
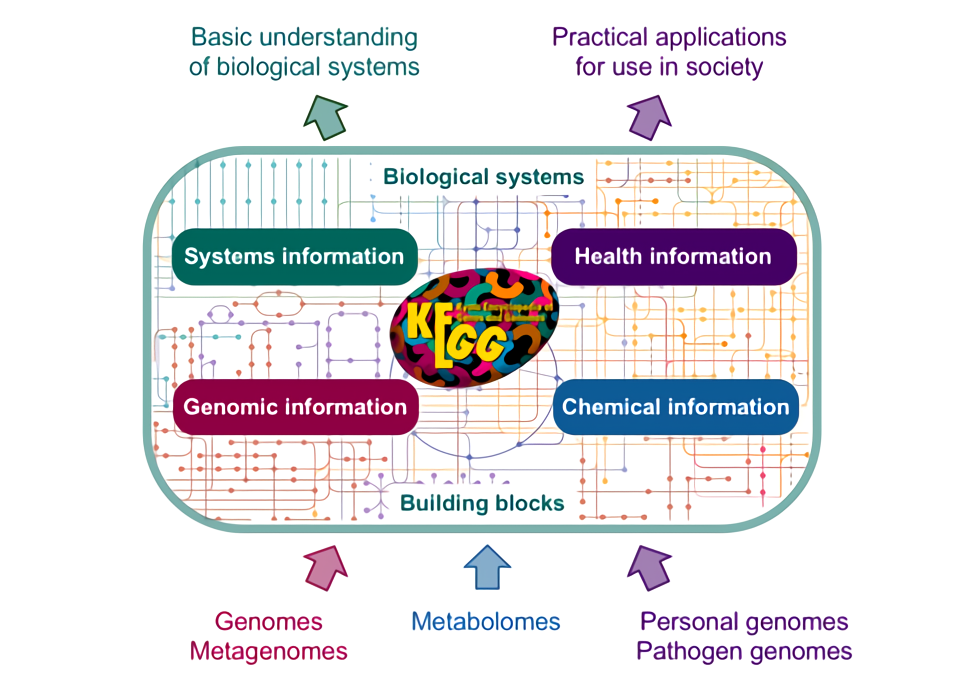
估计阅读时长: 16 分钟KEGG 里面目前并没有“现成的每个 KO 一条代表性序列 FASTA”这种官方序列数据库,假若我们需要基于KEGG数据库中的KO信息的注释,那我们一般会需要自己从 KEGG GENES 里面把每个 KO 对应的基因/蛋白序列抓出来,再按 KO 编号组织成 fasta 集合构建出对应的数据库。基于所建立好的KEGG基因序列数据库,我们就可以实现下面的一些基因注释工作: 在全基因组规模代谢网络重建工作中,进行我们的目标基因组中的代谢网络中的酶节点的直系同源推断,从而将我们的目标基因组中的基因映射到具体的KEGG代谢网络上的节点位置,从而重建出代谢网络模型(使用带有KO编号的蛋白序列做比对注释) 假若我们在进行宏基因组的基因丰度的计算,则可以基于所建立的KEGG基因序列数据库作为参考库,进行宏基因组测序数据中的KO基因丰度的计算(使用带有KO编号的基因序列做比对注释) […]
估计阅读时长: 34 分钟在前面写了一篇文章来介绍我们可以如何通过KEGG的BHR评分来注释直系同源。在KEGG数据库的同源注释算法中,BHR的核心思想是“双向最佳命中”。它比简单的单向BLAST搜索(例如,只看你的基因A在数据库里的最佳匹配是基因B)更为严格和可靠。在基因注释中,这种方法可以有效减少因基因家族扩张、结构域保守等原因导致的假阳性注释,从而更准确地识别直系同源基因,而直系同源基因通常具有相同的功能。