

估计阅读时长: 18 分钟在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。除了针对降维后的数据进行散点图可视化,我们还可以直接针对向量化嵌入后的原始嵌入矩阵进行聚类,完成聚类结果的可视化。在这里我们主要是基于嵌入的原始结果进行二叉树聚类可视化。 Order by Date Name Attachments community_metabolic_tree • 220 kB • 363 click 2026年2月15日community-local • […]

估计阅读时长: 24 分钟假若现在有两条Fasta序列放在你面前,现在需要你进行这两条Fasta序列的相似度计算分析。如果对于我而言,大学刚毕业刚入门生物信息学的时候,可能只能够想到通过blast比对的方式进行序列相似性计算分析。基于blast比对方式可以找到生物学意义上的序列相似性结果,但是计算的效率会比较低。假设现在让你使用这些序列进行机器学习建模分析,或者基于传统数学意义上的基于相似度的无监督聚类分析的时候,面对这些长度上长短不一的生物序列数据,可能会比较蒙圈,因为传统的数学分析方法都要求我们分析的目标至少应该是等长的向量数据。 Order by Date Name Attachments Fasta-A • 544 kB • 881 click 2023年6月29日visualize • 45 […]
估计阅读时长: 5 分钟在工作之中可能会遇到需要进行两个网络图对象之间的相似度计算的情形:例如在质谱数据分析的化学信息学计算工作之中,我们在解析SMILES字符串得到分子图之后,可以基于图相似度比较计算方法来比较计算两个代谢物分子图之间的结构上的相似度。 Attachments pone.0078360.g003 • 2 MB • 1002 click 2022年8月6日https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0078360
