
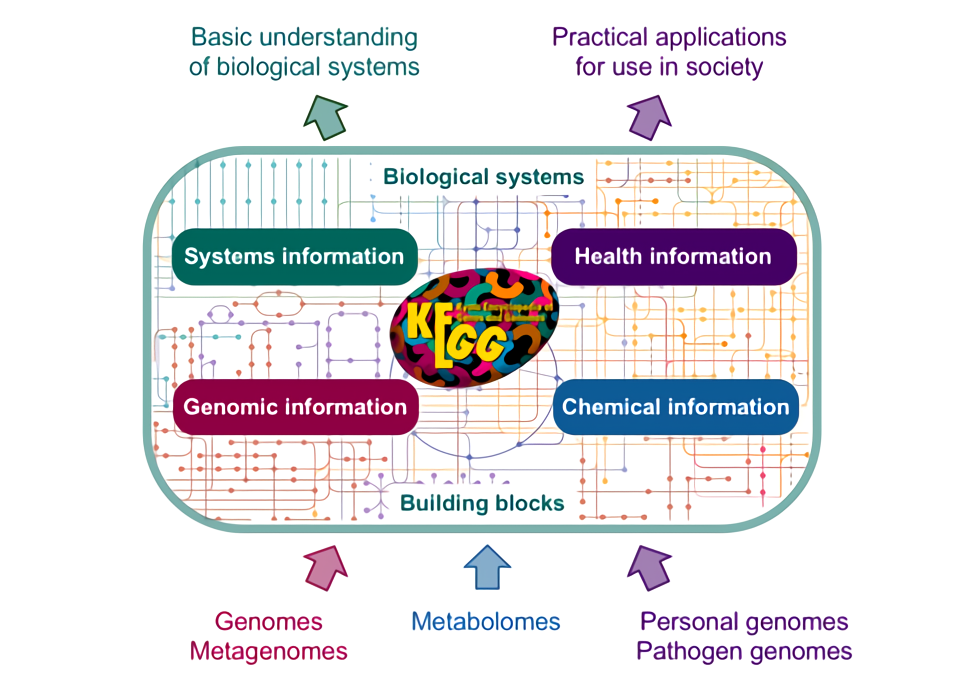
估计阅读时长: 16 分钟KEGG 里面目前并没有“现成的每个 KO 一条代表性序列 FASTA”这种官方序列数据库,假若我们需要基于KEGG数据库中的KO信息的注释,那我们一般会需要自己从 KEGG GENES 里面把每个 KO 对应的基因/蛋白序列抓出来,再按 KO 编号组织成 fasta 集合构建出对应的数据库。基于所建立好的KEGG基因序列数据库,我们就可以实现下面的一些基因注释工作: 在全基因组规模代谢网络重建工作中,进行我们的目标基因组中的代谢网络中的酶节点的直系同源推断,从而将我们的目标基因组中的基因映射到具体的KEGG代谢网络上的节点位置,从而重建出代谢网络模型(使用带有KO编号的蛋白序列做比对注释) 假若我们在进行宏基因组的基因丰度的计算,则可以基于所建立的KEGG基因序列数据库作为参考库,进行宏基因组测序数据中的KO基因丰度的计算(使用带有KO编号的基因序列做比对注释) […]
