
文章阅读目录大纲
前段时间由于工作的需要,会需要从一些网站上抓取数据用来做数据分析。在原来我进行网页爬虫开发的时候,一般会需要专门针对网页格式,使用大量的正则表达式进行内容的解析。由于你也知道,VisualBasic语言所开发的程序为一个编译好的Assembly文件,所以假若所需要爬取的网页格式变化了,我们就需要对代码做修改和重新编译。这个时候就会非常的不方便。

GraphQuery is a query language and execution engine tied to any backend service. It is back-end language independent.
由于前一段时间在了解Github的api应用开发的时候,从github的文档中了解到可以使用GraphQL进行api的字段解析的操作。于是在网络上搜索了一下GraphQL,发现了GraphQL的一个变种GraphQuery。惊喜的发现GraphQuery语言正是我目前解决工作问题所需要的利器。仔细的阅读了一下GraphQuery作者在CodeProject上的文章《GraphQuery - Powerful Text Query Language》,模仿着GraphQuery的设计,自己编写了一个改进型的GraphQuery复杂文本解析引擎作为一个原始数据处理引擎模块添加进入了sciBASIC框架内部模块,开源在Github项目之中。
GraphQuery语法简明教程
GraphQuery语言在语法上有点类似于JSON,这个和GraphQL基本上保持着一致,其可以直接是一段最基本的文本,也可以是一个包含若干个member的对象,在GraphQuery之中,数组也是可以定义的。GraphQuery一般是用于处理复杂的HTML文本,XML文本等由比较明晰的文本结构的文本数据。
申明数据结构
前面提到过,GraphQuery的查询定义和JSON类似,所以我们最开始编写GraphQuery查询的时候,推断先观察文本结构,编写出一个类似于JSON的数据结构作为查询的框架。例如,按照GraphQuery原作者的文章中的描述,我们对文章里面的Book数据的查询解析编写出了下面一个最基础的查询数据结构作为框架:
{
bookID
title
isbn
quote
language
author{
name
born
dead
}
character [{
name
born
qualification
}]
}然后我们在这个框架的基础上一点点的往里面添加细节。
申明简单文本数据的解析
在GraphQuery之中申明一个最简单的文本解析非常简单,直接对目标文本数据使用text()
# the demo code that show below will retrive
# the text content in the html document as the
# text query result
content text()更加复杂一点的,我们可以先用css选择器函数,选择好目标节点之后,再取出里面的文本数据也是没有问题的,例如下面的一段代码:
# the graphquery code show at here will select the first
# html element in the target DOM tree which its class name
# should contains 'kcfd', and then parse the text content
# in this html node as the text query result.
KCF css(".kcfd") | text() | trim()查看源代码 KCFtext.graphquery
从上面的代码可以看到,我们用到了多个函数来处理目标文本数据,而这些函数使用一个竖线进行分割,是不是非常类似于Linux的Bash脚本编程里面多个命令间的管道处理?没错了,在这里这个竖线符号的含义就是管道处理,即将上一个函数的结果输出作为下一个函数的参数输入(如果你是一个VB.NET开发者,应该非常清楚VB里面也存在着一个非常类似的Extension特性;或者如果你是一个R脚本语言开发者,通过学习和使用dplyr和magrittr包所提供的%>%
那现在我们将上面展示的最简单的第一个例子保存为文件,然后在命令行中执行查询原文作者给的Book数据:

我们可以看到,GraphQuery引擎已经帮我们把文档中的所有可以打印的文本都解析出来了。但是这段纯文本的解析结果很明显不是我们所需要的。
申明数组数据的解析
GraphQuery类似于JSON数据语法,还存在有数组结构:我们只需要使用[]
# get all text in the anchor links
anchor css('a') [
text()
]因为我们只需要解析出一个纯文本的数组集合,所以我们只需要直接在数组的方括号里面填入文本解析text()函数即可申明一个纯文本的数组数据输出
这是我们需要执行查询的目标html文本片段:
<html>
<body>
<a href="01.html">Page 1</a>
<a href="02.html">Page 2</a>
<a href="03.html">Page 3</a>
</body>
</html>我们将上面的例子都分别保存为文件,然后把路径放到命令行中再执行一下。GraphQuery引擎的解析查询输出结果和我们所设想的一样:

