
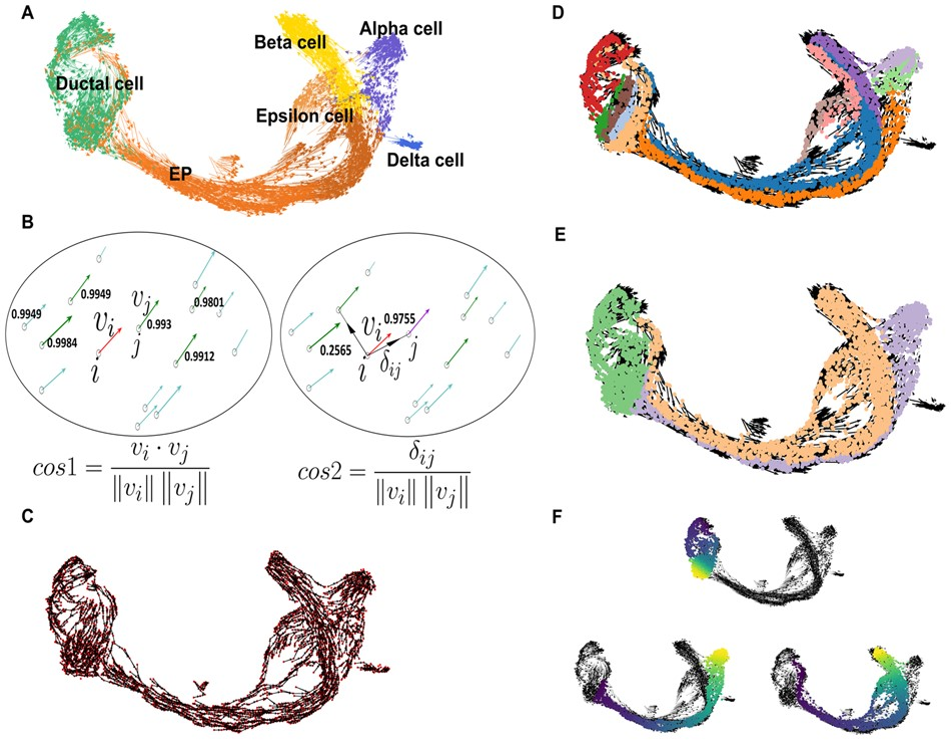
估计阅读时长: 5 分钟单细胞轨迹可以揭示基因调控如何控制细胞命运:大多数细胞状态转变,无论是在发育,重编程或者是疾病异常状态,都以基因表达变化的级联为特征。 Order by Date Name Attachments vec • 722 kB • 996 click 2022年3月17日Slide10 • 14 […]
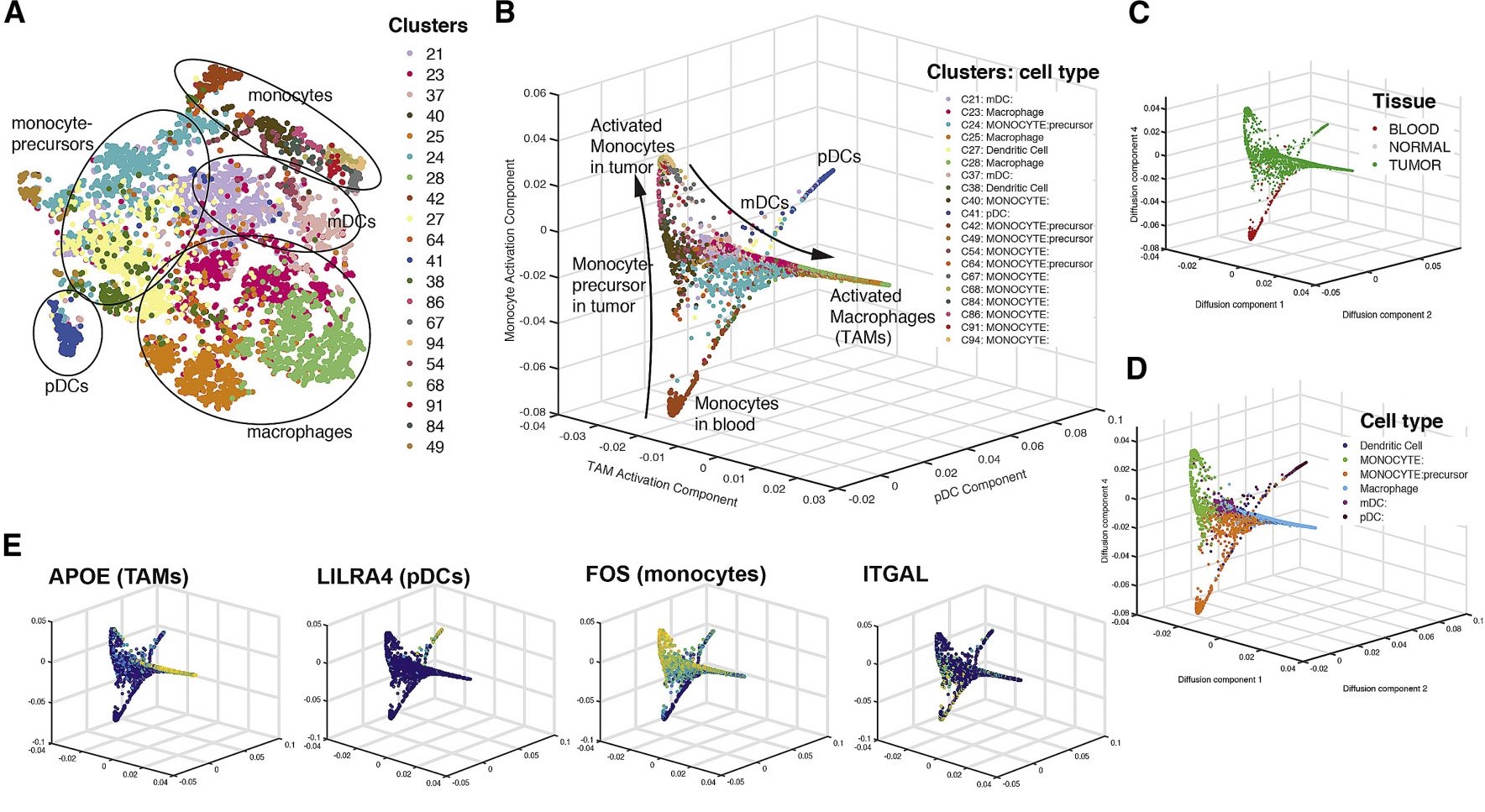
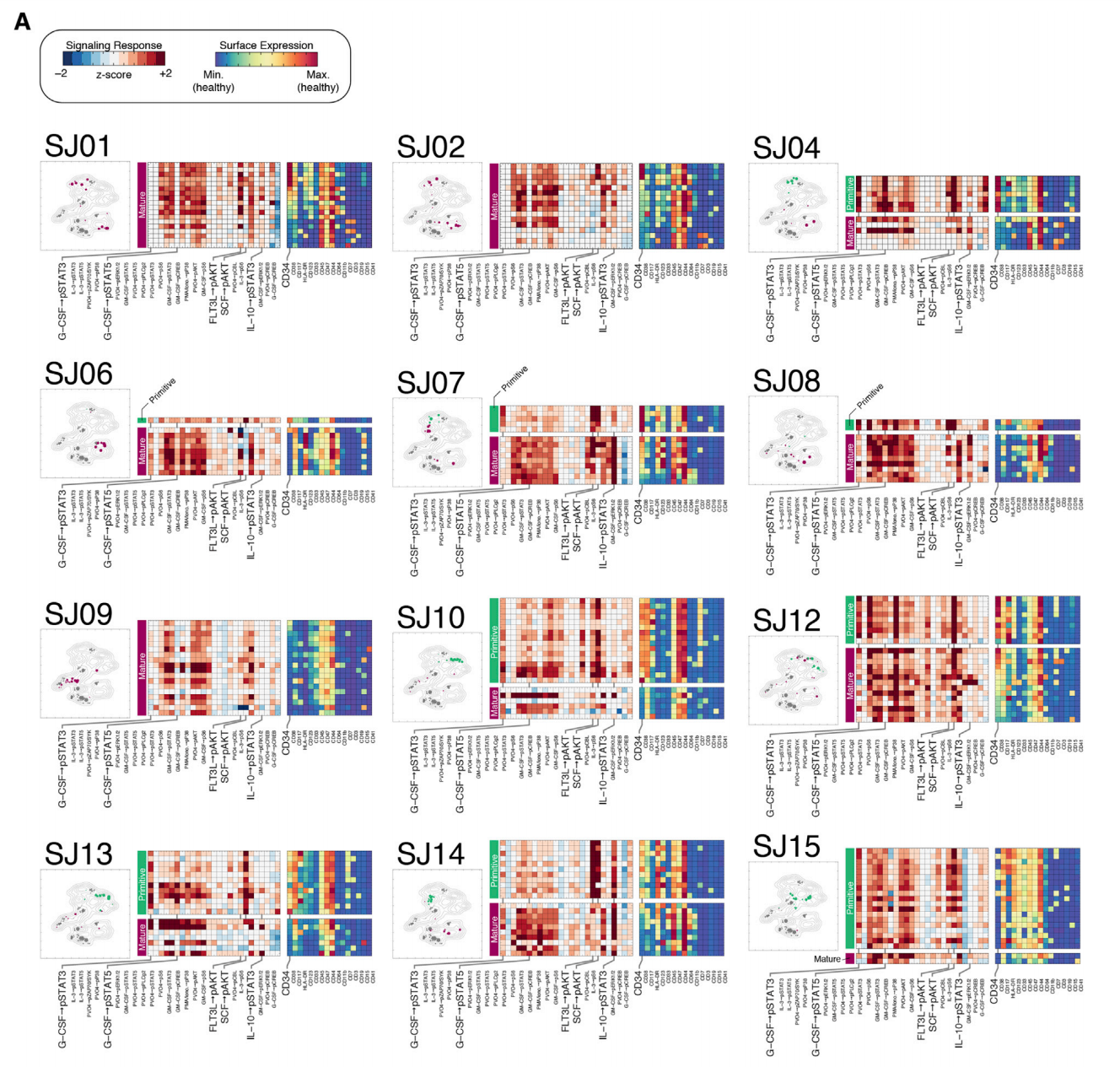
估计阅读时长: 14 分钟https://github.com/rsharp-lang/ggplot 之前在阅读一篇单细胞组学数据分析的文献,觉得在文献之中有一些三维散点图用于展示降维聚类结果的效果非常的好看。于是自己在R#语言之中的ggplot程序包的2D绘图的功能基础之上,进行了三维图形数据可视化功能的开发。 (A) t-SNE map projecting myeloid cells from BC1-8 patients (all tissues). Cells are colored […]
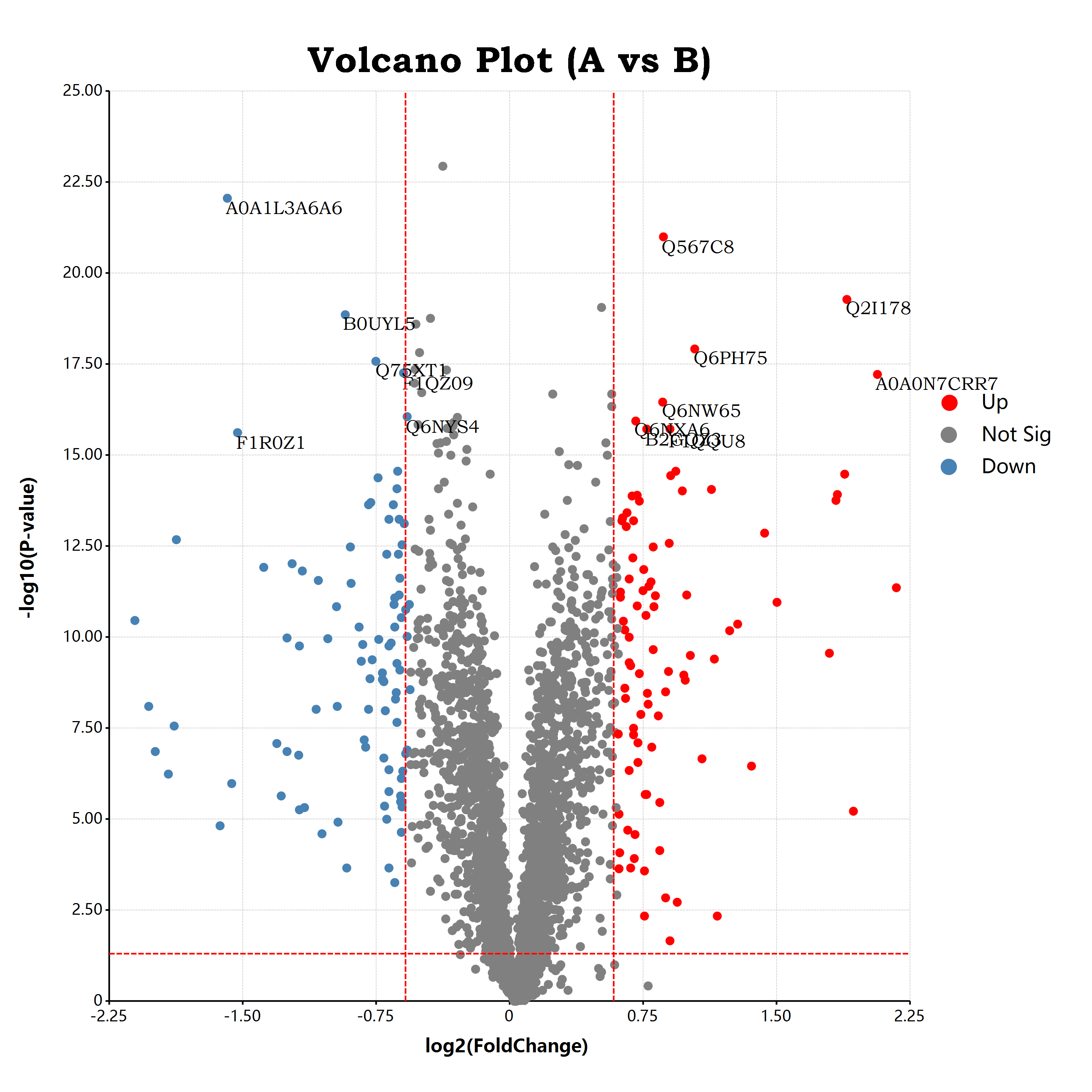
估计阅读时长: 17 分钟https://github.com/rsharp-lang/ggplot 接上一篇博客文章中谈到,我们已经通过R#语言之中的ggplot程序包绘制出了一个可以使用的火山图。在这里,我们将会通过在火山图上添加更多的可视化元素来为大家介绍R#语言之中的ggplot程序包的进阶使用方式。 Order by Date Name Attachments volcano • 651 kB • 1102 click 2021年10月9日volcano • […]