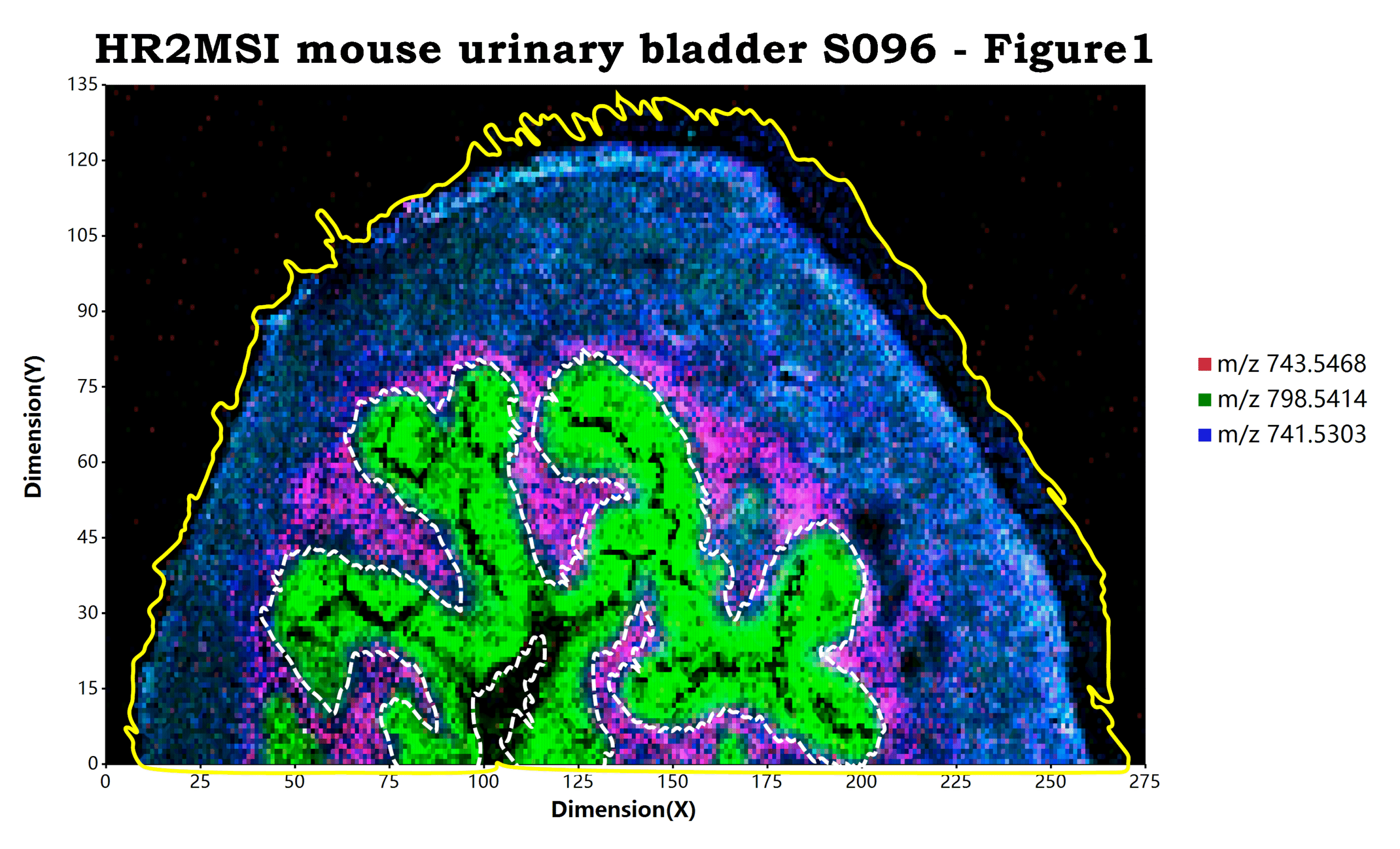
估计阅读时长: 10 分钟目前经过改进和优化之后的基于mzkit代码库底层的msimaging质谱成像软件包在样本可视化上进行了非常多的改进,诸如: 添加样本原始背景叠加 目前进行质谱成像可视化,程序包不仅仅可以使用任意rgb纯色来作为可视化的背景。目前还可以支持直接使用原始数据的背景作为质谱成像的显示背景。进行这个显示的秘诀就在于简单的在脚本中添加一个TIC背景图层:geom_MSIbackground("TIC") ggplot(msi_data, padding = "padding: 200px 600px 200px 250px;") + geom_MSIbackground("TIC") # rendering of […]
