
文章阅读目录大纲
 https://github.com/xieguigang/Darwinism
https://github.com/xieguigang/Darwinism
最近在做一个代谢组学的数据分析程序,由于需要被分析的质谱原始数据的计算量非常大,所以肯定会需要上并行计算。在并行计算中,分为两种模式:线程并行以及进程并行。
关于如果选择脚本代码的并行模式,我在这里借用了matlab文档网站里面的一张图来给大家做参考:

《Choose Between Thread-Based and Process-Based Environments》
Darwinism项目的诞生
对于VisualBasic语言而言,由于其运行时环境并不是天生就是融合于Linux平台的,所以同一套并行化LINQ代码,在Windows上的做线程并行的效果会非常好,但是直接移植到Linux平台上,线程并行的效果会奇差。这大概是因为VisualBasic程序是一种面向对象的程序,在程序的内存内部存在着大量的对象引用,在Linux平台上会因为线程间相互访问这些引用的对象,会频繁的对所引用对象的内存区域加锁造成的吧。
所以,在工作中为了避免因为线程并行化的时候.netcore运行时环境对内存对象的频繁加锁造成的并行效率低下的问题。我选择了自己开发一套应用于.netcore平台的进程并行化的并行库,用于VisualBasic语言在Linux平台上进行高性能计算程序的开发。这套高性能计算库的源代码开源在Github代码库中,我命名其为Darwinism项目。
之所以命名为Darwinism,是因为这个项目最开始是为了一个使用遗传算法进行机器学习的zika病毒疫情预测分析的数据分析项目而诞生的,因为遗传算法中的染色体的进化一般是可以独立发生的,所以这个算法天生就适合于进程并行化。后面这个代码库项目经过几次迭代后才独立出来有了这个VisualBasic应用程序进行高性能计算开发所使用的并行库。
进程并行化所需要的基本元素
在.net平台上做原生的并行化计算,都是基于线程的并行化。原生的线程并行化计算非常的简单,只需要调用并行化的LINQ查询即可。因为微软在开发.net平台的时候为我们做了很多事,所以我们可以在不用了解任何技术细节的情况下,就可以通过LINQ查询轻松的构建出了一个并行化的高性能计算的应用。
但是因为在Linux平台上,使用线程并行化会因为内存访问的问题,会有点得不偿失,所以我们在开发基于Linux平台的高性能计算应用的时候,一般是选择的进程并行化。进行进程并行化,最常见的一个例子就是R语言里面的parallel foreach
require(foreach);
require(doParallel);
# parallel
envir.exports <- c(...);
n_threads <- as.integer(min(MetaDNA::cluster.cores(), length(identified)) / 2);
if (n_threads < 2) {
n_threads <- 2;
}
cl <- makeCluster(n_threads);
registerDoParallel(cl);
# run data analysis
infer <- foreach(seed = identified, .export = envir.exports) %dopar% {
}
stopCluster(cl);R脚本并行化的例子来自于我之前编写的一个实现代谢物metaDNA注释的一段脚本:metaDNA_iteration.R
一般我们执行上面的一段R脚本中的并行化代码,打开htop查看进程运行会发现我们的R进程之中会一下子多出来了很多的子进程。这些子进程就是在R语言编程中所进行并行化计算所使用的slave节点。
进程并行化的数据传输方案
在最开始进行设计这套并行库的时候,我是使用内存映射的方案来在进程间传递数据的。但是后面实施起来的时候,却发现.netcore中的内存映射的代码在Windows服务器上工作正常,但是Linux平台上却无法工作。所以后面我就修改了数据传输方案从内存映射变更为了现在的使用TCP socket进行数据传输。