估计阅读时长: 11 分钟https://github.com/rsharp-lang/ggplot 在生物信息学中的组学数据分析领域内,有一个非常常见的数据可视化图表:应用于可视化两两组别比对结果的火山图。在火山图之中,X坐标轴一般是log2FC,纵坐标Y轴,则一般是t检验的pvalue的-log10转换之后的值。由于fold change有大于1的值,A/B大于1,表示A的表达量高于B的表达量,反之小于一表示A的表达量低于B的表达量。这样子fold change经过log2转换之后,就会出现负数,散点一般呈轴对称分布在X=0的位置周围。这样子绘制出来的散点图就有点类似于火山喷发的样子了。 Order by Date Name Attachments a679af1eb9ffbfbad48c18d563ea51f3 • 45 kB • 1007 click […]
估计阅读时长: 7 分钟https://github.com/rsharp-lang/ggplot 一张统计图形就是从数据到几何对象(geometric object, 缩写为geom, 包括点、线、条形等)的图形属性(aesthetic attributes, 缩写为aes, 包括颜色、形状、大小等)的一个映射。此外, 图形中还可能包含数据的统计变换(statistical transformation, 缩写为stats), 最后绘制在某个特定的坐标系(coordinate system, 缩写为coord)中, 而分面(facet, 指将绘图窗口划分为若干个子窗口)则可以用来生成数据中不同子集的图形。 […]
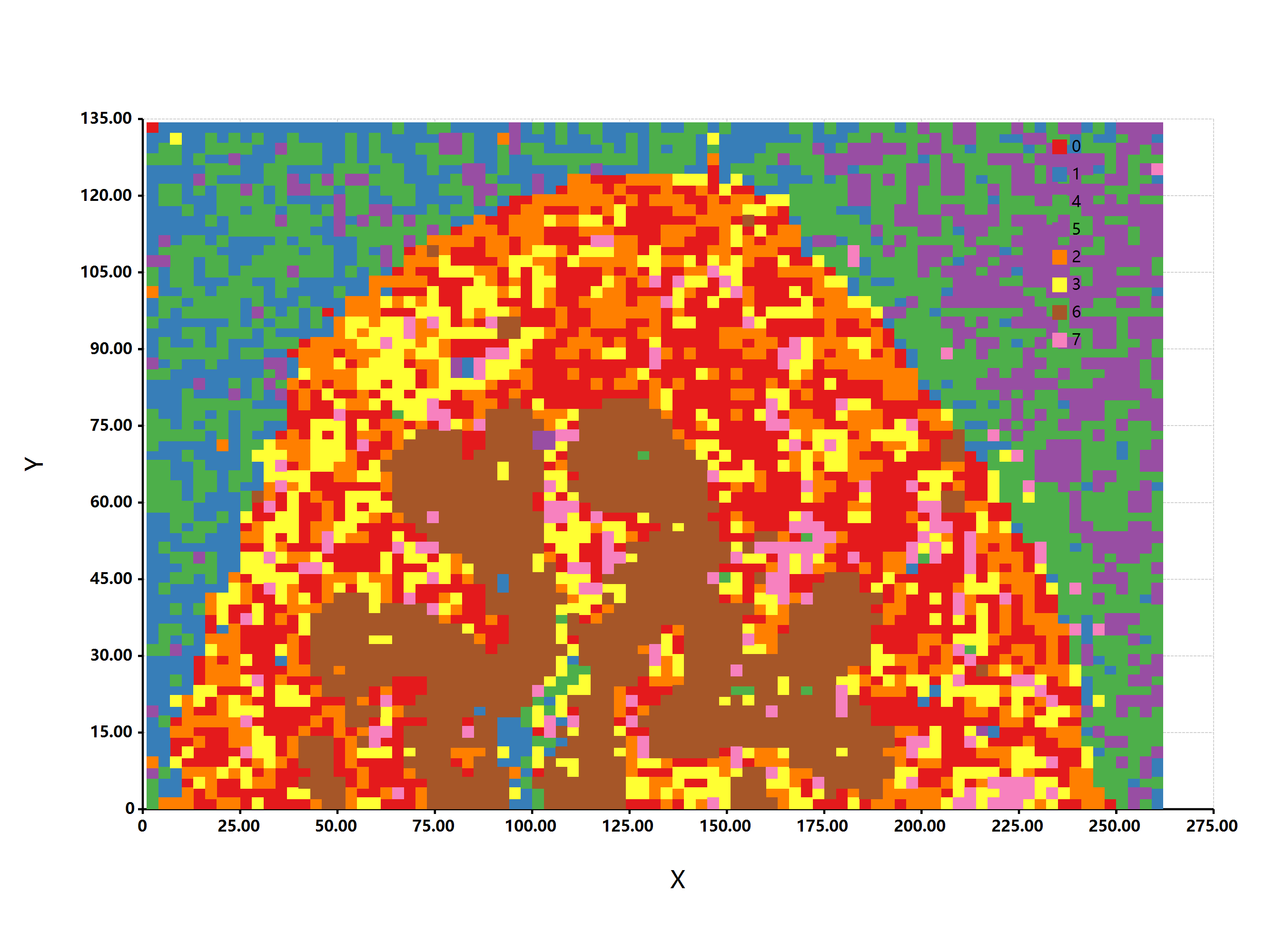
估计阅读时长: 15 分钟https://gcmodeller.org 在这篇博客文章之中,我主要是来详细介绍一下是如何从头开始实现Phenograph单细胞分型算法的。在之前的一篇博客文章《【单细胞组学】PhenoGraph单细胞分型》之中,我们介绍了Phenograph算法的简单原理,以及一个在R语言之中所实现的Phenograph算法的程序包Rphenograph。