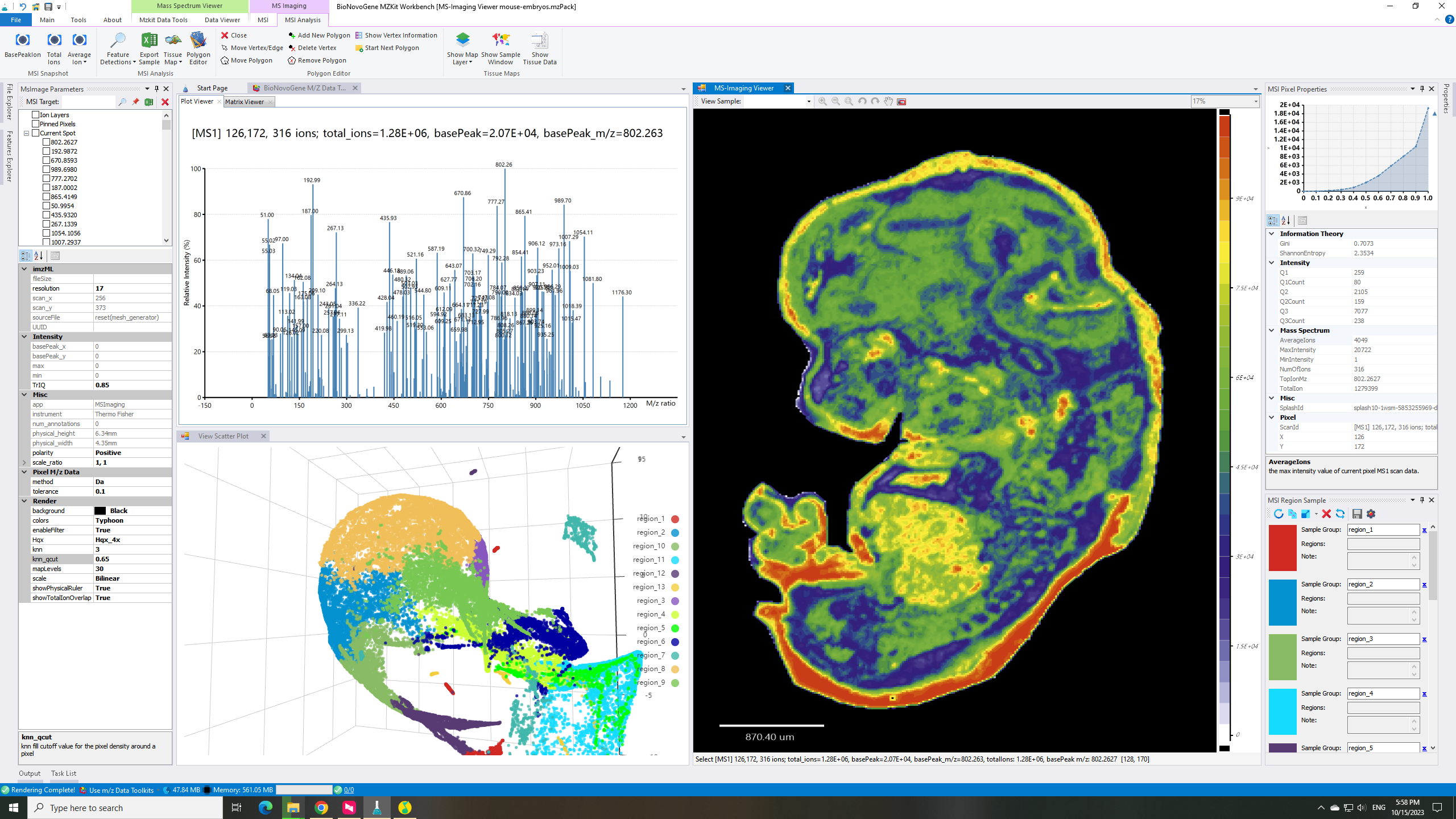
估计阅读时长: 4 分钟基于UMAP工具进行简单的自动化组织分区操作 在这里我们假设已经可以正常的将空间代谢数据导入至MZKit工作站软件之中。假若需要借助于MZKit工作站软件进行切片组织样本的自动化分区操作,相关的功能可以在【MSI Analysis】菜单栏中寻找到。在这里我们打开【Show Map Layer】按钮,选择【UMAP and clustering】功能。 基于降维的组织自动化分区原理 因为降维操作一般是一种特征提取操作,所以经过降维之后,在高维度空间上无法显现的特征,在低维度会呈现出来。在高维度空间散落的相近的数据点,在经过特征提取之后,低维度上会产生相似的特征信息,相互聚集在一簇。这样子我们就可以在低维度空间上通过一些聚类算法讲这些特征进行聚类,最后将聚类特征结果标记到各个散点上的对应的原始成像空间上,我们就可以看见组织分区的结果了。 Abdelmoula, W.M., Lopez, B.GC., Randall, E.C. et […]
