
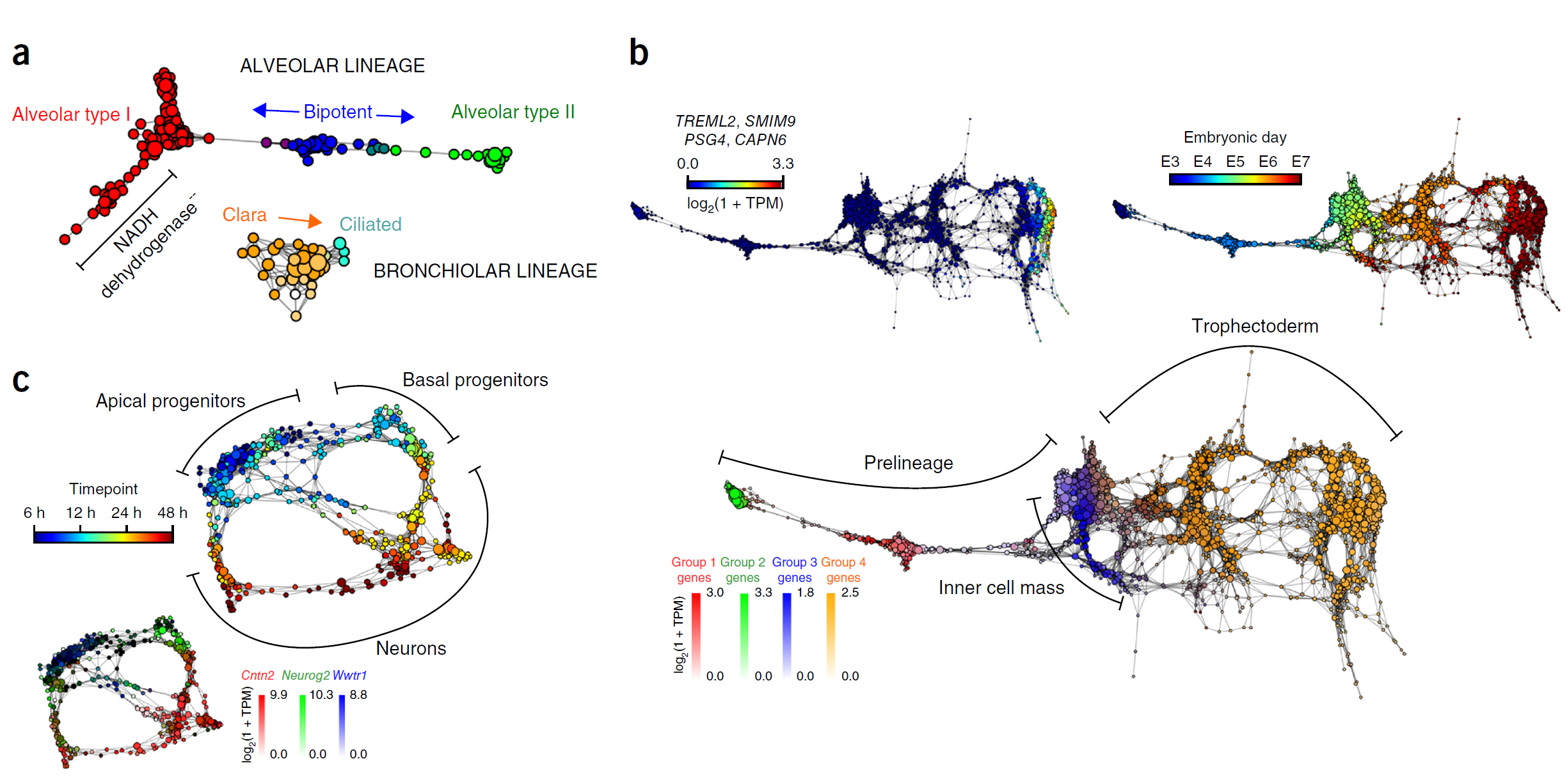
估计阅读时长: 14 分钟单细胞分析方法学习文献打卡记录: 【单细胞组学】PhenoGraph单细胞分型 【单细胞分析方法】VeTra:基于RNA速度的轨迹推断工具 【单细胞分析方法】单细胞图嵌入 Order by Date Name Attachments Cellular populations during motor neuron differentiation • […]
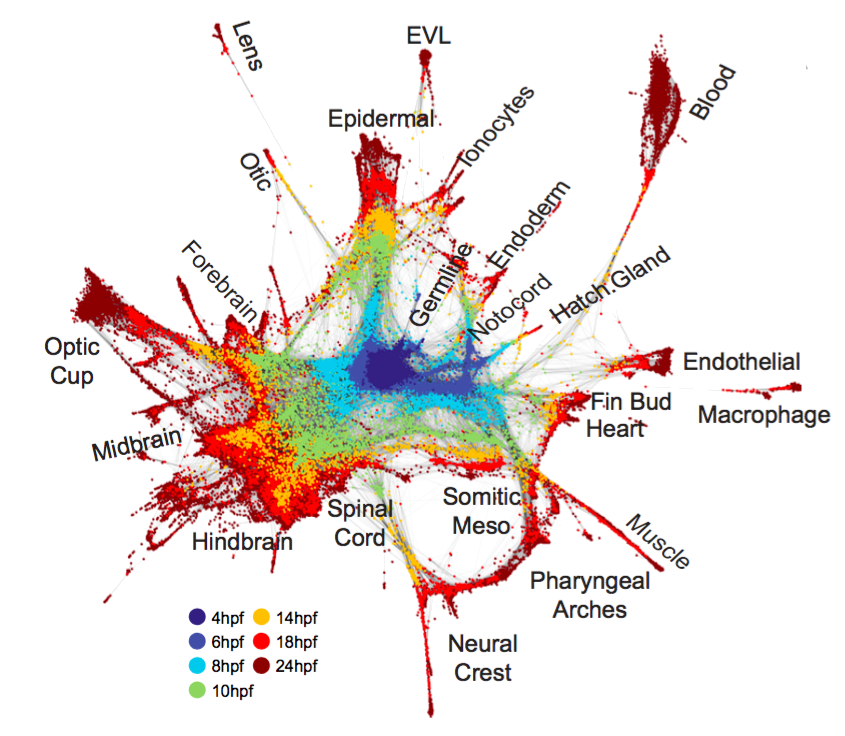
估计阅读时长: 7 分钟Assembles a manifold that is defined through a series of overlapping, locally-defined PCA subspaces. Non-mutual k-nearest-neighborhoods […]
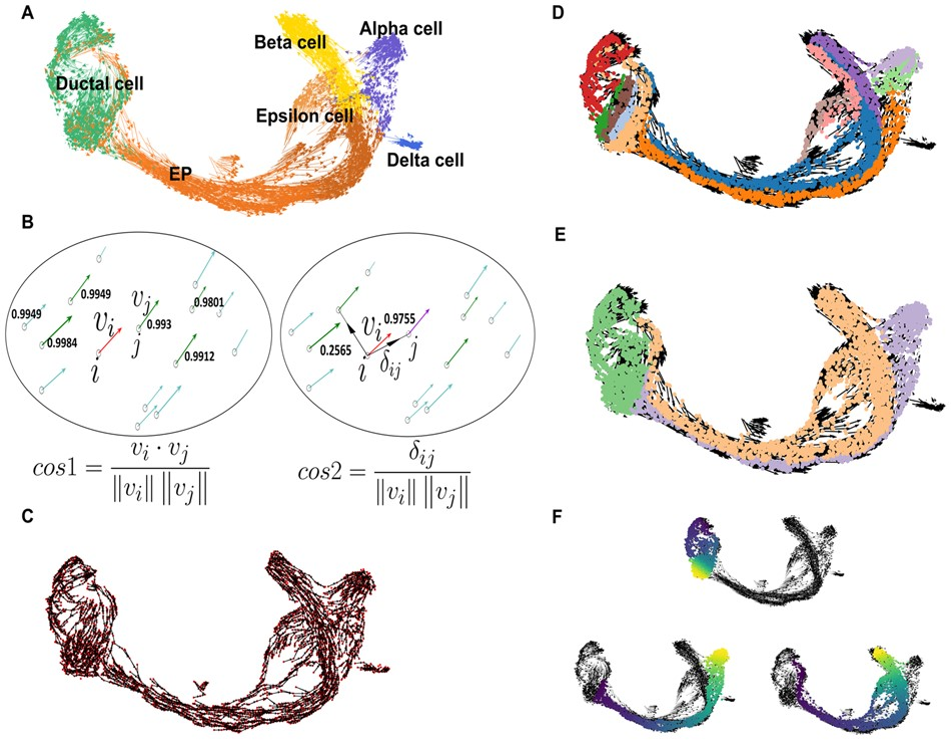