最初始的内存映射数据传输模块的源代码,可以阅读Darwinism项目中的这个源文件:MemoryMap/MapObject.vb
在IPCSocket数据传输模块之中,我定义了一个枚举用来定义进行进程间传输数据的协议,在这个协议之中,包含有下面代码所示的进行进程并行化的协议过程:
''' <summary>
''' the IPC parallel protocols
''' </summary>
Public Enum Protocols
GetTask
GetArgumentNumber
GetArgumentByIndex
PostStart
PostResult
PostError
End Enum为了理解上面的计算协议,我们先从进程并行化的初始化阶段说起吧。在进程并行化的初始化阶段,由于我们是新打开了一个进程,新的进程内是空的,即完全无进行科学计算分析的上下文环境的。所以我们在最开始的初始化阶段,会需要通过数据协议将上下文环境从计算的头节点进程分配到新打开的slave进程中去。在Protocols中的前三个Protocol就是为此初始化过程而添加的:
GetTaskGetArgumentNumberGetArgumentByIndex
Private Iterator Function GetParameters(params As ParameterInfo(), n As Integer) As IEnumerable(Of Object)
For i As Integer = 0 To n - 1
Dim par As Object = GetArgumentValue(i)
Dim targetType As Type = params(i).ParameterType
If par Is Nothing Then
Yield par
ElseIf par.GetType.IsInheritsFrom(targetType) Then
Yield Conversion.CTypeDynamic(par, targetType)
ElseIf par.GetType Is GetType(SocketRef) Then
Dim socket As SocketRef = DirectCast(par, SocketRef)
Using buffer As ObjectStream = socket.Open
Yield FromStream(buffer)
End Using
Else
Yield par
End If
Next
End Function上面的三个协议所组成的一个完整的初始化过程,大家可以阅读IpcParallel/TaskBuilder.vb这个源文件中的Initialize
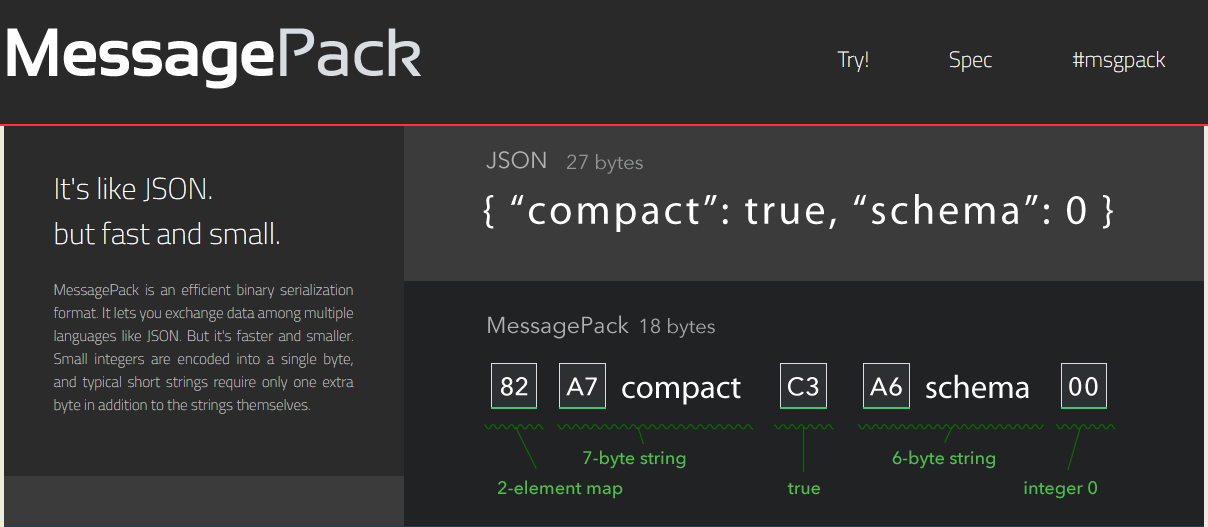
看到这里,可能就会有同学会问了:在VisualBasic的运行时环境里面,我们要怎样将原始数据变换为socket可以传输的二进制数据?总不可能每一个class都要写一个对应的转换到stream以及解析stream的方法把?这个问题不用着急,如果我们已经接触过JSON序列化,对此技术已经很了解的话,那么在这里理解数据传输就很容易了。在Darwinism项目中,数据对象的序列化是采用BSON以及MessagePack这两种序列化的方法来完成的。BSON与MessagePack这两个方案各有利弊,我在这里列举了一些两种数据方案之间的项目比较突出的优缺点:
| 对比点 | JSON | BSON | MessagePack |
|---|---|---|---|
| 内容冗余度 | 很高 (如果传递一个数组,字段名称会造成非常高的数据冗余) |
很高 | 很低(基本无) |
| 序列化/反序列化效率 | 最低 (因为JSON是字符串) |
较快 (对比JSON,无字符串转换过程) |
非常快 |
| 序列化难度 | 很低 | 很低 | 会需要创建schema |
那可能又有同学会问了,既然是进行二进制序列化,为什么不直接使用.net框架中原生的BinaryFormatter进行二进制序列化呢?