在今天重新翻看了下KAAS的帮助文档之后,发现KAAS系统中更新了下面的Assignment score计算公式: We define a score for each ortholog group in order to assign the best […]

估计阅读时长: 14 分钟宏基因组测序所处理的对象是直接对环境样本中的所有DNA进行测序。达到无需培养即可揭示微生物群落的组成和功能潜力的目的。在数据处理中,一个核心任务是从海量短读序列中估算物种丰度(即每个物种在样本中的相对含量)和基因丰度(即每个基因或功能单元的相对含量)。传统的基于序列比对的方法计算成本高昂,而基于k-mer的方法通过利用固定长度的子序列(k-mer)信息,能够在不依赖完整比对的情况下快速估算丰度。 k-mer是指长度为k的连续子序列,例如在k=2的时候,DNA序列“ATCG”包含的2-mers有“AT”、“TC”、“CG”。通过统计读序列中k-mer的出现频率,并将其与参考数据库中的k-mer频率进行比较,我们可以推断出样本中各物种或基因的丰度。这种方法具有计算速度快、内存效率高的优势,并且无需对每个读进行精确比对,因此在处理大规模宏基因组数据时非常实用。 Order by Date Name Attachments workflow1 • 272 kB • 548 click 2025年12月8日workflow2 • […]
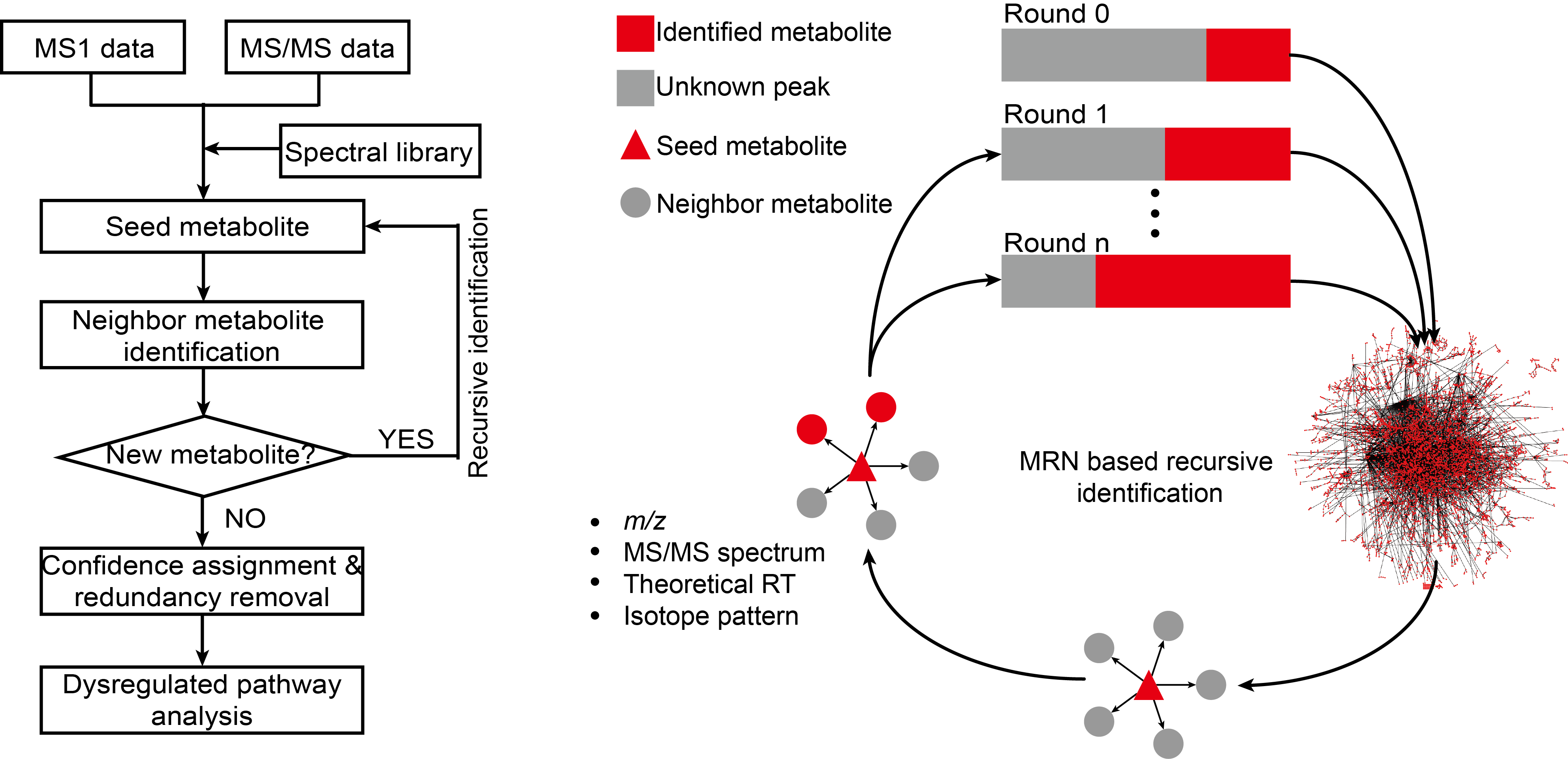