申明对象数据的解析
在上面的例子中,我们把每一个a标签链接的文本给解析了出来,那么如果我们还想要一同解析出a标签链接的url字符串呢?这个时候就需要使用GraphQuery的对象申明了:
# use [] for sprcific that the result should be an object
# array: contains multiple object in same data structure.
anchors css("a") [{
# just like the JSON data, use the {} for specific that we are going to
# declare a new object data at here: member name at first and then is the
# GraphQuery parser functions
href attr("href")
text text()
}]在GraphQuery查询语言之中,查询命令之间并不类似于C家族的语言需要任何分隔符(例如分号
或者JSON文档的逗号),直接使用换行回车即可完成查询命令的分割,这个语法特性和VisualBasic语言保持一致;
查询语言的注释,使用哈希符号起始。注释语法仅存在有单行注释,没有块注释语法#
再把上面的查询文本保存到一个文件,然后在命令行中执行一下查询:

好的,GraphQuery查询引擎给我的结果和我们所设想的完全一致!
完整DEMO
既然上面所展示的最开始的那个最简单的纯文本解析的例子无法满足我们的解析需求。那接下来在这个小节中,我们就来编写一个完整的复杂例子来解析GraphQuery原作者所给出的Book数据:
# https://www.codeproject.com/Articles/1264613/GraphQuery-Powerful-Text-Query-Language-3
graphquery
{
# parser function pipeline can be
# in different line,
# this will let you write graphquery
# code in a more graceful style when
# you needs a lot of pipeline function
# for parse value data.
bookID css("book")
| attr("id")
title css("title")
isbn xpath("//isbn")
quote css("quote")
language css("title") | attr("lang")
# another sub query in current graph query
author css("author") {
name css("name")
born css("born")
dead css("dead")
}
# this is a array of type character
character xpath("//character") [{
name css("name")
born css("born")
qualification xpath("qualification")
}]
}从上面所给出的所有的例子不难可以看出,GraphQuery的学习成本非常的低:无非就是先申明最终输出的数据结构,然后为数据结构的解析添加解析函数即可
好嘞,我们再一次把目标文档和查询放到命令行中,执行一下:

