
估计阅读时长: 5 分钟基因组 为了能够实现上面所描述的这种基于EC Number的不同层级的加权嵌入,我们在原来的基因组嵌入工具上添加了一个hierarchical选项,用于支持切换为层级嵌入的操作: Imports Microsoft.VisualBasic.Data.Framework Imports Microsoft.VisualBasic.Data.NLP Imports SMRUCC.genomics.Interops.NCBI.Extensions.Pipeline Public Class GenomeMetabolicEmbedding ReadOnly vec As New […]

估计阅读时长: 18 分钟在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。除了针对降维后的数据进行散点图可视化,我们还可以直接针对向量化嵌入后的原始嵌入矩阵进行聚类,完成聚类结果的可视化。在这里我们主要是基于嵌入的原始结果进行二叉树聚类可视化。 Order by Date Name Attachments community_metabolic_tree • 220 kB • 361 click 2026年2月15日community-local • […]
估计阅读时长: < 1 分钟UPGMA(Unweighted Pair Group Method with Arithmetic Mean,非加权配对组平均法)是一种经典的基于距离矩阵构建系统发育树的聚类算法。其核心思想是假设进化速率恒定(分子钟假说),通过迭代合并距离最近的两个类群(或序列)来构建树。UPGMA算法具有原理简单,计算速度快,易于理解和实现。对于符合分子钟假说(即所有分支进化速率相同)的数据,能给出正确的拓扑结构这些优点。但是其“进化速率恒定”的假设在现实中常常不成立。如果数据存在明显的速率差异(即存在长枝),UPGMA可能会构建出错误的树(拓扑结构错误)。因此,它更适用于进化速率相对均匀的近缘物种或基因的比较。
