

估计阅读时长: 9 分钟https://github.com/rsharp-lang/Rnb 之前使用Python脚本进行编写代码的时候,十分的羡慕Python脚本可以基于ipynb记事本进行文档化的编码。在之前R#脚本是缺少相关的代码库模块将可执行的R#脚本渲染成可视化文档。但是经过几天的开发工作时候,现在R#脚本编程已经具备有了文档化编程的基本框架了。 Order by Date Name Attachments 01510007-school-notebook • 32 kB • 838 click 2021年10月30日renderHtml_cli • […]
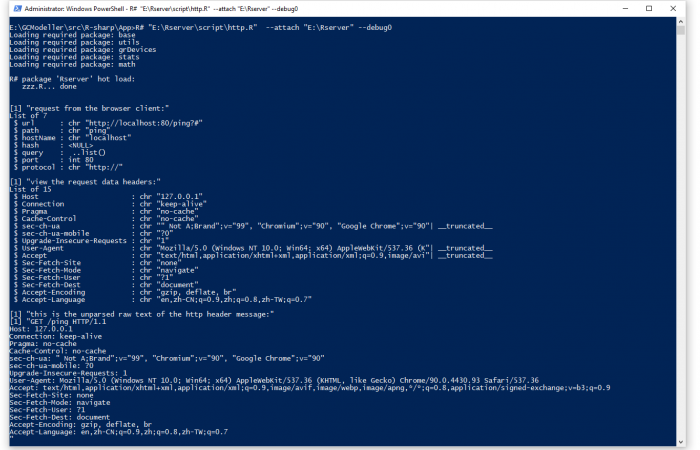
估计阅读时长: 5 分钟https://github.com/rsharp-lang/Rserver 在R语言之中,存在有一个FastRWeb的框架可以将R语言编写的脚本以http服务的方式运行于后台,供其他的语言进行调用。在R#语言之中,我也模仿着R语言之中的FastRWeb框架,创建了一个用于R#语言的web服务的程序包框架。 Order by Date Name Attachments httpr_commandline • 28 kB • 841 click 2021年6月16日http_PUT_test • […]
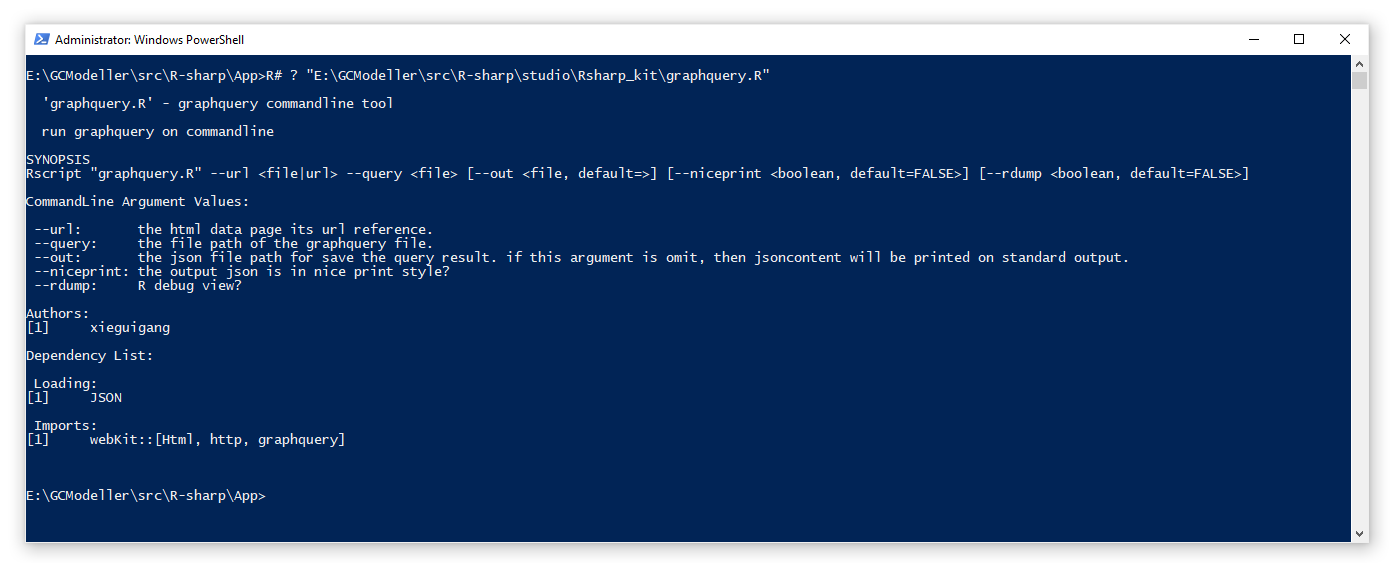
估计阅读时长: 9 分钟前段时间由于工作的需要,会需要从一些网站上抓取数据用来做数据分析。在原来我进行网页爬虫开发的时候,一般会需要专门针对网页格式,使用大量的正则表达式进行内容的解析。由于你也知道,VisualBasic语言所开发的程序为一个编译好的Assembly文件,所以假若所需要爬取的网页格式变化了,我们就需要对代码做修改和重新编译。这个时候就会非常的不方便。 Order by Date Name Attachments ea5d2885-bba5-410f-b02b-0589613412ed • 12 kB • 937 click 2021年5月29日graphquery_Rscript • 36 […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?