估计阅读时长: 6 分钟大家好呀,今天的这篇文章主要是为了回答在B站上的一位小伙伴的请求 Order by Date Name Attachments render-parameters • 18 kB • 821 click 2023年10月15日view-umap • 427 […]
估计阅读时长: 5 分钟在BILIBILI上观看视频:《【BioNovoGene Mzkit教程】代谢组学原始数据处理基础》 最近我在B站的视频页面下发现了这样的一条评论,面对质谱数据分析领域内的初学者的求教,其实自己也是非常的诚惶诚恐的。因为在视频中所使用的脚本语言是自己开发的一门新语言,所以可能给一些初学者造成了一部分的困扰哈哈😅😄😅😅。首先先对这个粉丝说一声抱歉哈。 针对上述的提问,我的回答大概是有以下的几点: Order by Date Name Attachments question_20230223 • 17 kB • 790 click […]
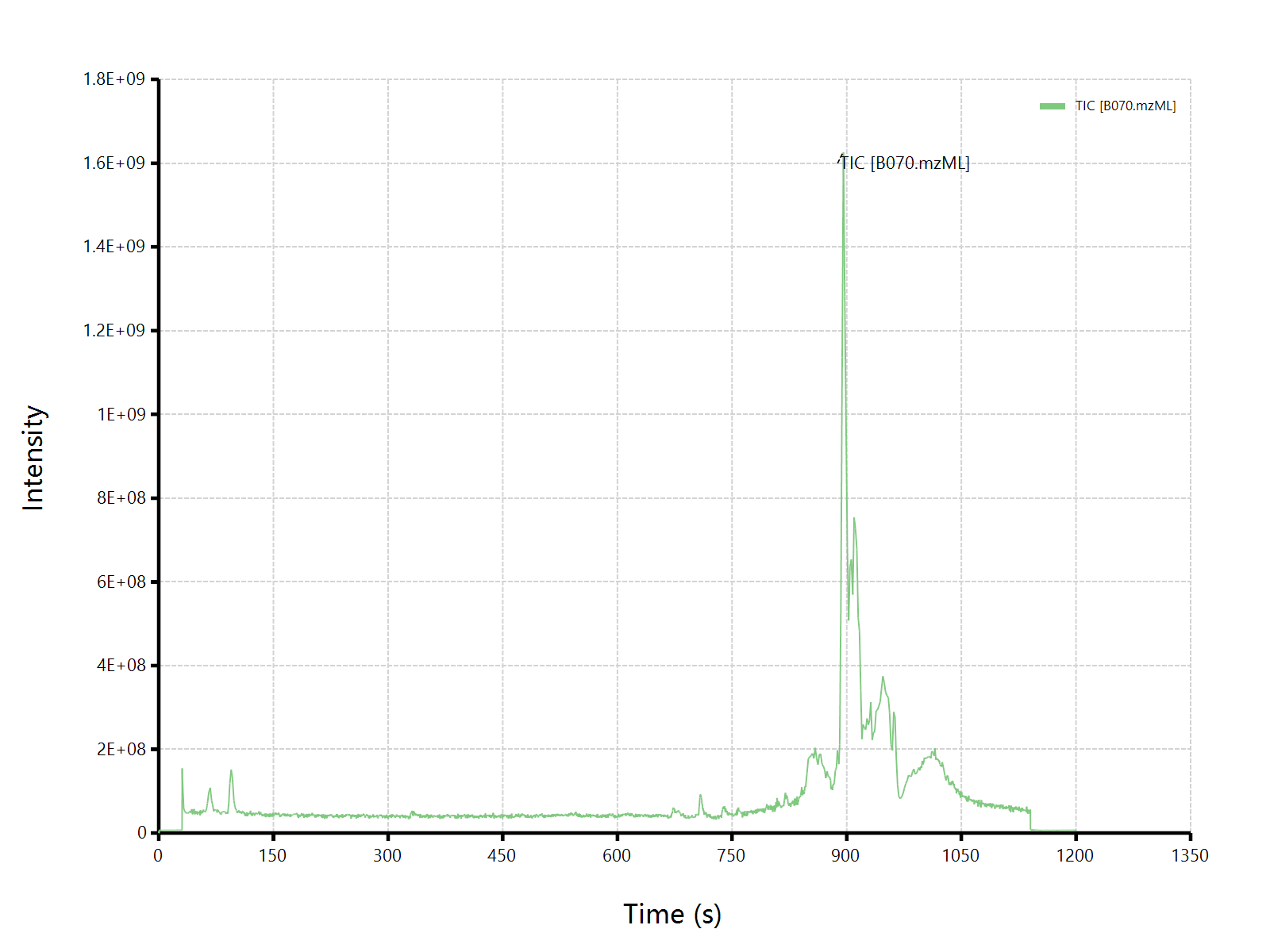
估计阅读时长: 4 分钟在代谢组学领域内,LCMS原始数据分析一般分为非靶向全扫原始数据,以及仅针对某些离子进行扫描的MRM靶向质谱数据。虽然二者都是基于LCMS方法进行实验,但是MRM靶向数据由于在事先已经通过实验确定,得到了Q1和Q3离子对信息,所以可以仅针对某一些特定代谢物进行检测。因为MRM数据是针对于某些代谢物检测的靶向数据,所以其XIC谱图在没有同分异构体存在的情况下,一般是很纯净的目标化合物的检测结果数据。所以在原始数据分离,定量计算方面都要比非靶向全扫结果数据要容易很多。 Order by Date Name Attachments xcms-logo-white • 183 kB • 858 click 2022年7月1日lcmspreproc_slides_1.2 • 136 […]