估计阅读时长: 17 分钟EC Number是国际酶学委员会(IUBMB)制定的一套酶分类编号体系,EC Number采用层级分类法,由4个数字组成,分别代表酶的大类、亚类、亚亚类和序号。例如,“EC 1.1.1.37”中,第一个“1”表示氧化还原酶大类;第二个“1”表示作用于CH-OH基团;第三个“1”表示以NAD+或NADP+为受体的酶;第四个“37”表示特定酶苹果酸脱氢酶。这种层次结构意味着EC编号蕴含了丰富的功能信息,包括酶催化的反应类型和底物/机制。将EC Number嵌入为向量,有助于我们利用机器学习模型进行功能预测、相似性分析等。 Order by Date Name Attachments Capture • 14 kB • 435 […]
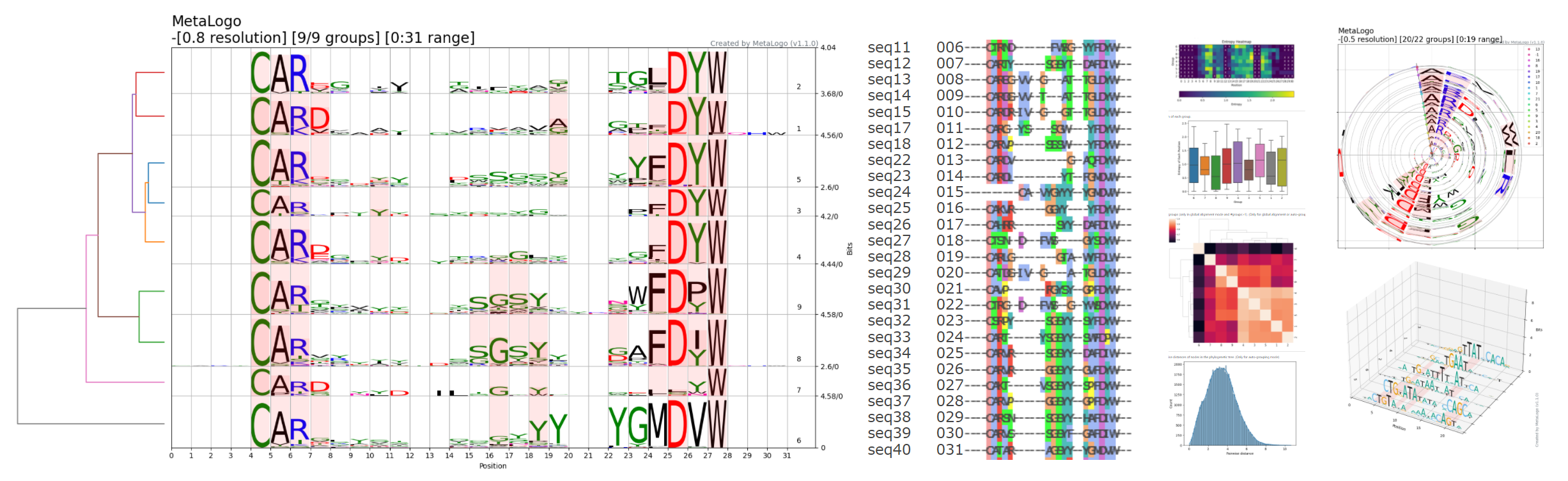
估计阅读时长: 23 分钟Sequence Logo 是一种可视化 DNA 或蛋白质序列保守性的图形表示方法。每个位置(列)上的字母堆叠高度代表该位点的信息含量(以 bits 为单位),而每个字母的高度则与其在该位点出现的频率成正比。