 0.3848959 0.2444155 ...
# $ V2 : int [1:200] 1 1 0 0 0 1 ...
#
# V1 V2
# <mode> <double> <integer>
# [1, ] 0.6125478 1
# [2, ] 0.364271 1
# [3, ] 0.4321361 0
# [4, ] 0.1402911 0
# [5, ] 0.3848959 0
# [6, ] 0.2444155 1上面的表格数据来自于R语言之中的ROCR程序包内的一个数据框。在这个数据框对象之中,仅由两列计算ROC所必须的数据构成:第一列为预测的得分值,第二列为对象的预测得分值对应的真实标签。
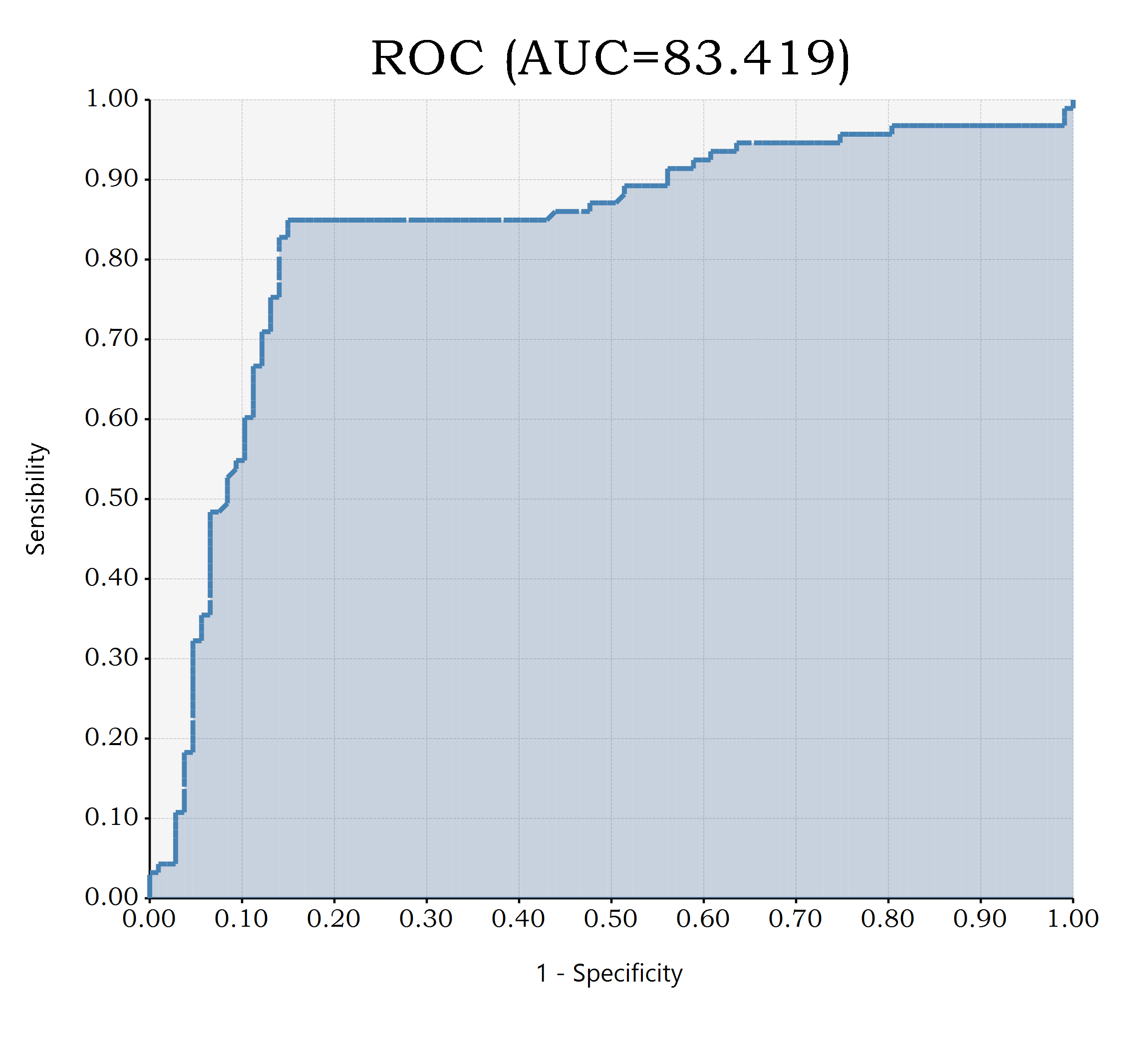
看完了DEMO数据之后,我们就可以使用R#环境之中所提供的ROC计算函数进行ROC计算,评估我们的算法性能了:
const pred = prediction(data[, 1], data[, 2]);
print(`AUC = ${AUC(pred)}`);
# [1] "AUC = 83.4187518842326"
bitmap(file = `${dirname(@script)}/ROC.png`) {
plot(pred);
}
当然,我们也可以手动计算AUC值。例如我们可以通过下面的一个简单函数进行AUC值的计算:
const simple_auc <- function(TPR, FPR){
# inputs already sorted, best scores first
const dFPR <- c(diff(FPR), 0);
const dTPR <- c(diff(TPR), 0);
sum(TPR * dFPR) + sum(dTPR * dFPR) / 2;
};
print(simple_auc(
TPR = pred$sensibility,
FPR = pred$FPR
));
# [1] 83.4187519事实上,上面的函数中的计算过程,也是在R#中进行AUC计算的底层代码的实现。对应的VisualBasic底层代码,大家可以阅读Evaluation/ROC.vb这个源代码文件:
Public Function SimpleAUC(TPR As Vector, FPR As Vector) As Double
Dim dFPR As Vector = C(diff(FPR), 0)
Dim dTPR As Vector = C(diff(TPR), 0)
Return (TPR * dFPR).Sum + (dTPR * dFPR).Sum / 2
End Function
- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

One response
[…] 从之前的测试结果脚本中,我们将预测结果与对应的真实标签都放在一起了。现在我们可以基于这两个向量数据进行XGBoost分类器的分类性能ROC曲线的可视化: […]