这是因为,在我们的VisualBasic程序之中,数据对象一般是以堆的形式保存在内存中,VisualBasic程序就可以在内存中通过组织对象object的引用地址来以通过堆积木的方式堆出一个个的class对象实例的。如果我们直接使用原生的二进制序列化解决方案,得到的只是对象在内存中的访问地址,而非数据对象的值本身。
这个问题在同一台机器上还不会造成太大的问题。但是假若我们需要将目标计算函数放在不同的服务器上进行集群计算呢?在集群中的服务器是不可能读取头节点所处的服务器内存中的对象的。所以在这里原生的二进制序列化方案就gg了。
具体的序列化代码,大家可以阅读handleSerialize函数。在这个函数中,会首先尝试在方法的哈希表中查找用户自定义序列化函数,如果找不到再进行BSON序列化;对于反序列化过程handleCreate,也是遵循着与序列化一样的规则来处理需要传递到Slave节点上的对象数据。
执行目标函数
既然我们已经弄明白了整个计算的初始化过程了,那现在就可以通过反射中的MethodInfo.Invoke
- 先通过.net的反射api加载Assembly文件;
- 然后按namespace和名称查找到对应的TypeInfo;
- 之后就可以按照名称找到对应的MethodInfo,即函数本体了;
- 最后呢,就可以调用
MethodInfo.Invoke
在这里需要值得注意的一点是,在IDelegate对象之中,会存在着一个实例对象的加载GetMethodTarget。这个主要是为了执行VB之中的匿名函数而设置的。
那最后函数执行完毕了,我们就可以通过前面所提到的数据传输方案将结果数据进行序列化打包返回给头节点就好了。在返回数据这一过程中,我定义了两个协议 PostResult 和 PostError来用来分别返回结果数据包或者异常错误消息。因为异常对象本质上在.net环境中也是和正常返回的结果数据,都是对象来的,所以我们可以通过同一个方法来返回数据,只不过在这里是使用协议的不同来区别这两种所返回的数据对象。
原始数据的返回函数,大家可以阅读项目源代码里面的PostFinished函数的代码来学习:
Private Sub PostFinished(result As Object, protocol As Protocols)
Dim socket As SocketRef = SocketRef.WriteBuffer(result, emit)
Using buf As ObjectStream = emit.handleSerialize(socket)
Dim request As New RequestStream(
protocolCategory:=IPCSocket.Protocol,
protocol:=protocol,
buffer:=buf.Serialize
)
If TypeOf result Is IPCError Then
Call Console.WriteLine($"post error...")
Else
Call Console.WriteLine($"post result...")