高信息量的位置字母堆得高,低信息量的位置则矮甚至接近零。Sequence Logo的绘制遵循信息熵原理,我们可以很直观的通过某一个位置的总高低来了解该处位置的信息含量有多少,高信息量的位置,字母堆的高,一般会出现某一个字符特别高,表明该处非常保守。 位置权重矩阵(Position Weight Matrix, PWM)是描述基因组调控因子结合位点序列模式的核心模型。它通过统计在结合位点序列中每个位置上各核苷酸(或氨基酸)出现的频率,来量化该位置对不同碱基的偏好程度。PWM通常以矩阵形式表示,行对应核苷酸(A、C、G、T/U),列对应序列中的位置,矩阵元素即为该位置该核苷酸相对于背景的权重得分。这一模型简洁且易于计算,因此在转录因子结合位点(TFBS)等调控元件的识别和表征中被广泛采用。 Order by Date Name […]
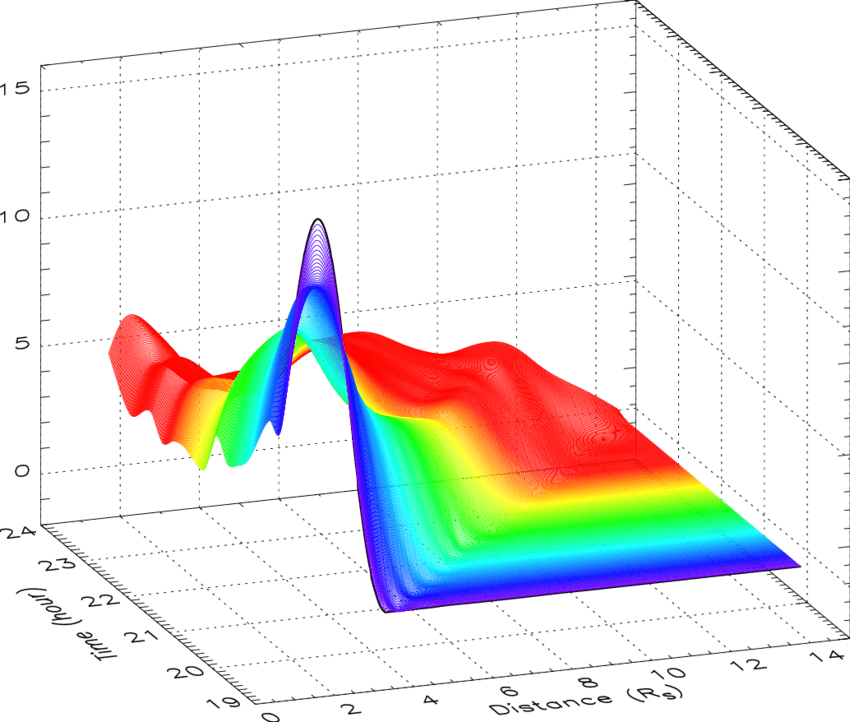
