
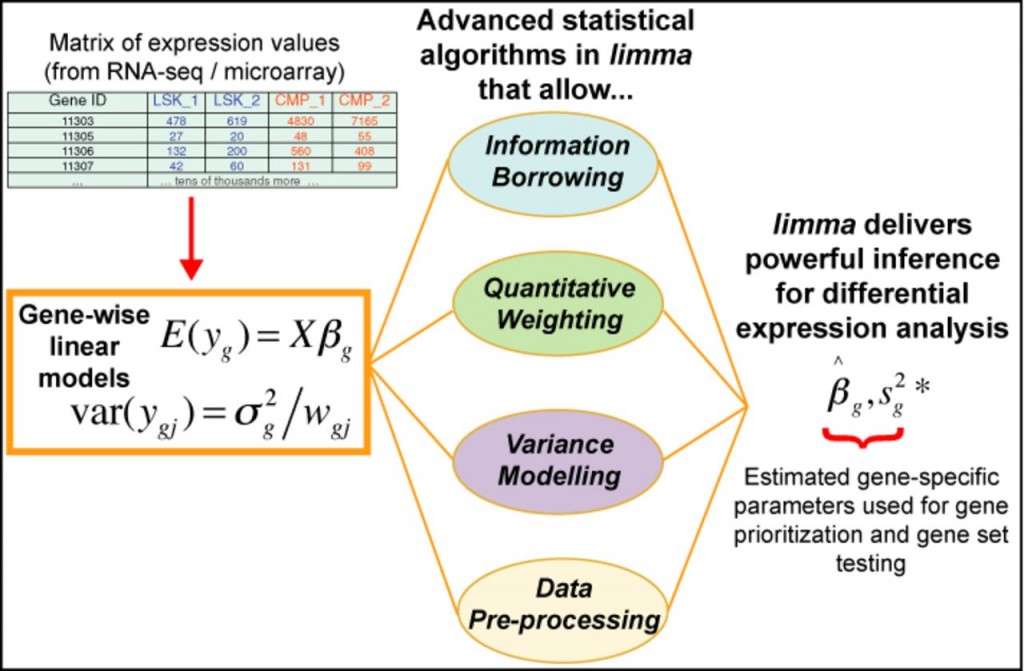
估计阅读时长: 22 分钟limma(Linear Models for Microarray Data)是一个基于R语言的Bioconductor包,最初用于微阵列数据的差异表达分析,现已扩展支持RNA-seq数据。其核心思想是利用线性模型(Linear Models)对基因表达数据进行建模,并结合经验贝叶斯(Empirical Bayes)方法在小样本情况下增强统计推断的稳健性。 Order by Date Name Attachments limma • 119 kB […]

估计阅读时长: 2 分钟宏基因组学(Metagenomics)通过直接测序环境样本中的全部DNA,从而避免了传统培养方法的局限,使我们能够研究不可培养微生物的多样性。然而,当样本来自宿主相关环境(如人类或小鼠的肠道、土壤等)时,测序数据中不可避免地包含大量宿主自身的DNA序列。这些宿主序列会占据测序读数,增加分析成本,并可能干扰对微生物群落组成的准确推断。因此,在宏基因组数据分析中,去除宿主序列(Host Sequence Removal)是至关重要的预处理步骤。去除宿主序列的算法多种多样,其中基于k-mer的方法因其高效和可扩展性而备受关注。 Attachments Metagenomics • 211 kB • 534 click 2025年11月29日

估计阅读时长: 11 分钟给定一组n个字符串数组,找到包含给定集合中每个字符串的最小字符串作为子字符串。我们可以假设这个字符串数组中没有字符串是另一个字符串的子字符串。那么基于上面的描述,我们就可以得到下面所示的问题求解目标: let arr[] = ["catg", "ctaagt", "gcta", "ttca", "atgcatc"] // output: gctaagttcatgcatc 上面的问题描述实际上是一个最短超字符串问题(shortest common superstring) Order […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?