
估计阅读时长: 5 分钟目前我们根据质谱数据进行代谢物ROI注释分析,很大一部分的工作是建立在已经可以被纯化的化合物的纯标准品所建立的标准品库数据的比对操作之上的。但是依赖于质谱参考谱图数据库所完成的代谢物注释分析,也仅能够得到很小的一部分结果,因为能够纯化或者合成的化合物在整个自然界中目前只占比较小的一部分。并且购买标准品也会需要耗费大量的实验室资金预算。 Order by Date Name Attachments The-Periodic-Table • 2 MB • 1062 click 2022年3月20日Leucine[M+H]+ • 33 […]
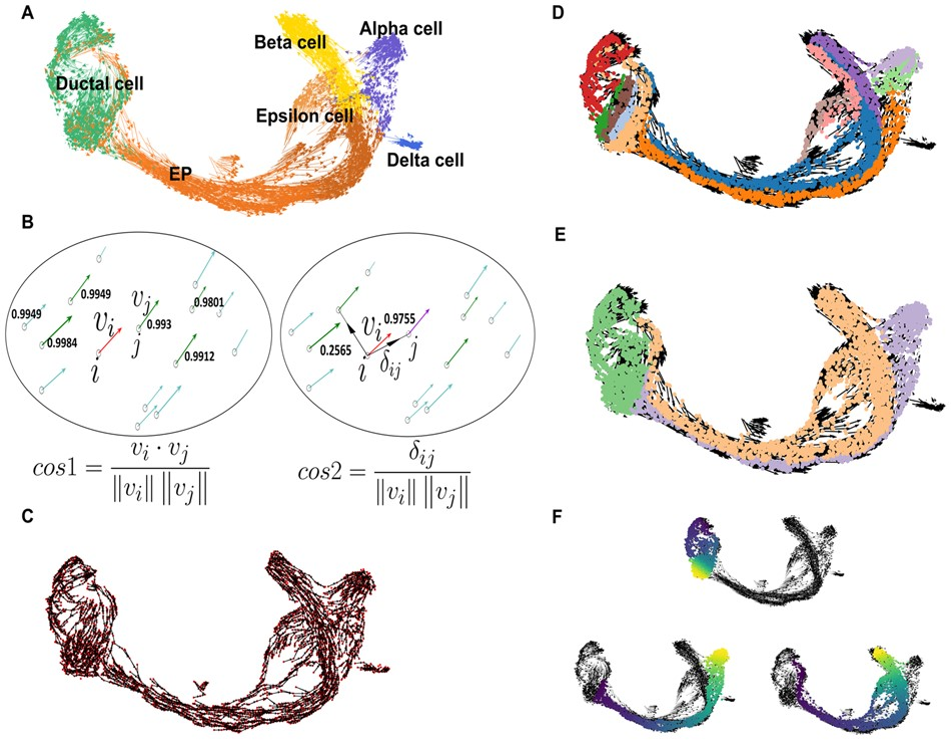
估计阅读时长: 5 分钟单细胞轨迹可以揭示基因调控如何控制细胞命运:大多数细胞状态转变,无论是在发育,重编程或者是疾病异常状态,都以基因表达变化的级联为特征。 Order by Date Name Attachments vec • 722 kB • 1031 click 2022年3月17日Slide10 • 14 […]

估计阅读时长: 5 分钟https://github.com/xieguigang/graphQL 构建一个图数据库,可以用来帮我们解决复杂的知识关联计算问题。例如我们想要程序向我们回答dihydrogen oxide与water是否是同一个东西。如果光从字符串比较角度上面来看待这个问题的话,很显然,二者的字符串比较结果肯定是False。面对上面的这个问题,图数据库则可以很简单的向我们回答道上面的两个字符串都是指代的同一个东西。 Order by Date Name Attachments tumblr_inline_mqvdlydGCp1qz4rgp • 124 kB • 1003 click 2022年3月5日Capture […]

This content speaks to hearts
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]