结果完全正确,与我们在编写查询的时候所设想的结果完全一致!
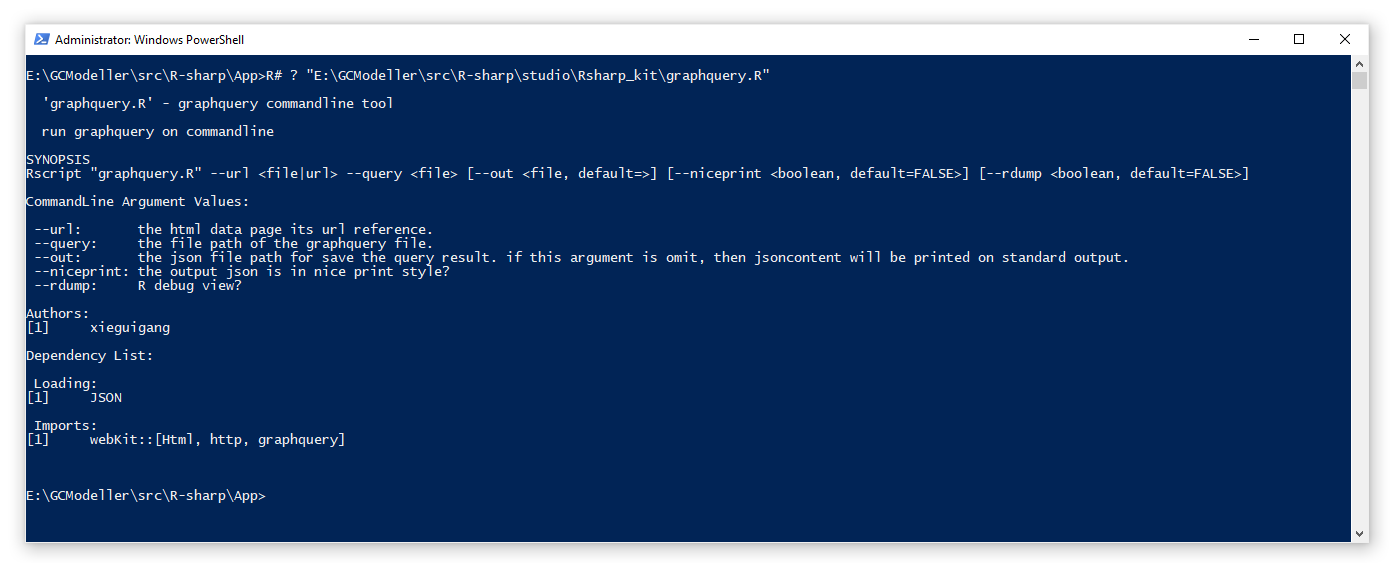
在VB或者R#
R#我们在学习上面的解析示例中,都可以看见,所有的查询测试都是通过执行一个名叫graphquery.R
imports ["Html", "http", "graphquery"] from "webKit";
let runQuery as function() {
url
:> requests.get
:> content
:> Html::parse
:> graphquery::query(graphquery::parseQuery(readText(query)), raw = !Rdump)
;
}可以看到,在上面的R#脚本代码之中,我们最开始先执行一个http请求得到目标文档,然后解析为DOM文档树,最后在这个DOM文档树的基础上执行GraphQuery文本查询
因为会需要执行http请求和DOM文档树的解析,所以在R#脚本之中我们首先引入了两个与浏览器相关的程序模块
对R#脚本所开放的GraphQuery文本查询的api都定义在这个GraphQuery.vb源文件之中了:
<ExportAPI("query")>
Public Function query(document As Object, graphquery As Object,
Optional raw As Boolean = False,
Optional env As Environment = Nothing) As Object
If TypeOf graphquery Is String Then
graphquery = QueryParser.GetQuery(graphquery)
End If
If TypeOf document Is String Then
document = HtmlDocument.LoadDocument(document)
End If
Dim data As JsonElement = New Engine().Execute(DirectCast(document, HtmlDocument), graphquery)
If raw Then
Return data
Else
Return data.createRObj(env)
End If
End Function如果你是一个VisualBasic的应用开发者,那么你可以参考这个graphQueryTest.vb源文件里面的代码示例来使用GraphQuery文本查询:
Imports Microsoft.VisualBasic.Data.GraphQuery
Imports Microsoft.VisualBasic.MIME.application.json
Imports Microsoft.VisualBasic.MIME.application.json.Javascript
Imports Microsoft.VisualBasic.MIME.Html.Document
Dim queryText As String = "/path/to/graphquery".ReadAllText
Dim query As Query = QueryParser.GetQuery(queryText)
Dim engine As New Engine
Dim doc As HtmlDocument = HtmlDocument.LoadDocument(documentUrl)
Dim data As JsonElement = engine.Execute(doc, query)
Call Console.WriteLine(data.BuildJsonString(New JSONSerializerOptions With {.indent = True}))- 单细胞视角下的微生物基因组代谢酶嵌入分析 - 2026年2月25日
- 基因组代谢酶层级嵌入 - 2026年2月23日
- 基因组功能吉布斯LDA主题建模 - 2026年2月23日

2 Responses
[…] 关于在R#环境之中使用GraphQuery进行网页数据查询,大家可以阅读之前的博客文章:《GraphQuery开发》 […]
[…] 与GraphQuery引擎结合在一起,可以通过这个LINQ查询引擎结合GraphQuery脚本直接进行网页数据的查询分析操作 […]