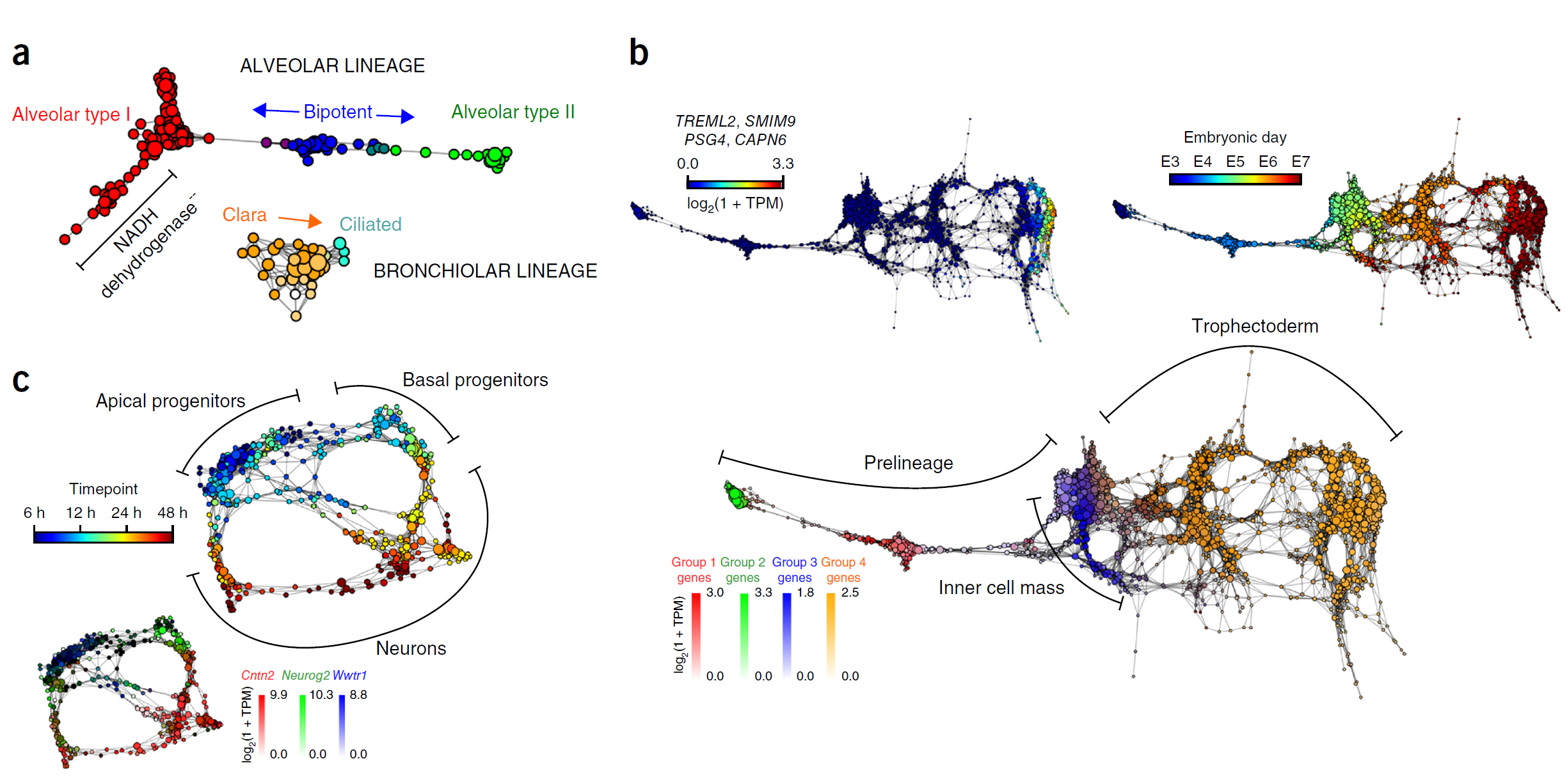
估计阅读时长: 14 分钟单细胞分析方法学习文献打卡记录: 【单细胞组学】PhenoGraph单细胞分型 【单细胞分析方法】VeTra:基于RNA速度的轨迹推断工具 【单细胞分析方法】单细胞图嵌入 Order by Date Name Attachments Cellular populations during motor neuron differentiation • […]
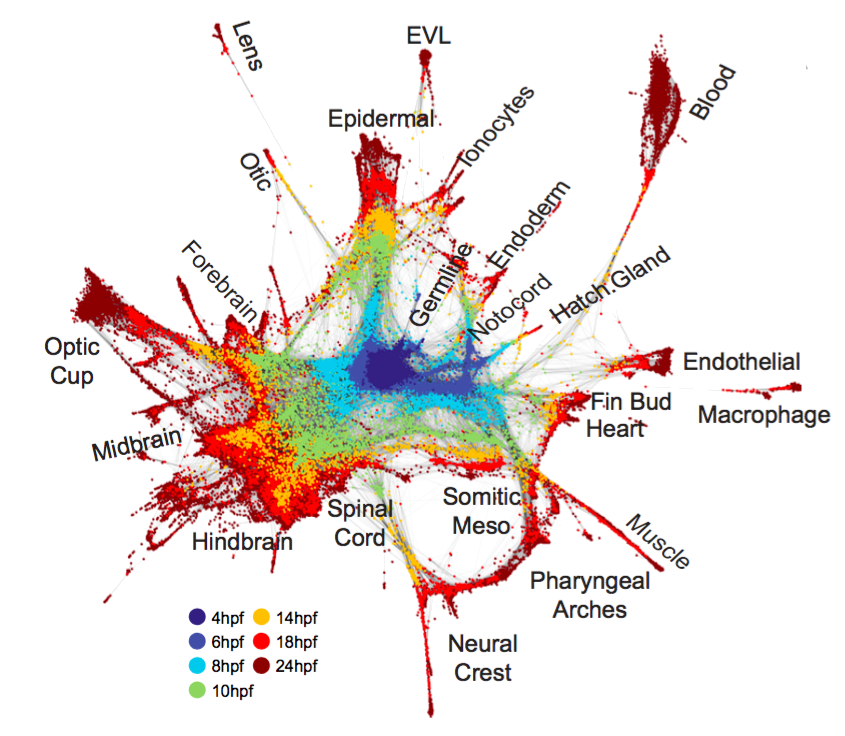
估计阅读时长: 7 分钟Assembles a manifold that is defined through a series of overlapping, locally-defined PCA subspaces. Non-mutual k-nearest-neighborhoods […]

估计阅读时长: 5 分钟https://github.com/xieguigang/graphQL 构建一个图数据库,可以用来帮我们解决复杂的知识关联计算问题。例如我们想要程序向我们回答dihydrogen oxide与water是否是同一个东西。如果光从字符串比较角度上面来看待这个问题的话,很显然,二者的字符串比较结果肯定是False。面对上面的这个问题,图数据库则可以很简单的向我们回答道上面的两个字符串都是指代的同一个东西。 Order by Date Name Attachments tumblr_inline_mqvdlydGCp1qz4rgp • 124 kB • 911 click 2022年3月5日Capture […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?