在这里我主要是详细介绍在GCModeller软件之中所实现的VisualBasic语言版本的Phenograph单细胞分型算法。 Attachments Rphenograph • 236 kB • 1052 click 2021年9月20日
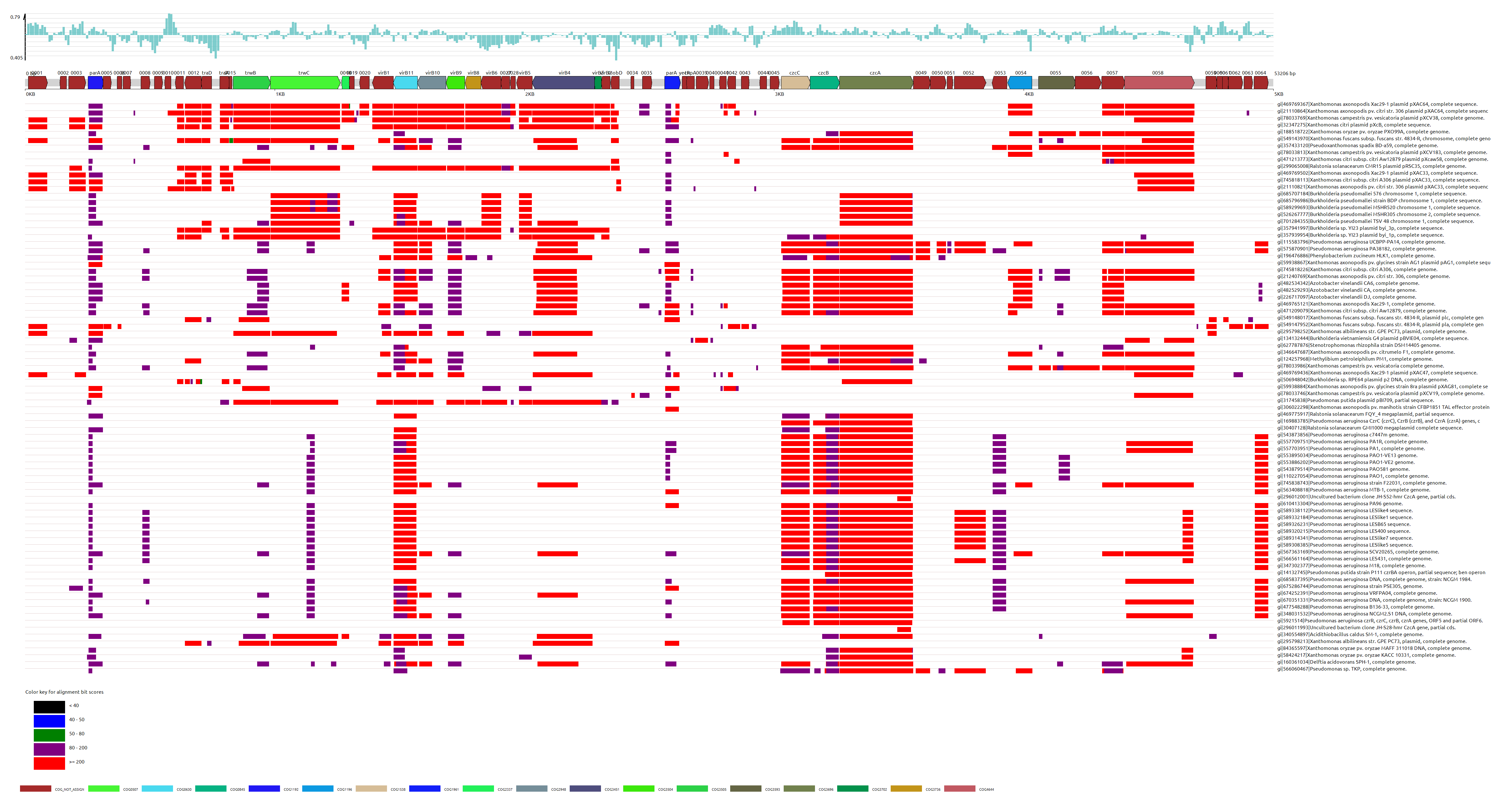
估计阅读时长: 14 分钟在基因组学研究中,将新测序的基因或者针对目标基因组进行基于KEGG代谢通路体系的虚拟细胞建模,都会需要将目标基因组与已知功能基因进行比对注释。KEGG(Kyoto Encyclopedia of Genes and Genomes)数据库通过其KEGG Orthology (KO)系统,为基因功能注释提供了一个强大的平台。KO系统将功能上保守的直系同源基因归为一类,每个KO条目(K编号)代表一个直系同源基因群,这些基因在不同物种中通常执行相似的生物学功能。