估计阅读时长: 7 分钟热图(Heat Map)是在二维空间中以颜色的形式显示一个现象的绝对量一种数据可视化技术。颜色的变化可能是通过色调或强度,给读者提供明显的视觉提示,说明现象是如何在空间上聚集或变化的。热图有两种完全不同的类别:聚集热图和空间热图。 在聚集热图中,幅度被排列成一个固定单元格大小的矩阵,其行和列是离散的现象和类别,行和列的排序是有意的,而且有些随意,目的是暗示聚集或描绘出通过统计分析发现的聚集。单元格的大小是任意的,但足够大,可以清晰可见。 相比之下,空间热图中某一量级的位置是由该量级在该空间中的位置所决定的,没有单元的概念,现象被认为是连续变化的。 Order by Date Name Attachments 2D-cubic-spline-interpolation-of-mass-profiles-from-1939-to-2354-UT-and-between-16 • 112 kB • 1164 click […]
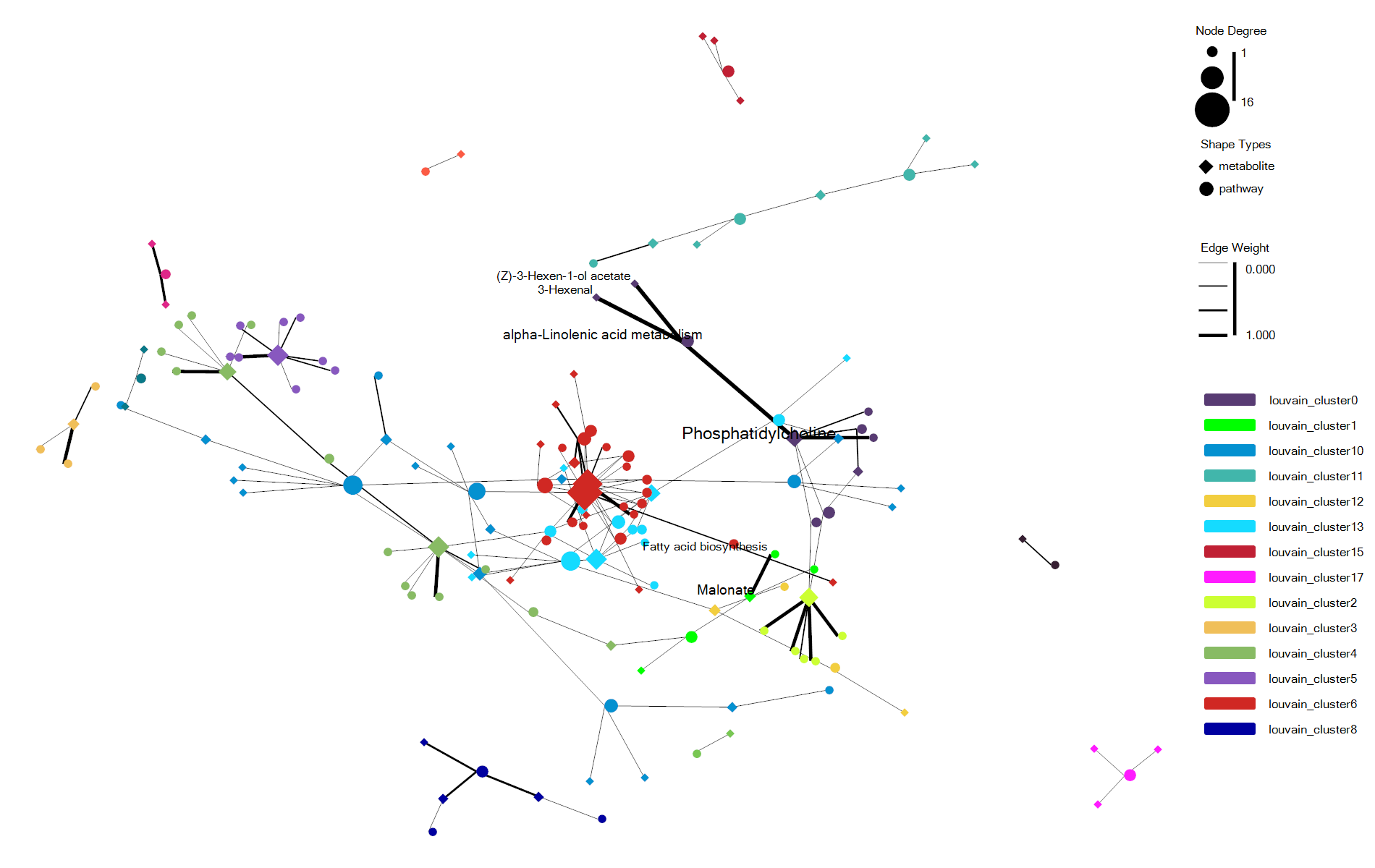