估计阅读时长: 6 分钟访问在线服务: http://metdna.zhulab.cn/ Metabolite identification is the long-standing challenge for liquid chromatography-mass spectrometry (LC-MS)-based untargeted metabolomics. Here, […]
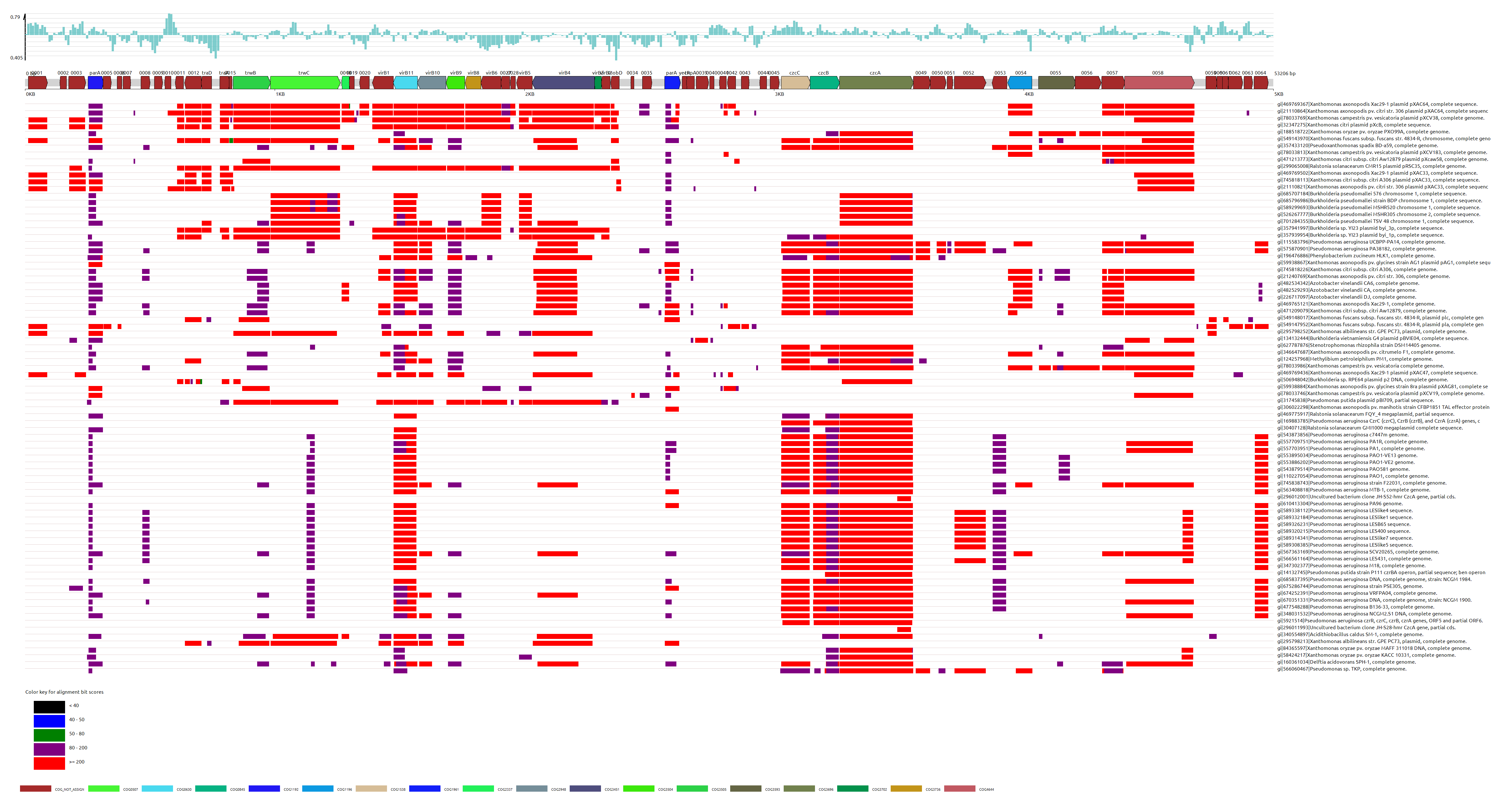
估计阅读时长: 14 分钟在基因组学研究中,将新测序的基因或者针对目标基因组进行基于KEGG代谢通路体系的虚拟细胞建模,都会需要将目标基因组与已知功能基因进行比对注释。KEGG(Kyoto Encyclopedia of Genes and Genomes)数据库通过其KEGG Orthology (KO)系统,为基因功能注释提供了一个强大的平台。KO系统将功能上保守的直系同源基因归为一类,每个KO条目(K编号)代表一个直系同源基因群,这些基因在不同物种中通常执行相似的生物学功能。因此,将新基因的序列与KEGG数据库中的已知基因进行比对,可以推断其可能的KO编号,从而将其功能映射到KEGG通路图或功能层级中。 Order by Date Name Attachments kegg_overview • 313 […]
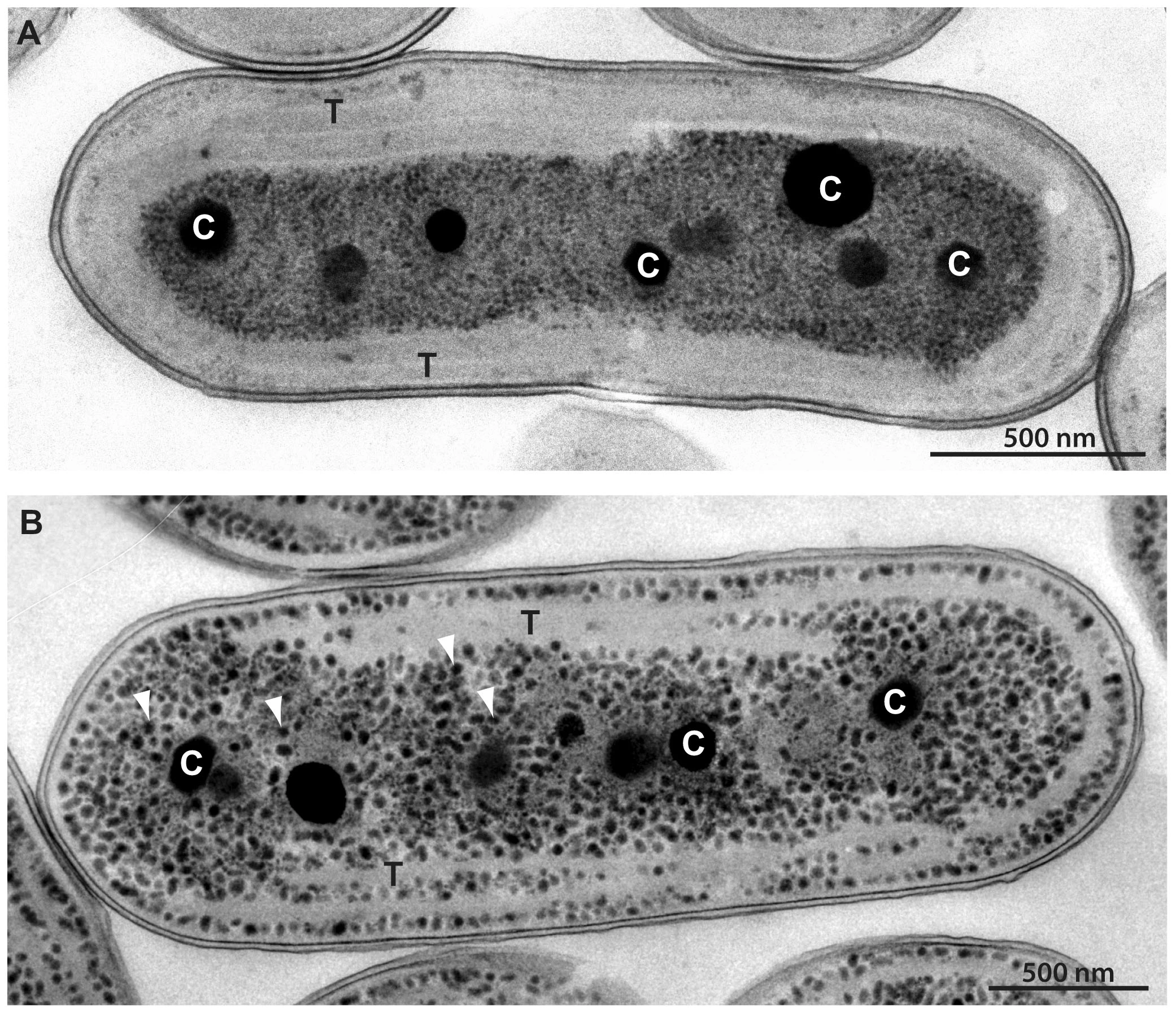
估计阅读时长: 10 分钟https://gcmodeller.org/ 流平衡分析(flux balance analysis)是一种可以用来构建和模拟分析基因组级别的代谢网络的数学方法。流平衡分析是系统生物学(system biology)的一个重要的分析手段。不同于以湿实验的代谢通量分析(metabolic flux analysis, MFA),FBA是用数学方法对代谢网络里的代谢流进行拟合分析。 Order by Date Name Attachments Electron micrographs of […]

估计阅读时长: 2 分钟在BILIBILI上观看视频:《【GCModeller教程】基因组功能富集计算原理》 Order by Date Name Attachments 20190818_GSEA_release.mp4_20190921_225144.467 • 226 kB • 1116 click 2021年5月30日Fisher Exact Test […]

估计阅读时长: 2 分钟在BILIBILI上观看视频:《【GCModeller教程】KEGG代谢途径注释原理 (重置版)》 Order by Date Name Attachments kegg_annotation • 468 kB • 1202 click 2021年5月30日release.mp4_20190921_225235.396 • […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?