估计阅读时长: 5 分钟单细胞轨迹可以揭示基因调控如何控制细胞命运:大多数细胞状态转变,无论是在发育,重编程或者是疾病异常状态,都以基因表达变化的级联为特征。 Order by Date Name Attachments vec • 722 kB • 785 click 2022年3月17日Slide10 • 14 […]
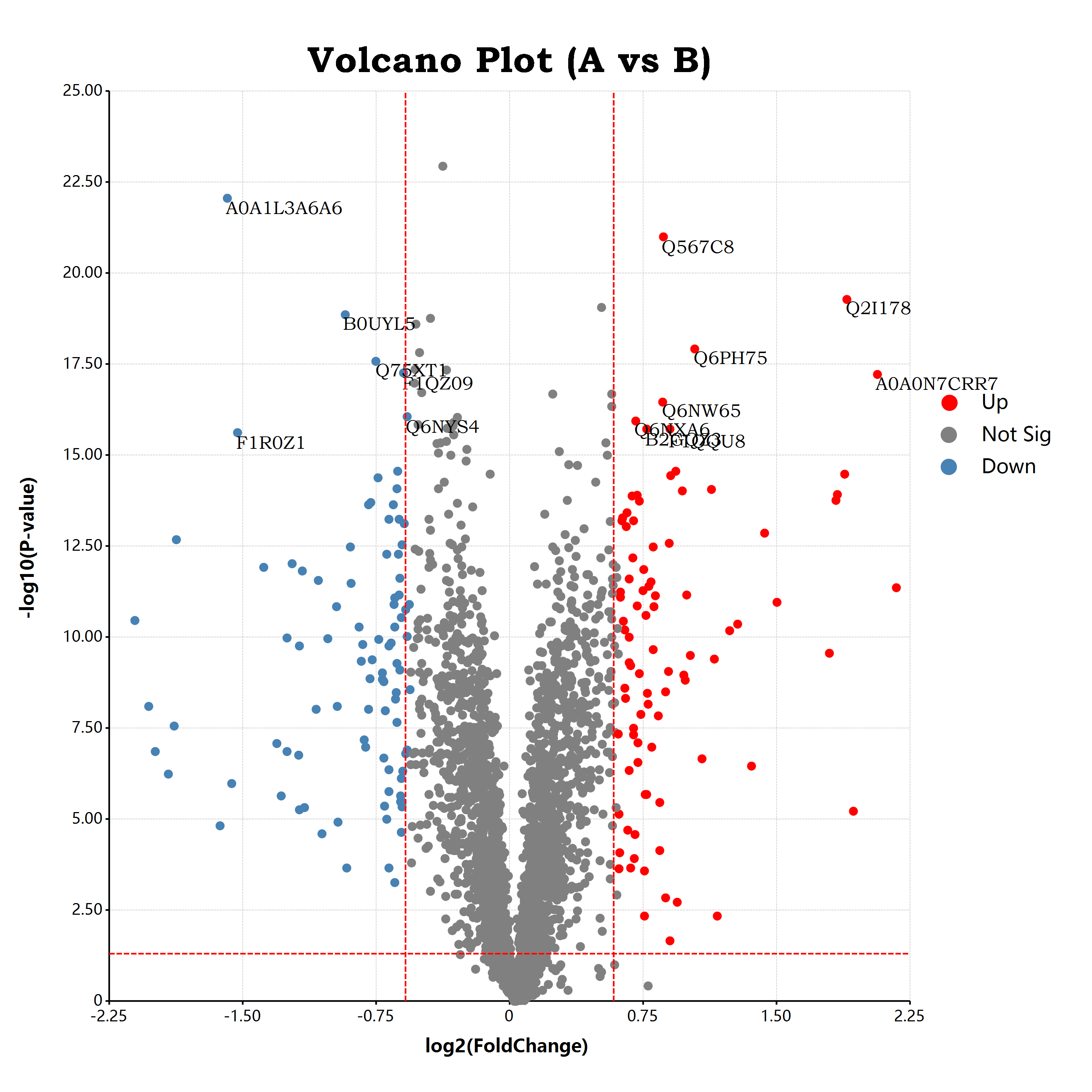
估计阅读时长: 17 分钟https://github.com/rsharp-lang/ggplot 接上一篇博客文章中谈到,我们已经通过R#语言之中的ggplot程序包绘制出了一个可以使用的火山图。在这里,我们将会通过在火山图上添加更多的可视化元素来为大家介绍R#语言之中的ggplot程序包的进阶使用方式。 Order by Date Name Attachments volcano • 651 kB • 855 click 2021年10月9日volcano • […]
估计阅读时长: 11 分钟https://github.com/rsharp-lang/ggplot 在生物信息学中的组学数据分析领域内,有一个非常常见的数据可视化图表:应用于可视化两两组别比对结果的火山图。