
估计阅读时长: 2 分钟Connected Component Labeling(连通组件标记算法)主要用于识别并标记二值图像中相互连接的像素区域(即连通区域)。 imports "geometry2D" from "graphics"; imports "machineVision" from "signalKit"; let raw = readImage("—Pngtree—five chickens […]

估计阅读时长: 7 分钟Boids算法(也称鸟群/鱼群算法)是Craig Reynolds于1986年提出的群体行为模拟模型,通过三条局部规则模拟鸟类、鱼群等生物群体的自组织运动。在Boids算法中,整个过程通过个体(称为“boid”)的局部交互实现全局有序行为,无需中央控制。每条规则计算个体与邻居的相互作用力,最终合力决定运动方向。Boids算法的精髓在于用局部规则涌现全局智能,其简洁性、可扩展性使其成为连接生物行为与工程控制的桥梁。从《蝙蝠侠》的蝙蝠群到无人机编队表演,从游戏生态到交通优化,Boids持续证明:自然界的简单规则,足以驱动复杂系统的有序演化。 Order by Date Name Attachments Boids • 28 MB • 648 click 2025年8月10日Boids • […]
估计阅读时长: 30 分钟https://github.com/xieguigang/Moira LBM(格子玻尔兹曼方法)凭借其介观模型特性,在流体模拟领域展现出显著技术优势:其碰撞与迁移过程仅依赖局部数据,天然适配GPU并行计算,CUDA实现可达成10–100倍加速比;处理复杂几何边界时无需生成体网格,通过格点标记固体并配合反弹边界即可高效实现,尤其适用于多孔介质等场景;同时,通过扩展分布函数可灵活耦合多物理场,例如引入温度分布函数模拟传热,或采用伪势模型捕获多相流中的相分离现象。尽管在高速或高粘度流动中存在局限,但通过MRT算法优化及GPU硬件加速,LBM已成为微流动、多孔介质、多相流等复杂流体模拟的理想工具,在航空工程等领域已有成功应用案例,其应用前景持续拓展。 Order by Date Name Attachments frame-00093 • 2 MB • 688 click 2025年8月9日ffmpeg • […]

