

估计阅读时长: 18 分钟在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。除了针对降维后的数据进行散点图可视化,我们还可以直接针对向量化嵌入后的原始嵌入矩阵进行聚类,完成聚类结果的可视化。在这里我们主要是基于嵌入的原始结果进行二叉树聚类可视化。 Order by Date Name Attachments community_metabolic_tree • 220 kB • 413 click 2026年2月15日community-local • […]
估计阅读时长: < 1 分钟UPGMA(Unweighted Pair Group Method with Arithmetic Mean,非加权配对组平均法)是一种经典的基于距离矩阵构建系统发育树的聚类算法。其核心思想是假设进化速率恒定(分子钟假说),通过迭代合并距离最近的两个类群(或序列)来构建树。UPGMA算法具有原理简单,计算速度快,易于理解和实现。对于符合分子钟假说(即所有分支进化速率相同)的数据,能给出正确的拓扑结构这些优点。但是其“进化速率恒定”的假设在现实中常常不成立。如果数据存在明显的速率差异(即存在长枝),UPGMA可能会构建出错误的树(拓扑结构错误)。因此,它更适用于进化速率相对均匀的近缘物种或基因的比较。
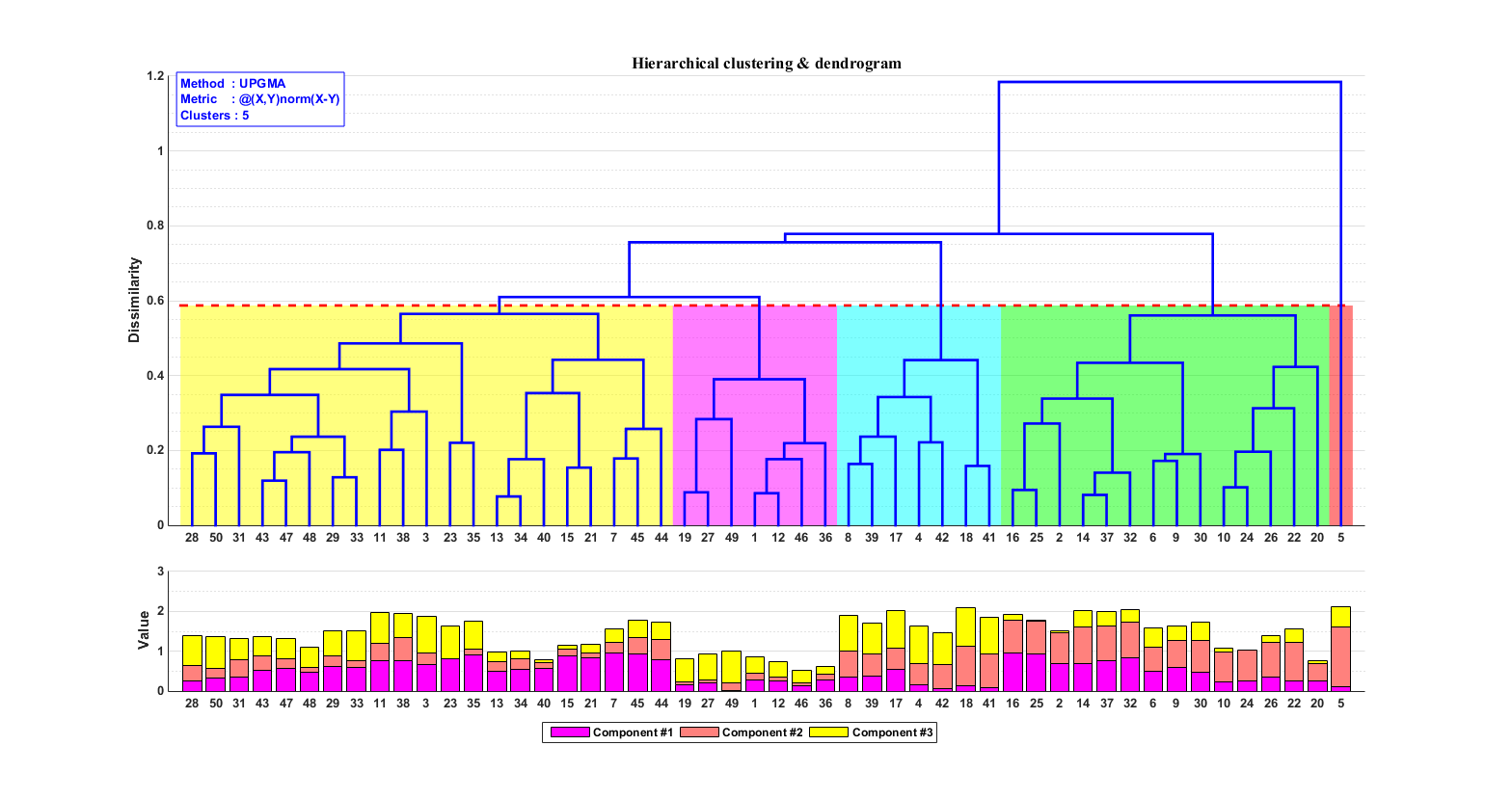
估计阅读时长: 14 分钟https://github.com/xieguigang/sciBASIC 层次聚类通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。基于层次聚类分析,我们可以初步可视化我们的一些原始数据: 例如对样本的层次聚类分类,可以让我们了解到样本在分组之间以及分组内的异质性。 对生物序列进行基于相似度的层次聚类分析,我们可以了解到序列之间的相似性程度或者进化关系 Order by Date Name Attachments metabolome • 14 kB • 1052 click […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?