在火山图之中,X坐标轴一般是log2FC,纵坐标Y轴,则一般是t检验的pvalue的-log10转换之后的值。由于fold change有大于1的值,A/B大于1,表示A的表达量高于B的表达量,反之小于一表示A的表达量低于B的表达量。这样子fold change经过log2转换之后,就会出现负数,散点一般呈轴对称分布在X=0的位置周围。这样子绘制出来的散点图就有点类似于火山喷发的样子了。 Order by Date Name Attachments a679af1eb9ffbfbad48c18d563ea51f3 • 45 kB • 823 click […]
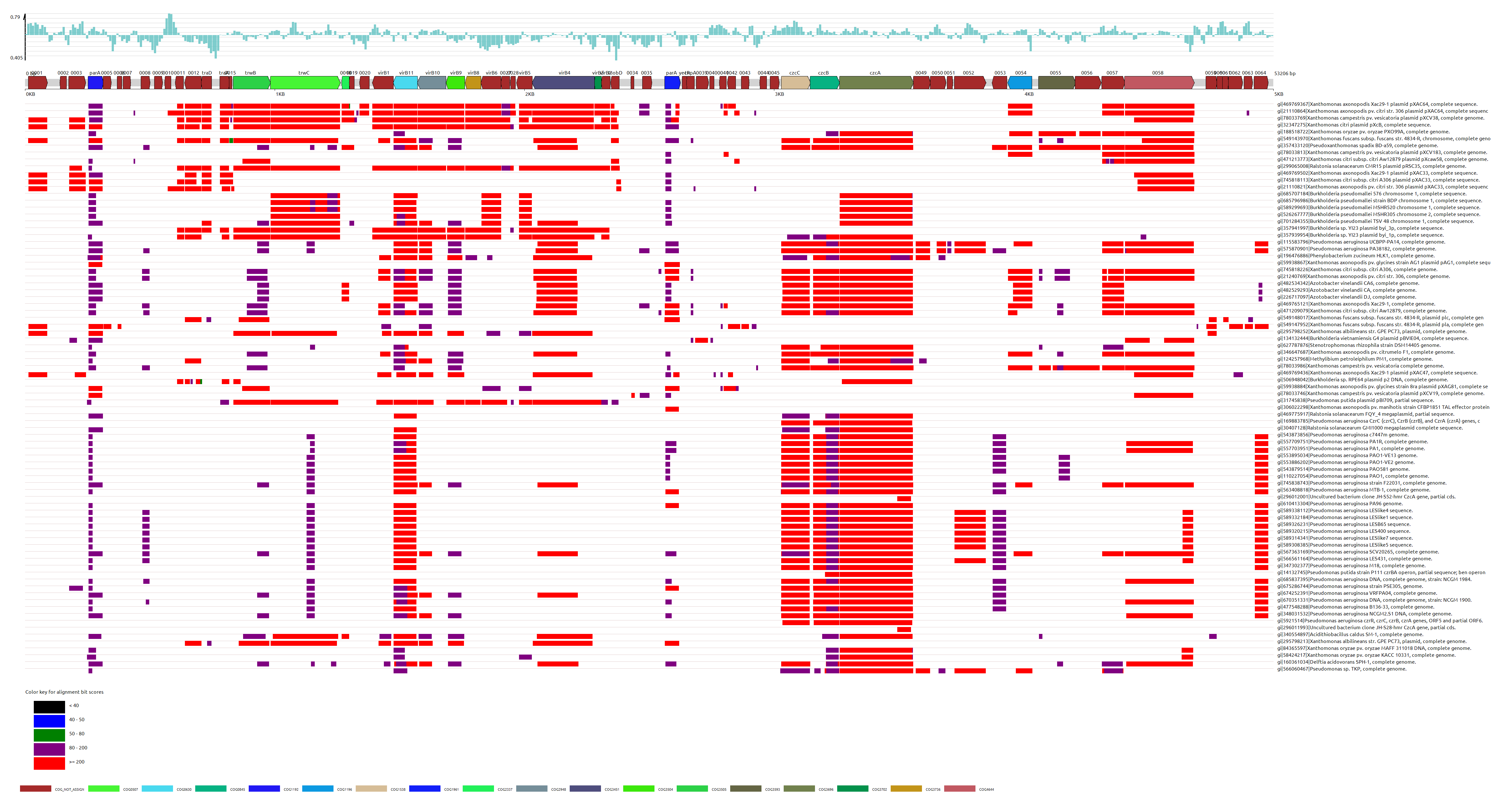
估计阅读时长: 14 分钟在基因组学研究中,将新测序的基因或者针对目标基因组进行基于KEGG代谢通路体系的虚拟细胞建模,都会需要将目标基因组与已知功能基因进行比对注释。KEGG(Kyoto Encyclopedia of Genes and Genomes)数据库通过其KEGG Orthology (KO)系统,为基因功能注释提供了一个强大的平台。