End If
Call New TcpRequest(masterHost, masterPort).SendMessage(request)
End Using
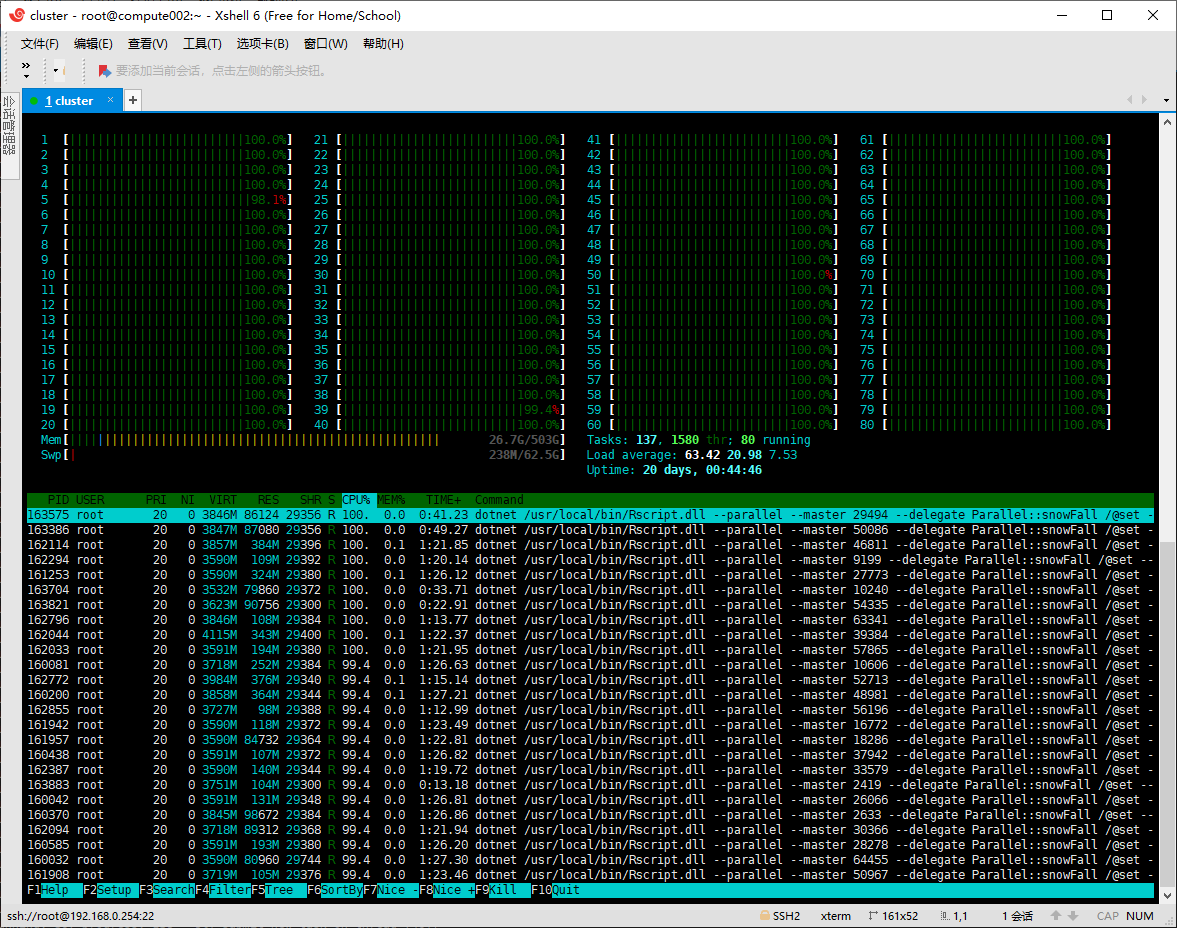
End Sub我们执行一下我们的进程并行化的代码,嗯,效果非常的好,htop命令显示,服务器的所有的资源都已经被用来执行具体的计算过程了,不像.net的并行LINQ那样在LINUX平台上,大部分的CPU资源都被消耗在了系统对内存访问的加锁控制上了(体现在htop的CPU利用进度条上的红色区域的大小)。既然整个计算服务器的计算资源已经被跑满了,我们可以考虑开始进行集群计算的代码库的编写开发工作了。
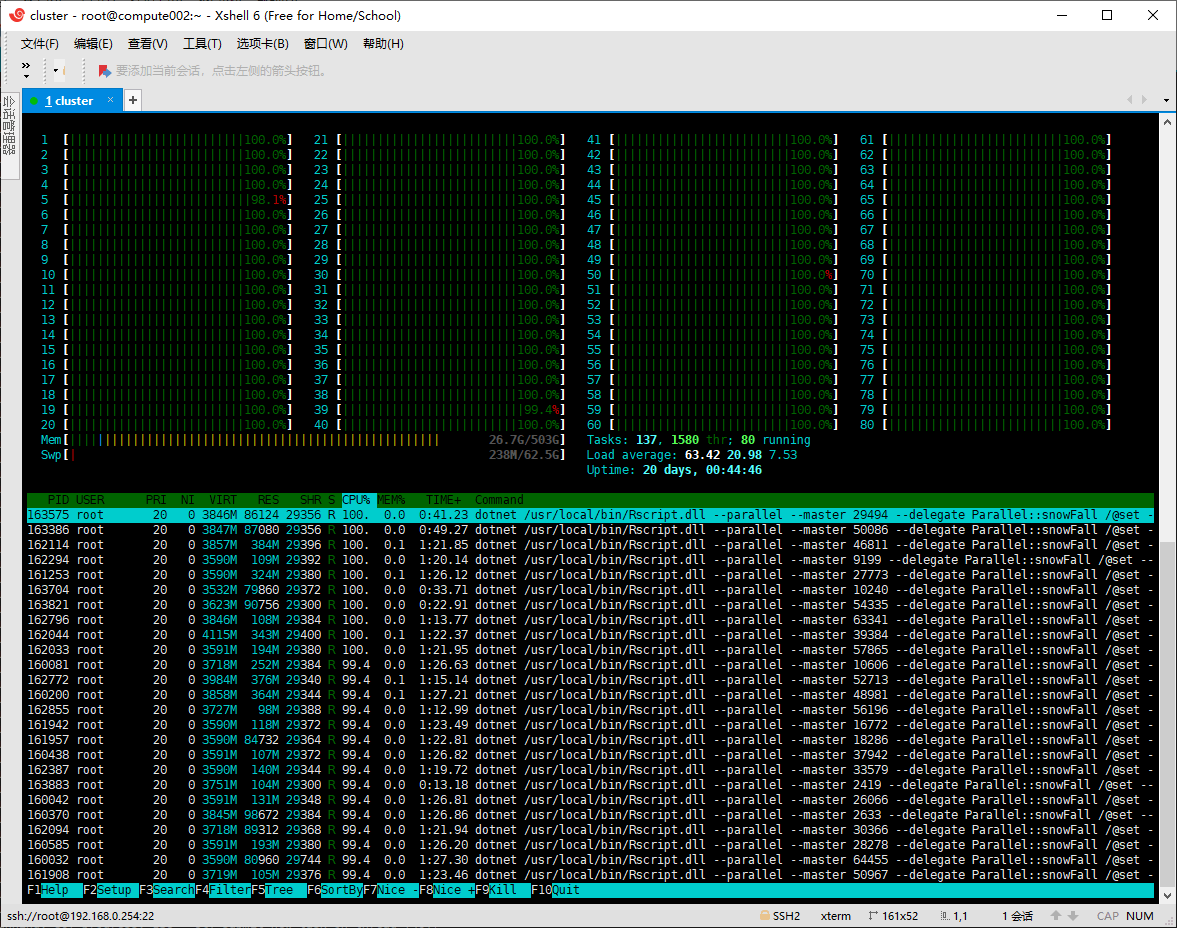
最上方的CPU利用率进度条中,绿色表示用户代码,即实际的计算代码的执行;进度条中红色表示系统代码,即系统对资源的调度过程;蓝色表示低优先级的代码执行,即后台任务;
从上面的htop命令截图可以看出,CPU已经全部被用户代码所利用上了,所以我们所开发的进程并行化代码库对系统计算资源的利用效率非常高,几乎没有出现对内存加锁等的访问问题。
- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

One response
[…] 在上面的工具调用消息数据结构中,我们可以清楚的看见有需要进行调用的工具名称,以及参数列表。当我们拿到这样子的调用信息后,就可以基于一定的规则找到需要执行的运行时中的函数来完成功能的实现。对于.NET平台上,我们一般是使用自定义属性加反射操作来解析相关的名称绑定结果。在.NET平台上对于这样子的一个根据调用信息来进行运行时解析和调用的方法,可以稍微参考《【Darwinism】Linux平台上的VisualBasic高性能并行计算应用的开发》的反射代码方法。 […]