因此,将新基因的序列与KEGG数据库中的已知基因进行比对,可以推断其可能的KO编号,从而将其功能映射到KEGG通路图或功能层级中。 Order by Date Name Attachments kegg_overview • 313 […]
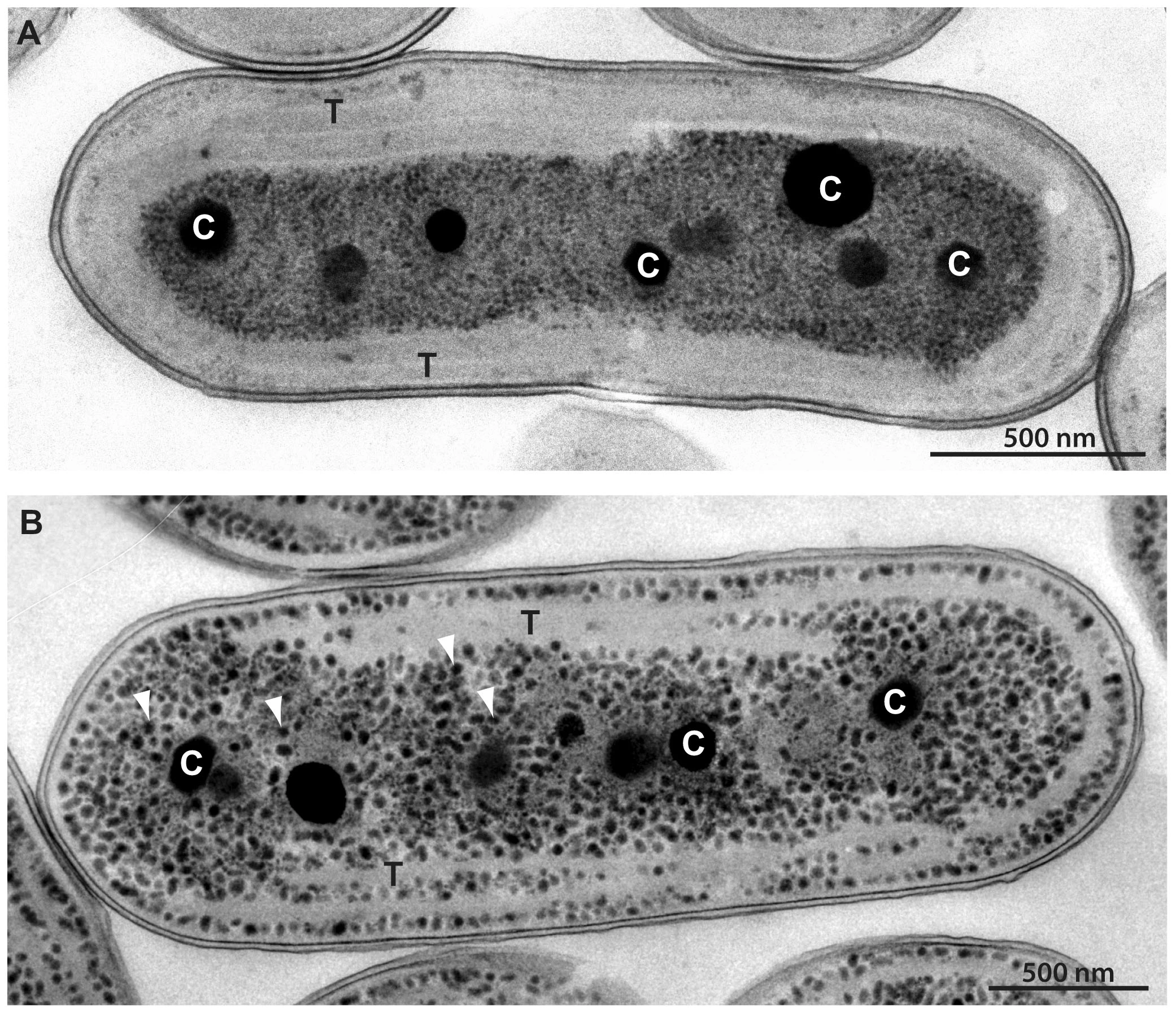
估计阅读时长: 10 分钟https://gcmodeller.org/ 流平衡分析(flux balance analysis)是一种可以用来构建和模拟分析基因组级别的代谢网络的数学方法。流平衡分析是系统生物学(system biology)的一个重要的分析手段。不同于以湿实验的代谢通量分析(metabolic flux analysis, MFA),FBA是用数学方法对代谢网络里的代谢流进行拟合分析。 Order by Date Name Attachments Electron micrographs of […]