KO系统将功能上保守的直系同源基因归为一类,每个KO条目(K编号)代表一个直系同源基因群,这些基因在不同物种中通常执行相似的生物学功能。因此,将新基因的序列与KEGG数据库中的已知基因进行比对,可以推断其可能的KO编号,从而将其功能映射到KEGG通路图或功能层级中。 Order by Date Name Attachments kegg_overview • 313 […]
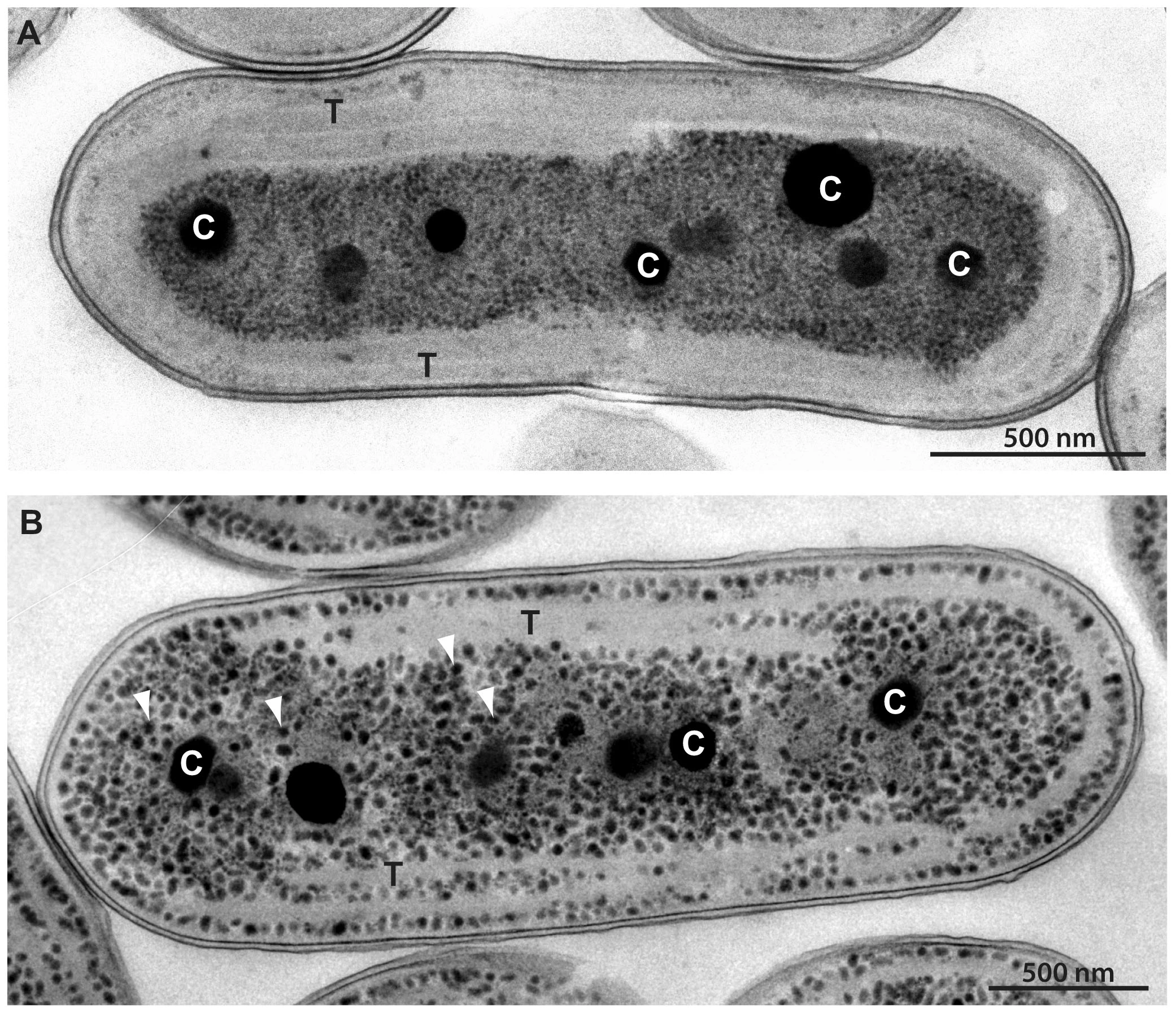
估计阅读时长: 10 分钟https://gcmodeller.org/ 流平衡分析(flux balance analysis)是一种可以用来构建和模拟分析基因组级别的代谢网络的数学方法。流平衡分析是系统生物学(system biology)的一个重要的分析手段。不同于以湿实验的代谢通量分析(metabolic flux analysis, MFA),FBA是用数学方法对代谢网络里的代谢流进行拟合分析。 Order by Date Name Attachments Electron micrographs of […]