估计阅读时长: 8 分钟 https://github.com/xieguigang/LLMs 已知,现在我们可以成功的和正在运行的大语言模型服务勾搭了,现在能够让大语言模型为我们做些什么。很遗憾的是,由于大语言模型本质上只是一个数学模型,其作用只是针对我们的输入找出最佳的字符输出组合。如果我们没有额外的针对大语言模型进行拓展,我们所勾搭上的大语言模型充其量也只是一个聊天机器人,他既不能帮我们发送email,也不能够帮助我们调节屋内的灯光,只能够做到分析我们输入的文本,然后输出一段最佳的文本。所以我们需要通过针对大语言模型添加额外的拓展来帮助我们实现各种功能。 又已知,大语言模型的本质就是进行文本的结构化分析,那么假如我们的输入信息中包含有某些工具函数的描述信息,而且大语言模型能够正确的分析出我们的输入文本和输入信息中所包含的工具函数之间的对应关系,那么大语言模型的输出就可以专门定向的变换为一种针对输入信息所对应的函数调用的结构化文本信息输出。当运行大语言模型的基础服务捕捉到这种结构化文本(例如json)输出后就可以通过这种结构化文本信息的内容解析结果来调用对应的外部工具,这样子我们就可以让大语言模型来帮助我们完成特定的任务了。这种特性就是大语言模型的Function Calling功能。
估计阅读时长: 10 分钟 https://github.com/xieguigang/LLMs 大语言模型从2023年开始,在最近几年非常的火爆。在最近的一段时间,有大语言模型自动化处理数据的需求,开发了一个基于Ollama服务的客户端来通过大语言模型执行自动化任务。在这里记录下这个开发过程。 Ollama介绍 Ollama 是一个开源的大型语言模型(LLM)服务工具,专注于简化本地环境中大模型的部署与管理。它通过类似 Docker 的框架设计,让用户能以极低门槛在个人电脑或服务器上运行各类开源模型(如 Llama 3、Mistral、DeepSeek 等),实现数据隐私与离线推理的平衡。 Order by Date Name Attachments […]
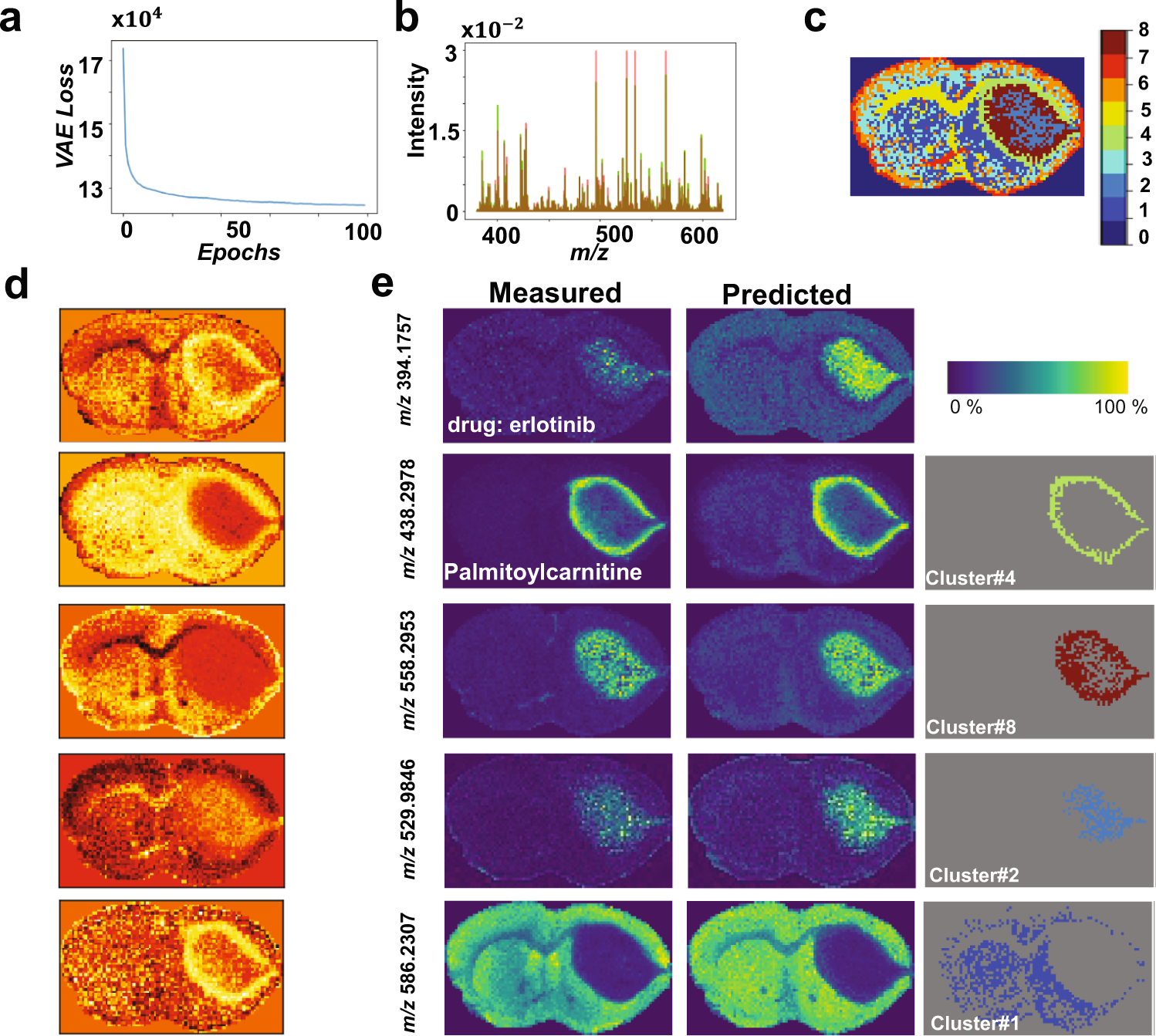
估计阅读时长: 4 分钟基于UMAP工具进行简单的自动化组织分区操作 在这里我们假设已经可以正常的将空间代谢数据导入至MZKit工作站软件之中。假若需要借助于MZKit工作站软件进行切片组织样本的自动化分区操作,相关的功能可以在【MSI Analysis】菜单栏中寻找到。在这里我们打开【Show Map Layer】按钮,选择【UMAP and clustering】功能。 基于降维的组织自动化分区原理 因为降维操作一般是一种特征提取操作,所以经过降维之后,在高维度空间上无法显现的特征,在低维度会呈现出来。在高维度空间散落的相近的数据点,在经过特征提取之后,低维度上会产生相似的特征信息,相互聚集在一簇。这样子我们就可以在低维度空间上通过一些聚类算法讲这些特征进行聚类,最后将聚类特征结果标记到各个散点上的对应的原始成像空间上,我们就可以看见组织分区的结果了。 Abdelmoula, W.M., Lopez, B.GC., Randall, E.C. et […]

估计阅读时长: 11 分钟给定一组n个字符串数组,找到包含给定集合中每个字符串的最小字符串作为子字符串。我们可以假设这个字符串数组中没有字符串是另一个字符串的子字符串。那么基于上面的描述,我们就可以得到下面所示的问题求解目标: let arr[] = ["catg", "ctaagt", "gcta", "ttca", "atgcatc"] // output: gctaagttcatgcatc 上面的问题描述实际上是一个最短超字符串问题(shortest common superstring) Order […]

估计阅读时长: 5 分钟https://github.com/xieguigang/scale_colour_genshin 在用R绘图时,颜色设置是美化过程中不可缺少的一步。在实际绘图时,一般不会一一手动寻找合适的颜色,而是通过一些R包、网站提供好的,美观的颜色组合,即调色板(palette),可供使用。在这里介绍一种通过提取图片主题色的方法来为我们自动生成画图所用的颜色板数据。 Order by Date Name Attachments 383807b4 • 132 kB • 849 click 2023年4月8日faruzan • […]

