
估计阅读时长: 14 分钟酶的EC number(Enzyme Commission number)是国际生物化学与分子生物学学会(IUBMB)酶学委员会制定的酶分类与命名体系的核心标识符,自1961年首次发布以来,已成为酶学研究、数据库管理和生物技术应用的全球标准。这套由四位数字所构成的的层级编码系统不仅解决了早期酶命名混乱的问题,还通过系统化分类揭示了酶催化功能的内在逻辑,为酶学研究提供了统一的框架。 Order by Date Name Attachments Enzyme_Commission_Numbers-visual_selection • 70 kB • 201 click […]
估计阅读时长: < 1 分钟UPGMA(Unweighted Pair Group Method with Arithmetic Mean,非加权配对组平均法)是一种经典的基于距离矩阵构建系统发育树的聚类算法。其核心思想是假设进化速率恒定(分子钟假说),通过迭代合并距离最近的两个类群(或序列)来构建树。UPGMA算法具有原理简单,计算速度快,易于理解和实现。对于符合分子钟假说(即所有分支进化速率相同)的数据,能给出正确的拓扑结构这些优点。但是其“进化速率恒定”的假设在现实中常常不成立。如果数据存在明显的速率差异(即存在长枝),UPGMA可能会构建出错误的树(拓扑结构错误)。因此,它更适用于进化速率相对均匀的近缘物种或基因的比较。
估计阅读时长: 8 分钟原核生物细胞内的中心法则是指遗传信息从DNA经RNA到蛋白质的传递过程,具有高效和经济的特点。DNA复制、转录和翻译均在细胞质中进行,且转录与翻译高度偶联——新生mRNA尚未完全合成,核糖体便已结合并开始翻译,极大提升了蛋白质合成速率。原核生物mRNA常为多顺反子结构,一条mRNA可编码多个功能相关的蛋白质,且无内含子、无需剪接,可直接作为翻译模板。此外,原核mRNA半衰期极短,便于快速响应环境变化。基因表达主要通过操纵子结构在转录水平进行精细调控,如乳糖操纵子和色氨酸操纵子,使原核生物能够灵活适应多变环境。这些机制共同构成了原核生物中心法则的核心,体现了其高度优化的遗传信息传递系统。 Attachments the-central-dogma-of-molecular-biology1-l • 70 kB • 311 click 2025年12月21日
估计阅读时长: 23 分钟Sequence Logo 是一种可视化 DNA 或蛋白质序列保守性的图形表示方法。每个位置(列)上的字母堆叠高度代表该位点的信息含量(以 bits 为单位),而每个字母的高度则与其在该位点出现的频率成正比。高信息量的位置字母堆得高,低信息量的位置则矮甚至接近零。Sequence Logo的绘制遵循信息熵原理,我们可以很直观的通过某一个位置的总高低来了解该处位置的信息含量有多少,高信息量的位置,字母堆的高,一般会出现某一个字符特别高,表明该处非常保守。 位置权重矩阵(Position Weight Matrix, PWM)是描述基因组调控因子结合位点序列模式的核心模型。它通过统计在结合位点序列中每个位置上各核苷酸(或氨基酸)出现的频率,来量化该位置对不同碱基的偏好程度。PWM通常以矩阵形式表示,行对应核苷酸(A、C、G、T/U),列对应序列中的位置,矩阵元素即为该位置该核苷酸相对于背景的权重得分。这一模型简洁且易于计算,因此在转录因子结合位点(TFBS)等调控元件的识别和表征中被广泛采用。 Order by Date Name […]