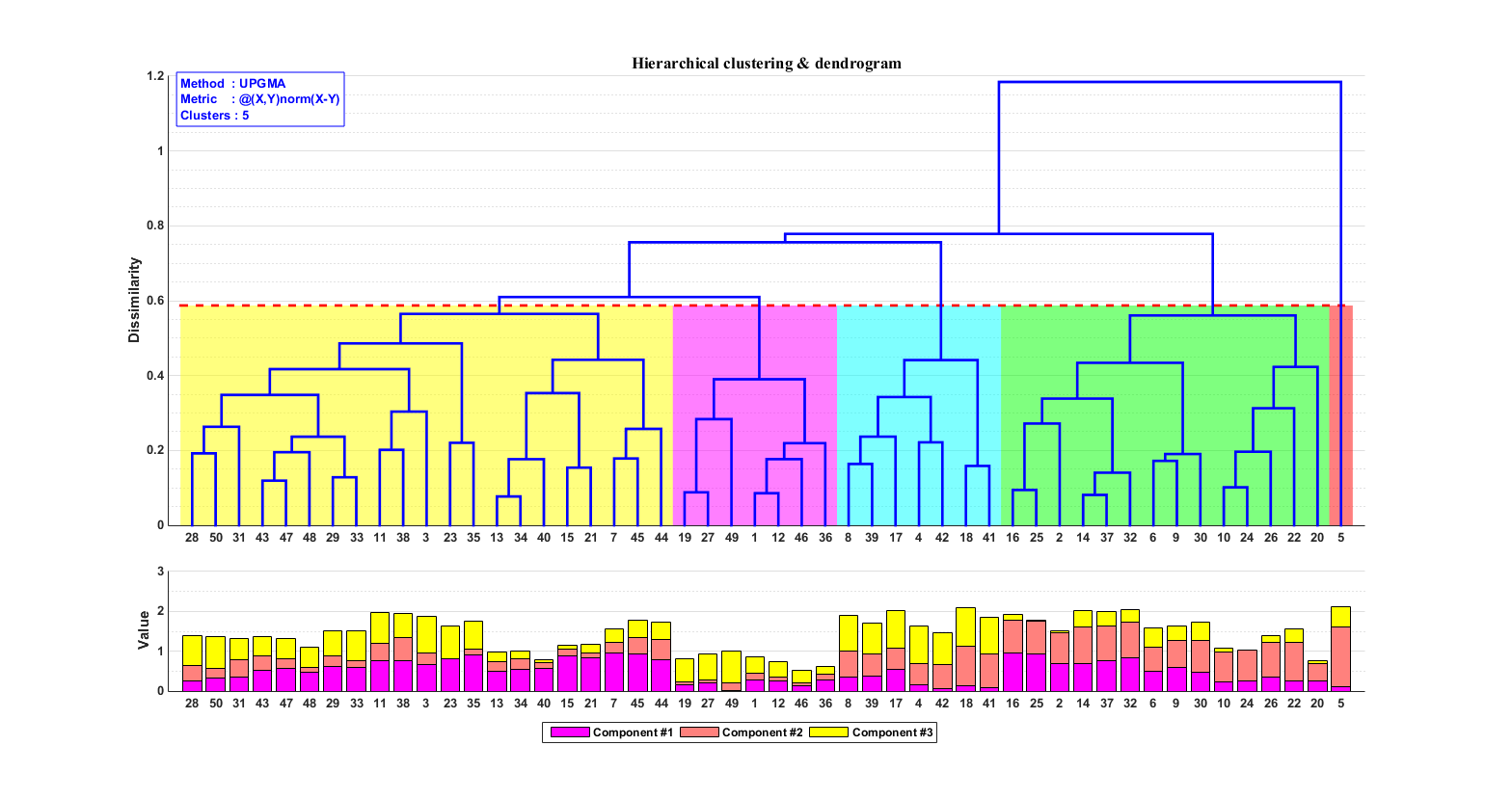
估计阅读时长: 14 分钟https://github.com/xieguigang/sciBASIC 层次聚类通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。基于层次聚类分析,我们可以初步可视化我们的一些原始数据: 例如对样本的层次聚类分类,可以让我们了解到样本在分组之间以及分组内的异质性。 对生物序列进行基于相似度的层次聚类分析,我们可以了解到序列之间的相似性程度或者进化关系 Order by Date Name Attachments metabolome • 14 kB • 1039 click […]
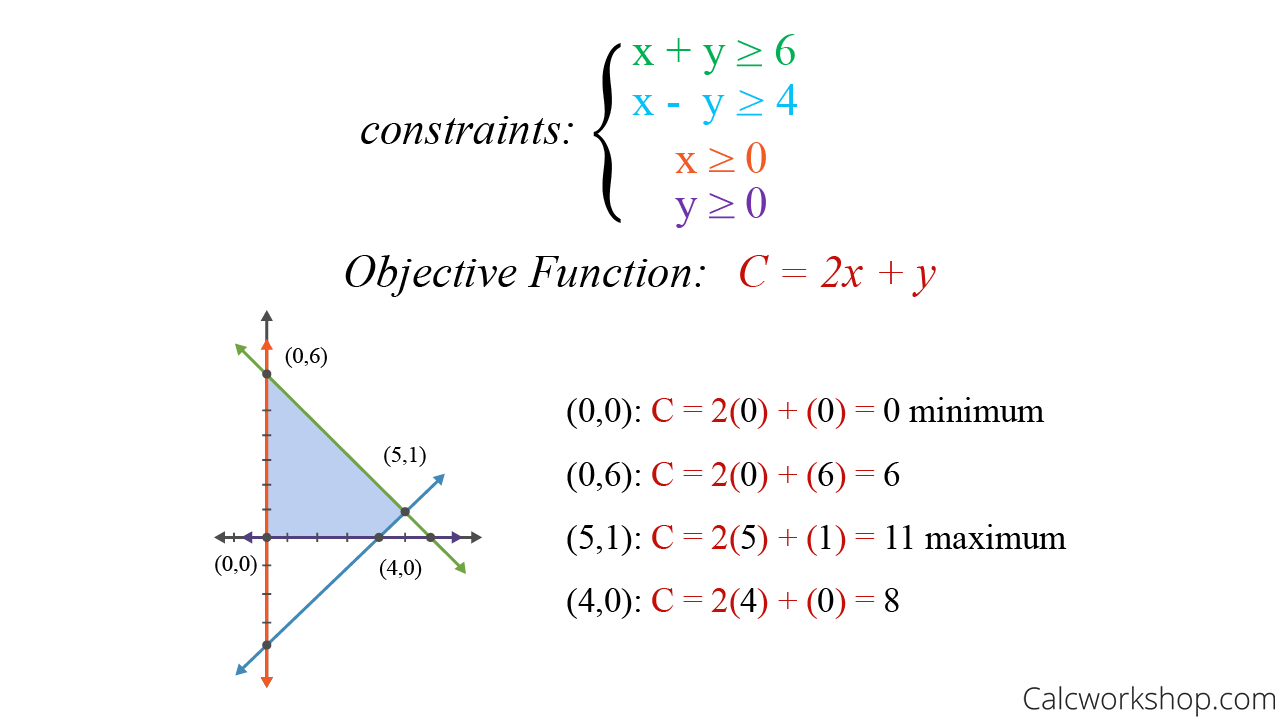
估计阅读时长: 30 分钟https://github.com/xieguigang/sciBASIC/ 线性规划(Linear programming,简称LP)方法起源于20世纪40年代,由美国数学家乔治·丹齐格(George Dantzig)提出,并设计了著名的“单纯形法”。这种优化算法是运筹学中研究较早、发展较快、应用广泛、方法较成熟的一个重要分支,它是辅助人们进行科学管理的一种数学方法。研究线性约束条件下线性目标函数的极值问题的数学理论和方法。通俗点的来讲,就是我们基于这一种数学优化技术,用于在一组线性约束条件下,求解线性目标函数的最大值或最小值(就是在“有限资源”和“一定规则”下,找到“最佳方案”的一种方法)。 Order by Date Name Attachments linear-programming-example • 22 kB • 1065 click […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?