估计阅读时长: 9 分钟因为一种单一的编程语言并不会覆盖到所有的适用场景的原因,在一个软件工程项目之中,采用多种语言进行混合编程是一种很常见的协作方式。例如,脚本化的语言,其非常适合于进行最顶层的应用开发,就像胶水一样用于将各种组件进行粘贴,但是脚本化的语言自身因为是基于其他的语言所构建,所以执行效率一般不会太好。对于底层组件,我们一般就会需要使用静态编译类型的非托管语言创建用于高性能数据处理的模块。对于这种需求的底层模块,我们一般可以采用C/C++/Rust来编写。 Order by Date Name Attachments rust • 162 kB • 817 click 2023年3月25日dyn-load • 67 […]
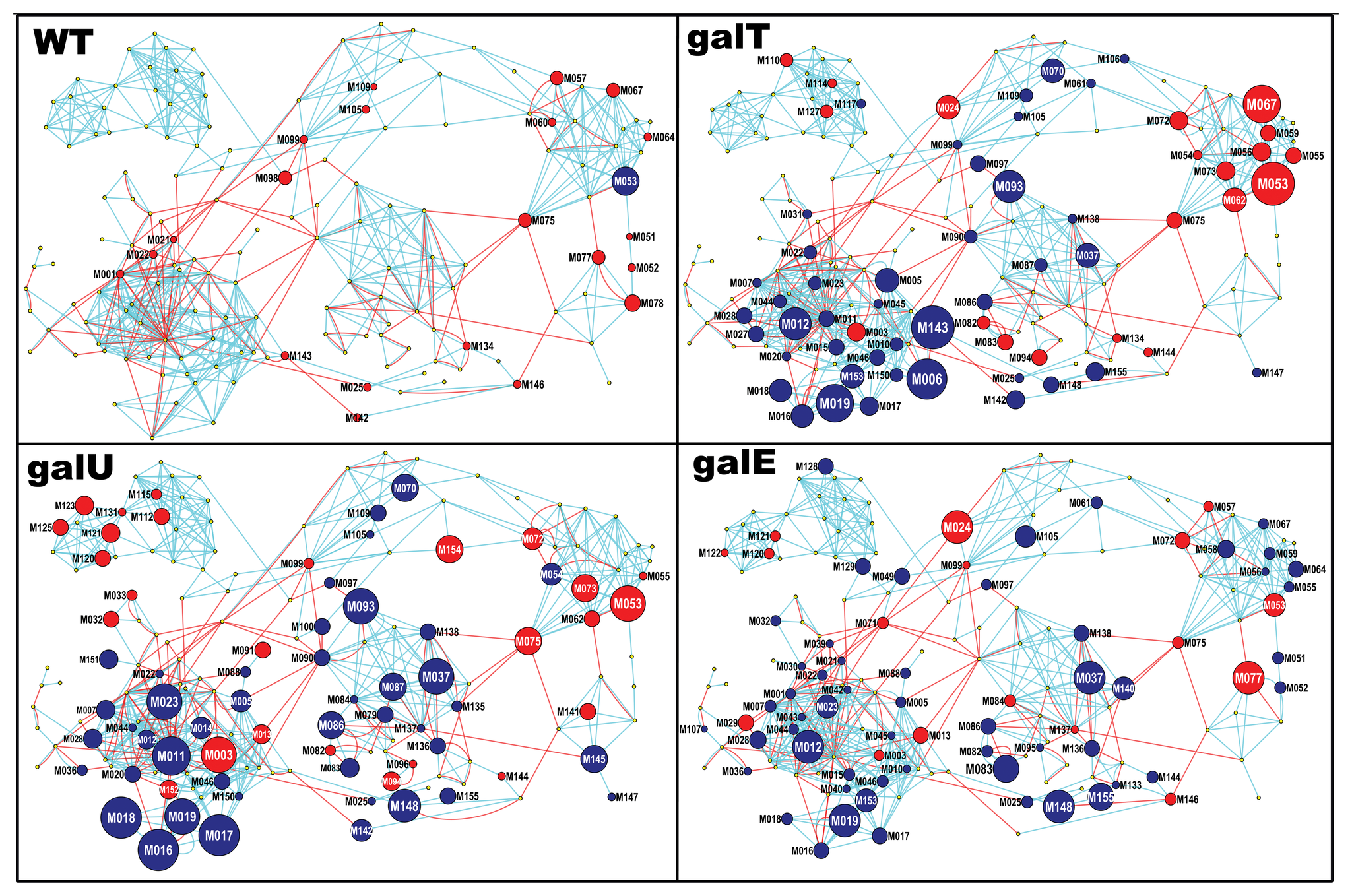
估计阅读时长: 5 分钟在工作之中可能会遇到需要进行两个网络图对象之间的相似度计算的情形:例如在质谱数据分析的化学信息学计算工作之中,我们在解析SMILES字符串得到分子图之后,可以基于图相似度比较计算方法来比较计算两个代谢物分子图之间的结构上的相似度。 Attachments pone.0078360.g003 • 2 MB • 908 click 2022年8月6日https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0078360

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?