估计阅读时长: 5 分钟原始数据相关的 名词 全称 中文名 含义 mz mass to charge ratio 质荷比 精确分子质量与离子的电荷数量的比值。 rt retention time 保留时间 […]

估计阅读时长: 15 分钟进行生物化学代谢反应网络的模拟计算,可以分为三种技术路线:基于线性规划做优化的FBA方法,基于常微分方程组求解的动力学模拟方法,以及最近发展的基于图神经网络做模拟计算的深度学习计算方法。在下面的表格中,在这里进行比较和总结了上面所提到的三种计算分析方法各自的计算原理和应用领域: 计算方法 原理 优势 适用场景 通量平衡分析(FBA) 基于约束条件(如化学计量矩阵、酶容量限制)和线性规划,在假设代谢网络处于稳态(即代谢物浓度不变)的前提下,计算代谢通量的分布,通常以最大化特定目标(如生物量生长)进行优化 1. 无需详细的酶动力学参数,特别适合大规模网络研究。2. 计算速度快,可系统性地预测基因敲除或环境扰动下的表型变化。3. 广泛应用于指导代谢工程,优化目标产物合成。 追求快速评估和全局优化:如果你的研究目标是在基因组尺度上快速评估微生物在不同条件下的生长或产物合成潜力,并且难以获取详细的动力学参数,FBA是一个非常实用的起点 动力学模拟 基于质量作用定律等构建常微分方程组(ODEs),描述每个代谢物浓度随时间变化的动力学过程,通过数值方法求解方程组 1. 