估计阅读时长: < 1 分钟Order by Date Name Attachments HEStainModelPreviews • 361 kB • 871 click 2022年6月3日13546516212177 • 152 kB […]
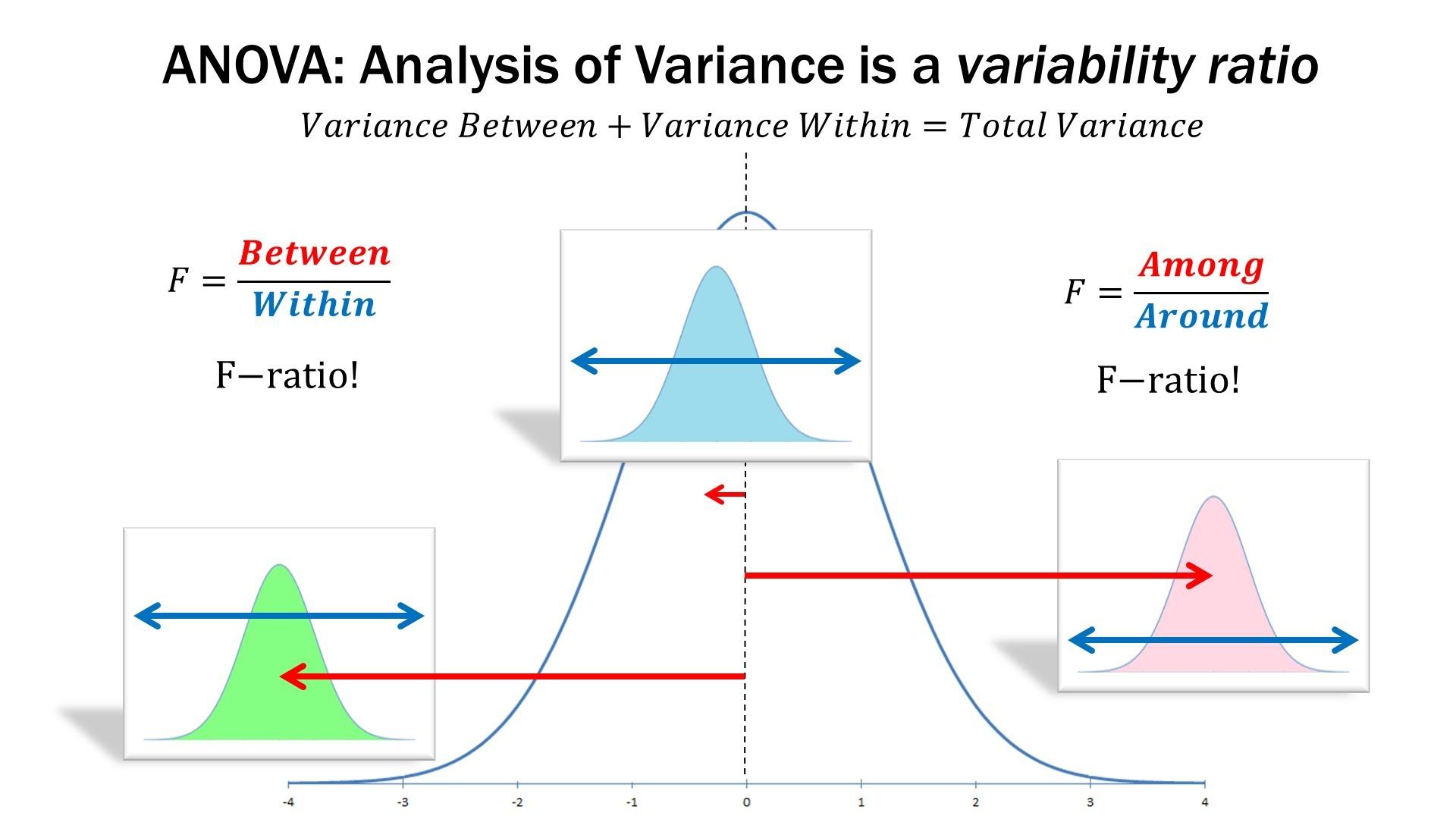
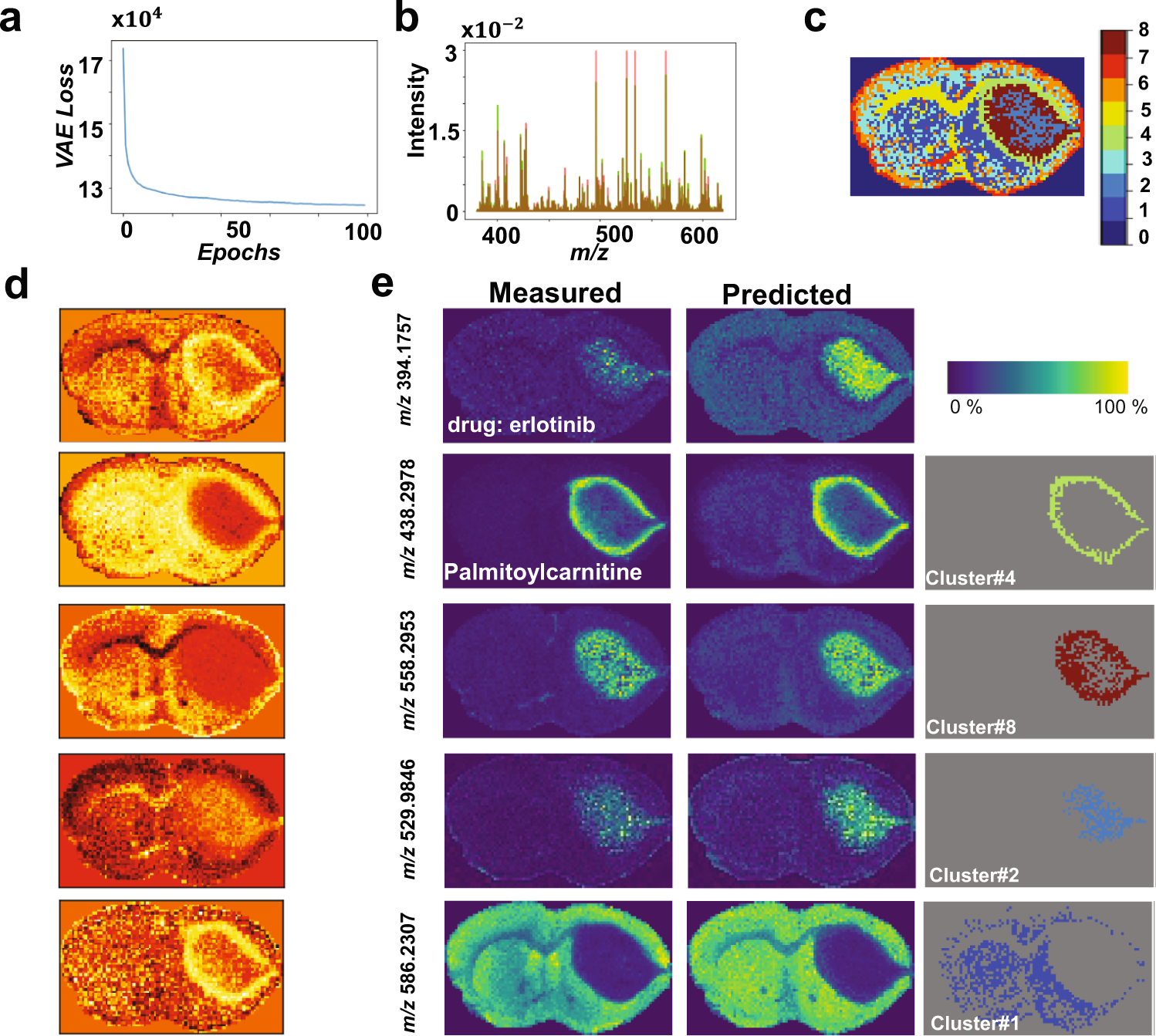
估计阅读时长: 14 分钟一般而言,如果我们在进行组学数据分析的时候,如果想要比较两组数据之间是否存在有差异性,一般是对两两比较的两组数据进行T-检验。但是在代谢组学数据分析领域内,则很多的组学数据分析情况为比较两组以上的数据,寻找差异的biomarker。那这个时候就需要使用上ANOVA统计检验方法了。 