估计阅读时长: 7 分钟https://github.com/rsharp-lang/ggplot 在进行复杂关系的数据集进行可视化的时候,通过网络图的方式进行数据可视化可以让我们非常直观的借助于网络节点的聚集程度之类的布局信息了解到我们的复杂数据的关系结构信息。最近将R#语言之中的ggplot包进行网络可视化的代码库进行了一些更新。基于此功能更新工作,目前在ggplot程序包之中成功集成了ggraph程序包类似的网络可视化功能。在这里做了一些总结分享给大家。 Order by Date Name Attachments enrichNetwork_ggraph • 70 kB • 917 click 2022年6月1日enrichNetwork_ggraph2 • […]
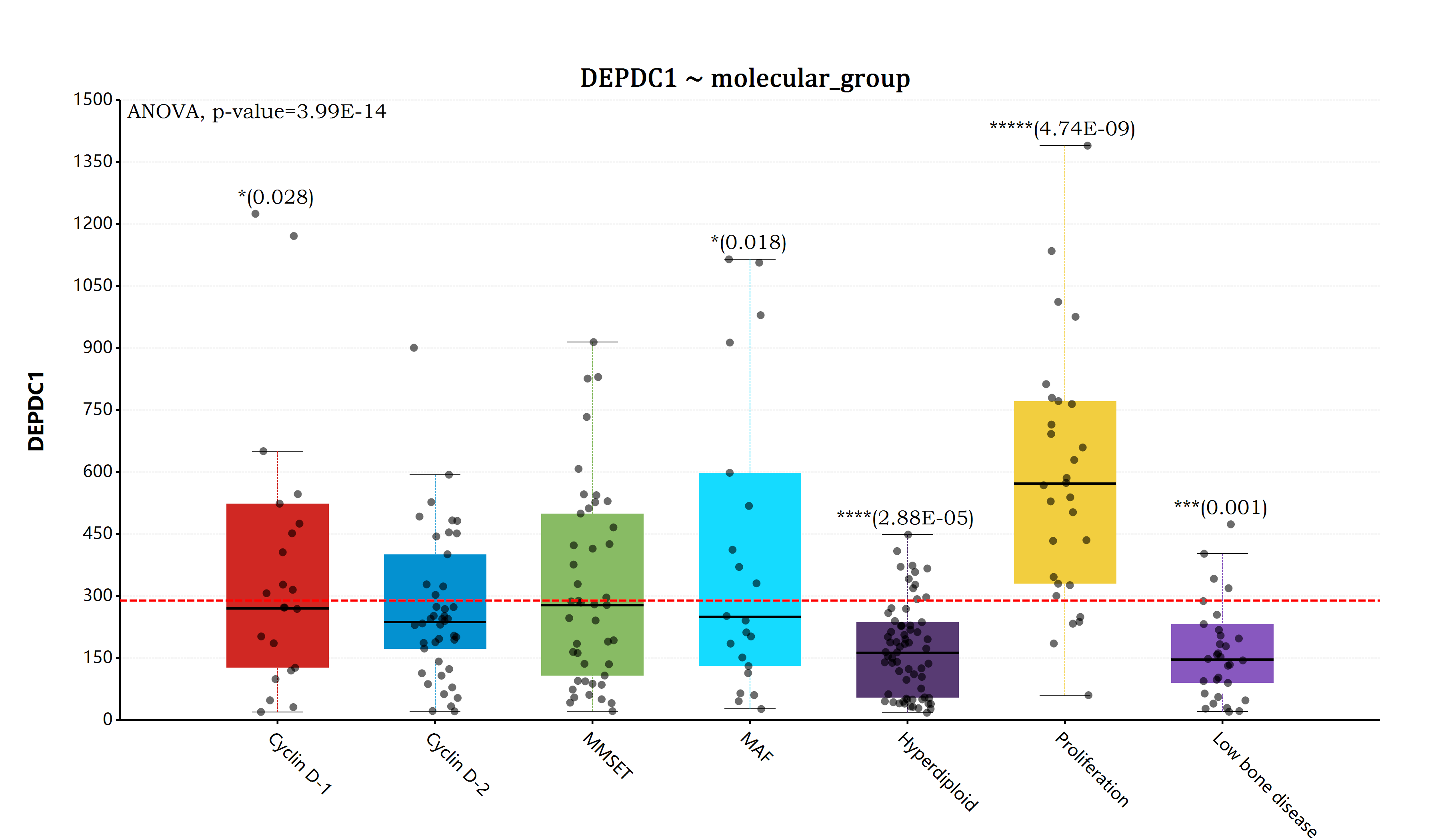
估计阅读时长: 14 分钟https://github.com/rsharp-lang/ggplot 在完成了前面所提到的ANOVA检验模块的代码开发编写工作之后,之前一直悬在我心里面的完善R#语言的ggplot统计作图功能的愿望现在终于实现了。