能够捕捉代谢物浓度和通量的瞬态动态变化,揭示更精细的调控机制2. […]
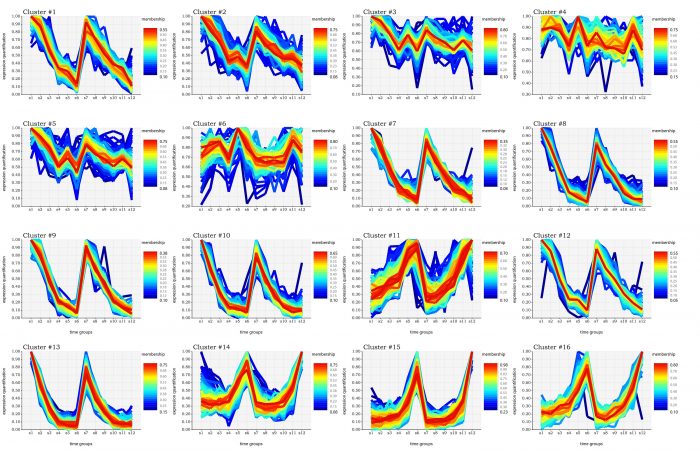
估计阅读时长: 11 分钟https://github.com/SMRUCC/GCModeller 在R语言之中,存在着一个用于进行表达数据的时间序列分析的程序包:TCseq。TCseq的全称为Time course sequencing,即时间序列分析,通过对表达矩阵进行时间上的模糊CMeans聚类,得到表达变化趋势一致的基因列表,进行基因表达的时间趋势分析。 在GCModeller之中,我仿照着TCseq程序包,自己编写了一个时间序列的聚类与可视化分析的R#程序包模块,在这里介绍给大家。 Order by Date Name Attachments Gene expression pattern visualization • 2 […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?