Order by Date Name Attachments anova • 105 kB • 1110 click 2022年5月28日ANOVA-screen • 27 […]
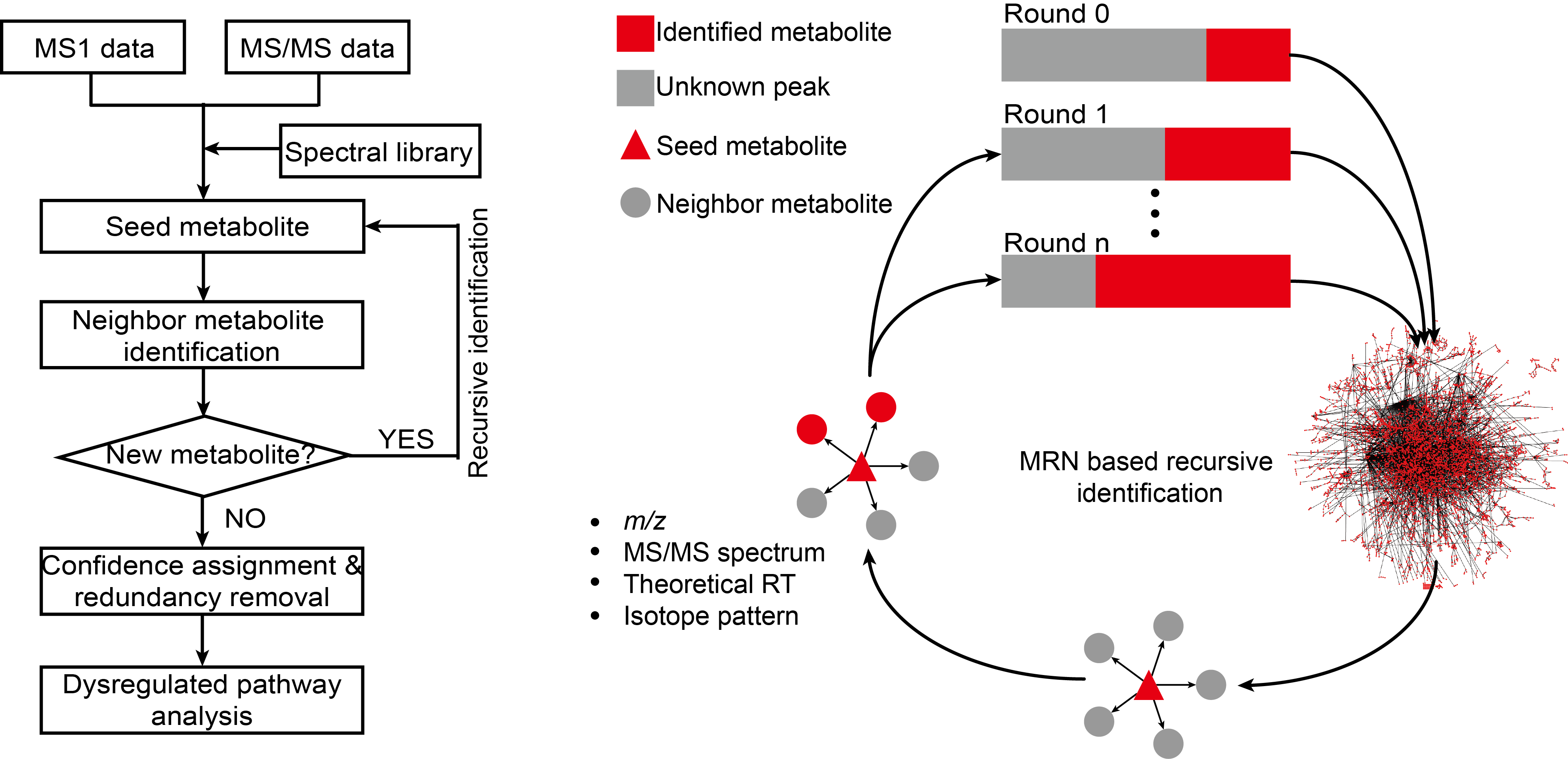
估计阅读时长: 6 分钟访问在线服务: http://metdna.zhulab.cn/ Metabolite identification is the long-standing challenge for liquid chromatography-mass spectrometry (LC-MS)-based untargeted metabolomics. Here, […]
估计阅读时长: 2 分钟在BILIBILI上观看视频:【空间代谢组学】AP-MALDI 质谱成像技术介绍 哈啰,大家好呀,鸽了大半年之后,你们的小姐姐又回来啦。为了更好的制作出质量更高的视频,你们的六神无主鸠小姐姐呀,在这大半年的时间里面一直在努力的学习新技术。经过半年的钻研学习,收获满满。谈到最近几年的热门尖端技术,大家都会谈论到空间转录组和单细胞技术。一般而言,代谢组学的发展要稍微滞后于转录组学研究。最近一年呢,随着空间转录组的热度的降低,空间代谢组的热潮也终于姗姗来迟终于到来了。今天呢,我想要为大家介绍的是在最近几年内出现的,目前比较火热的空间代谢组学研究领域内的质谱成像技术。 Order by Date Name Attachments 3D-MS-imaging-using-dual-beam-and-dual-spectrometer-mode-10-of-single-rat-alveolar • 99 kB • 1040 click 2022年5月6日Microsoft […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?