在R#语言之中通过使用ggplot代码库进行相应的数据统计分析作图,目前已经变得和R语言之中的ggplot2程序包那样同样的简单和漂亮。 Order by Date Name Attachments myeloma_bar • 196 kB • 1053 click 2022年5月29日myeloma_box • […]
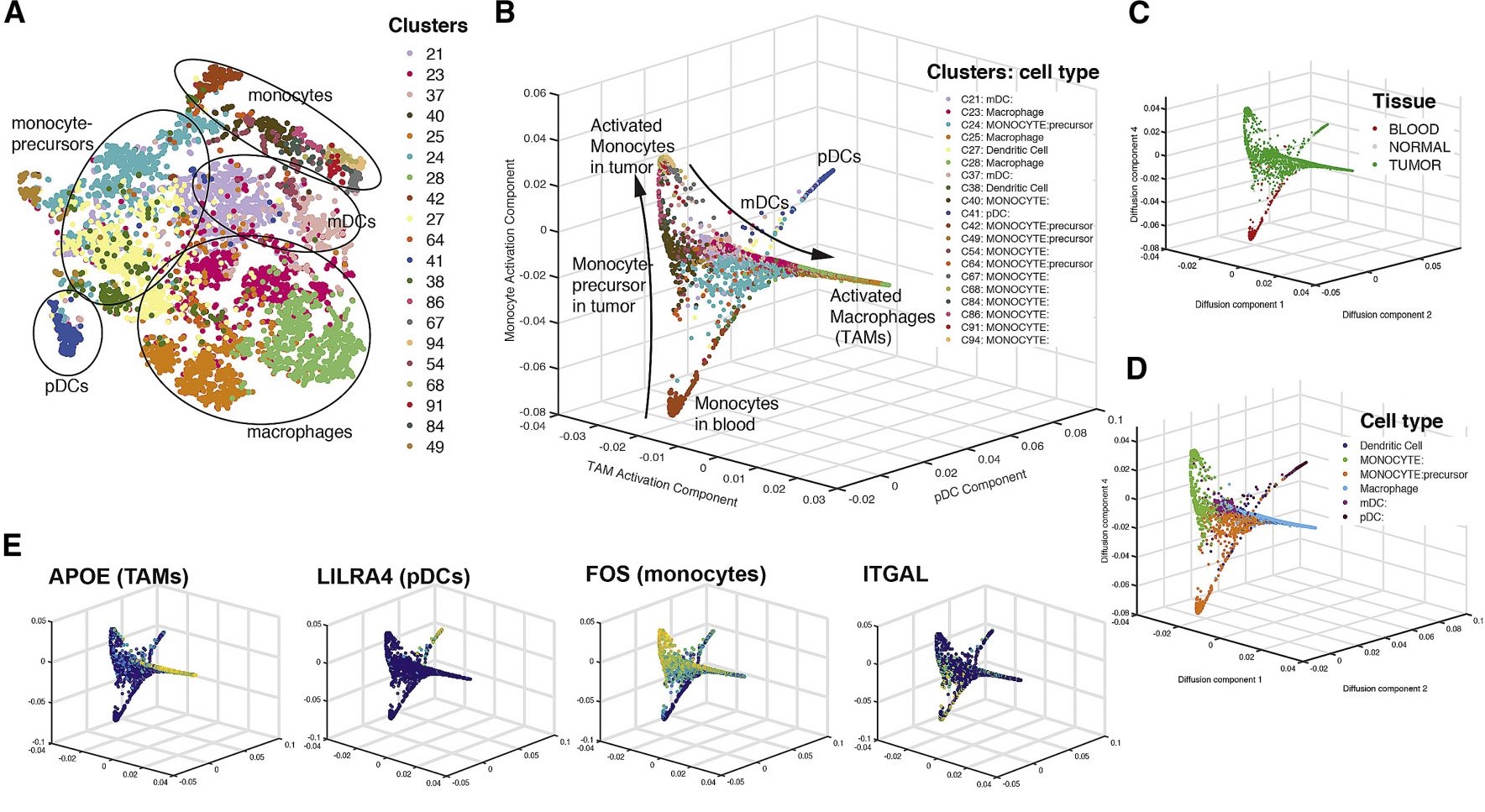
估计阅读时长: 14 分钟https://github.com/rsharp-lang/ggplot 之前在阅读一篇单细胞组学数据分析的文献,觉得在文献之中有一些三维散点图用于展示降维聚类结果的效果非常的好看。于是自己在R#语言之中的ggplot程序包的2D绘图的功能基础之上,进行了三维图形数据可视化功能的开发。 (A) t-SNE map projecting myeloid cells from BC1-8 patients (all tissues). Cells are colored […]
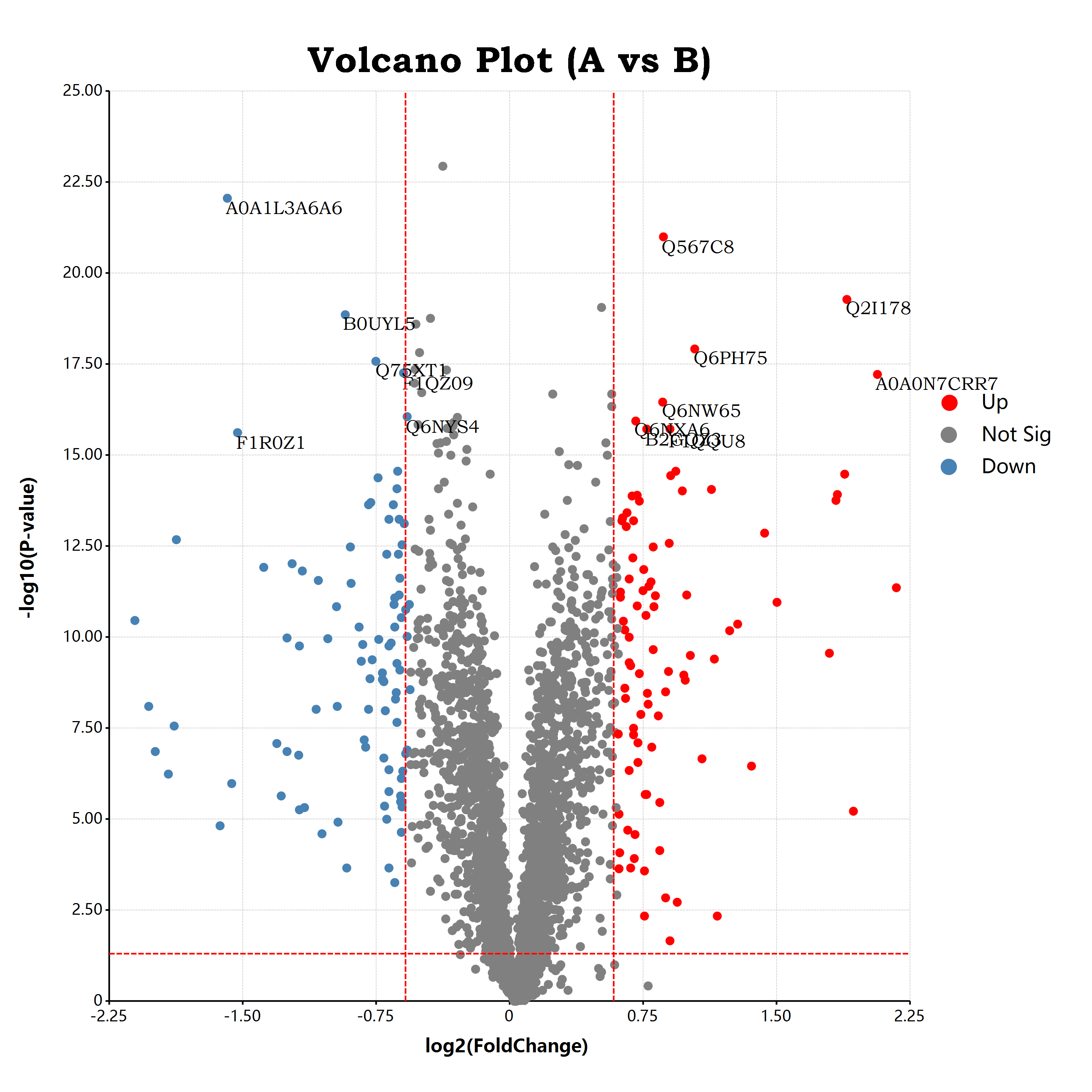
估计阅读时长: 17 分钟https://github.com/rsharp-lang/ggplot 接上一篇博客文章中谈到,我们已经通过R#语言之中的ggplot程序包绘制出了一个可以使用的火山图。在这里,我们将会通过在火山图上添加更多的可视化元素来为大家介绍R#语言之中的ggplot程序包的进阶使用方式。 Order by Date Name Attachments volcano • 651 kB • 1062 click 2021年10月9日volcano • […]

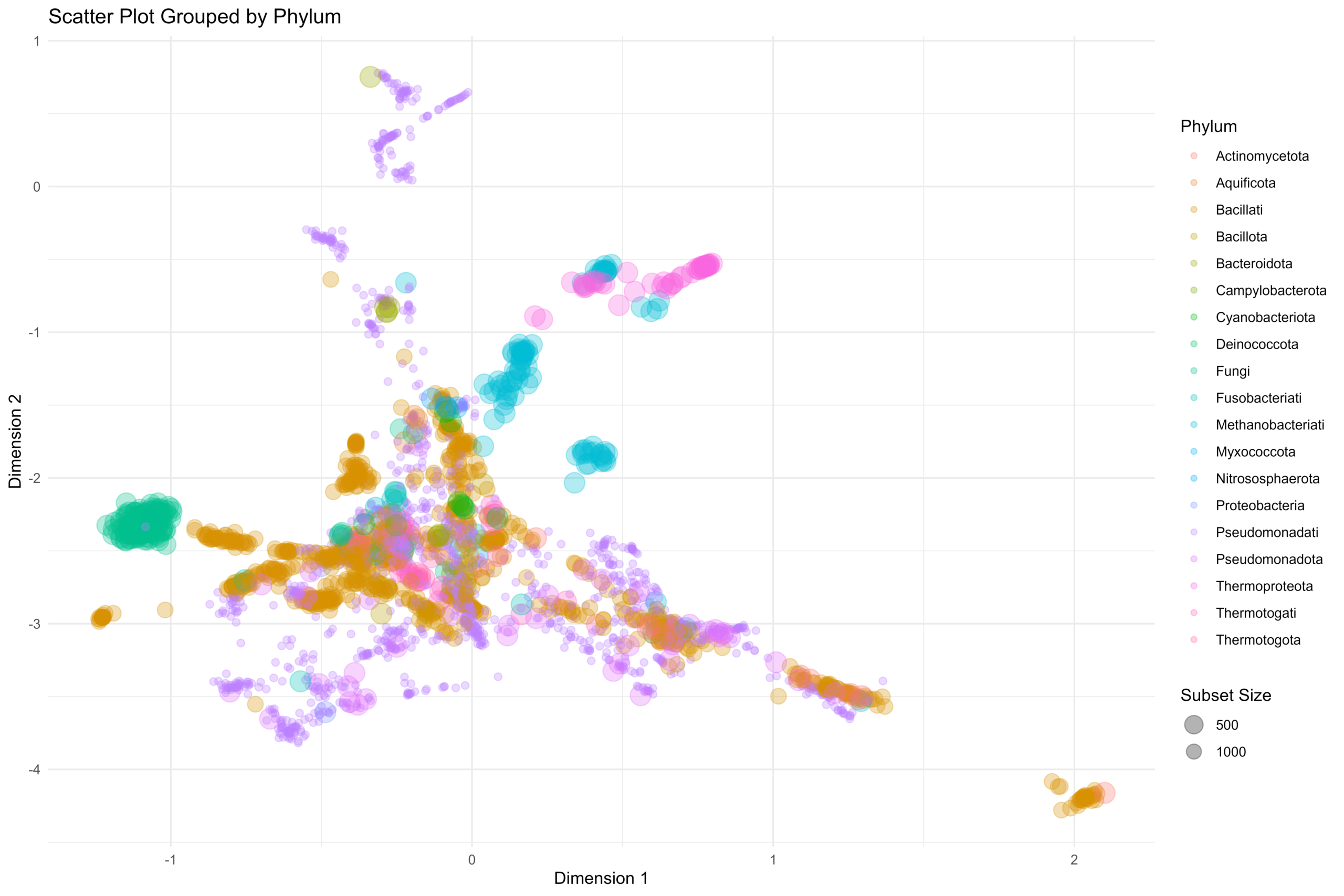
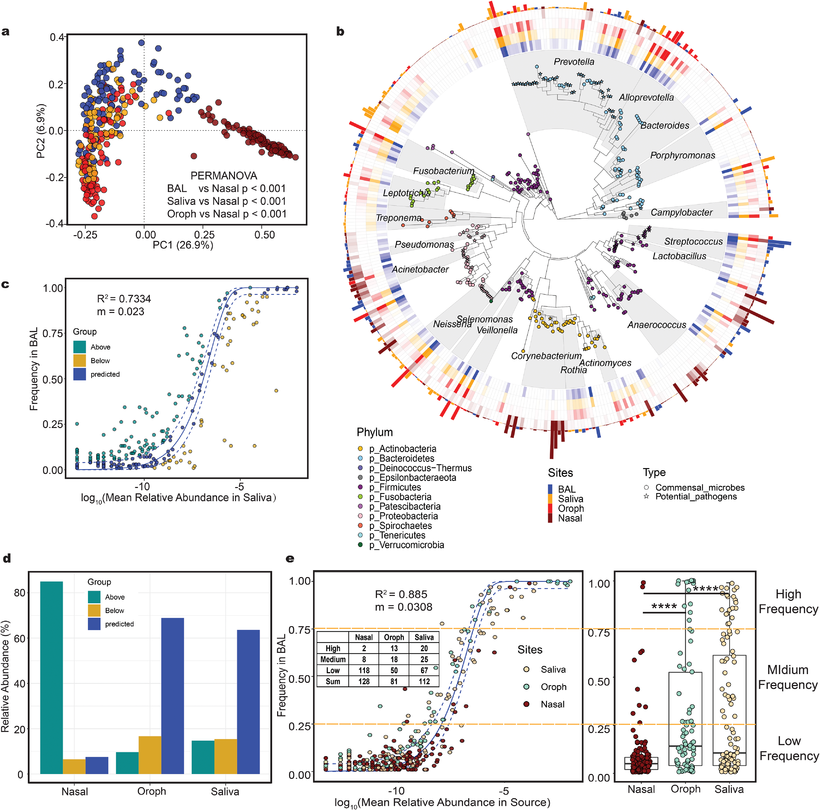
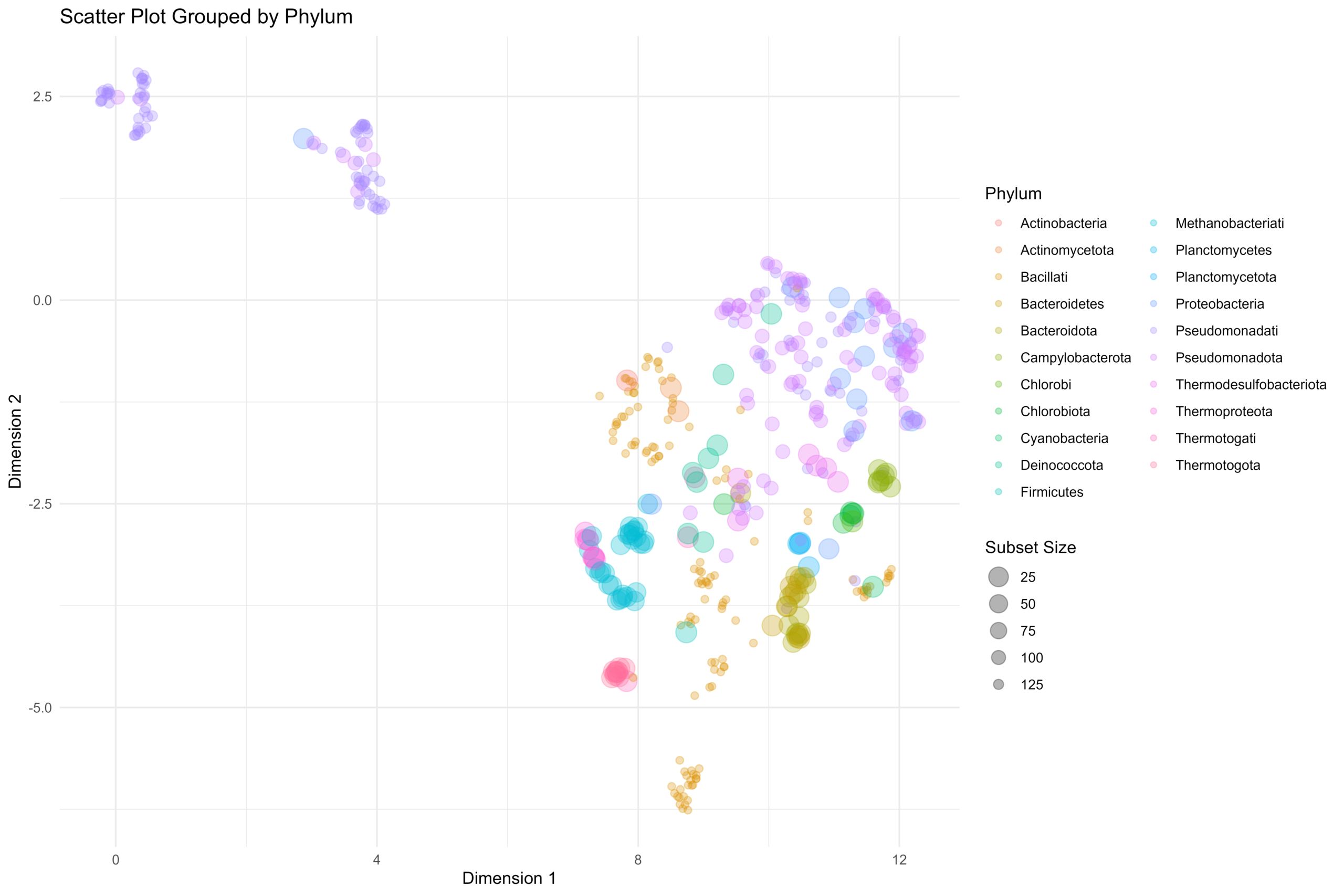
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?