估计阅读时长: 5 分钟将复杂的生物学过程拆解为单元化学反应,是进行定量模拟的基石。转录是基因表达调控的关键环节,决定了细胞在特定时间、特定环境下合成哪些蛋白质,对生命活动至关重要。最近的工作中需要将原本非常粗糙的虚拟细胞转录事件模型拆解为更加细分化的多步骤生物化学过程,以适应针对细胞群落生长的建模计算。下面为我将原核生物的转录过程拆解为一系列可以用化学式表示的单元步骤的结果。 在介绍这些分步骤之前,我们会需要首先来定义一下模型中会用到的各种“化学物质”(分子和复合物): RNAP: RNA聚合酶全酶(包含核心酶和σ因子)。 DNA: 基因组DNA双链。 DNA_P: 包含启动子区域的DNA。 DNA_T: 包含终止子区域的DNA。 NTP: 核糖核苷三磷酸(ATP, UTP, GTP, CTP的统称)。 PPi: […]

估计阅读时长: 30 分钟零分布(null distribution)是指在假设零假设(null hypothesis)成立的情况下,某个统计量随机取值的概率分布。在统计假设检验中,我们通常提出一个零假设(例如“两组数据没有显著差异”或“观察到的模式仅由随机因素造成”),然后根据观测数据计算一个检验统计量。零分布描述了这个统计量在零假设为真时的分布情况。通过将实际观测到的统计量与零分布进行比较,我们可以计算出P-value:即在零假设下,出现等于或更极端观测结果的概率。如果P-value很小(例如低于预设的显著性水平α),我们就认为零假设不太可能成立,从而拒绝零假设,认为观测结果是统计显著的。 Order by Date Name Attachments image-2 • 66 kB • 293 click 2025年12月16日NULL-pvalue […]
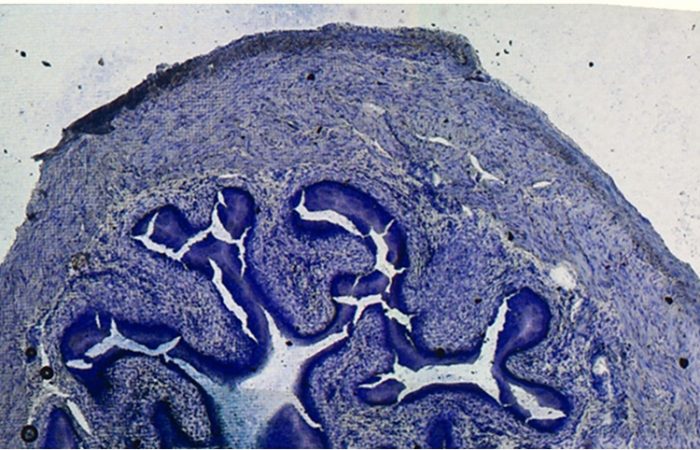
估计阅读时长: < 1 分钟HE染色(苏木精-伊红染色,Hematoxylin and Eosin Staining)是一种组织学和病理学中广泛应用的技术,用于染色组织切片以便于显微观察。该技术利用两种染料——苏木精和伊红,分别染色细胞核和细胞质,从而呈现出清晰的细胞结构。用于观察组织和细胞的形态结构。HE染色技术因其简单、高效的特点,成为组织学、胚胎学和病理学研究中不可或缺的基础方法。HE染色通过苏木精和伊红的染色作用,帮助观察和区分细胞核与细胞质及细胞外基质的形态结构。解读HE染色结果需要结合实验背景和研究目的,观察染色的均匀性、对比度以及细胞和组织的形态变化,从而提供重要的实验依据。 HE染色技术的历史可以追溯到19世纪末: 1868年:德国病理学家Karl Weigert开发了苏木精染色法,用于染色细胞核。 1877年:Albrecht von Leube开发了伊红染色法,用于染色细胞质。 1876年:化学家Wissowzky首次联合使用苏木精和伊红,但未被认为是发明者。 1886年:Paul Ehrlich发表了相关研究,推动了HE染色技术的标准化和广泛应用。
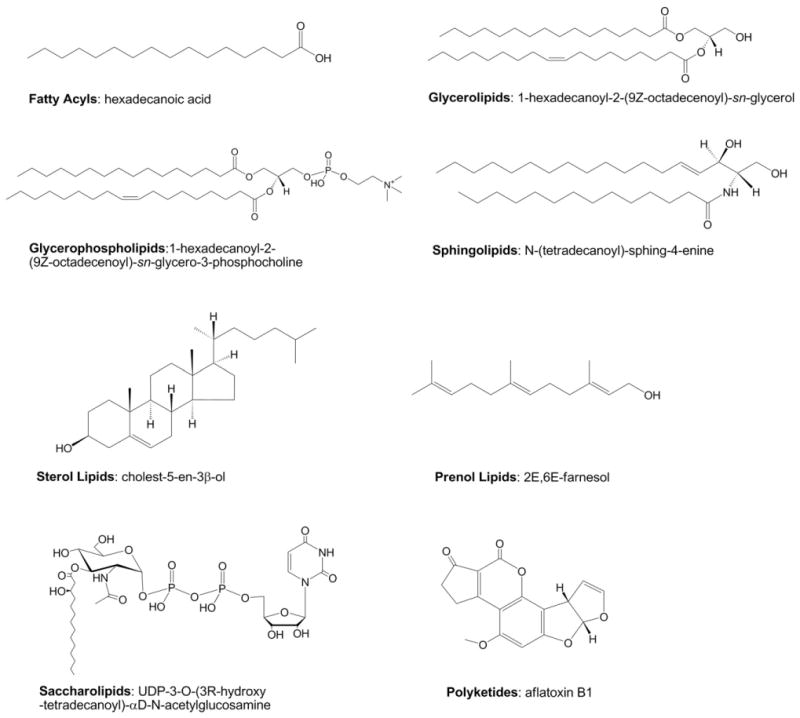
估计阅读时长: 2 分钟脂质组学作为系统生物学和代谢组学的重要分支,近年来取得了长足的发展,已成为生命科学研究中不可或缺的重要工具。 脂质组学的定义与研究内容 脂质组学是系统研究脂质组的一门独立学科,作为大规模定性和定量研究脂类化合物并了解它们在不同生理、病理条件下的功能和变化的方法学,能准确全面地提供生物样品中的脂质信息。它被定义为对生物体、组织或细胞中的脂质以及与其相互作用的分子进行全面系统的分析、鉴定,进而揭示脂质代谢与细胞、器官乃至机体生理病理过程的关系。 脂质是一类具有疏水性并且在大多数情况下可以溶于有机溶剂的物质,当然,还有部分脂质因为带有极性基团,往往是亲水性的,例如磷脂等。脂质组学是对生物体内的脂质进行系统分析的一门新兴学科,是代谢组学的重要分支。基于液质联用技术(LC-MS),无偏向性、尽可能多地检测细胞、组织、器官或体液等生物样本中的脂质。
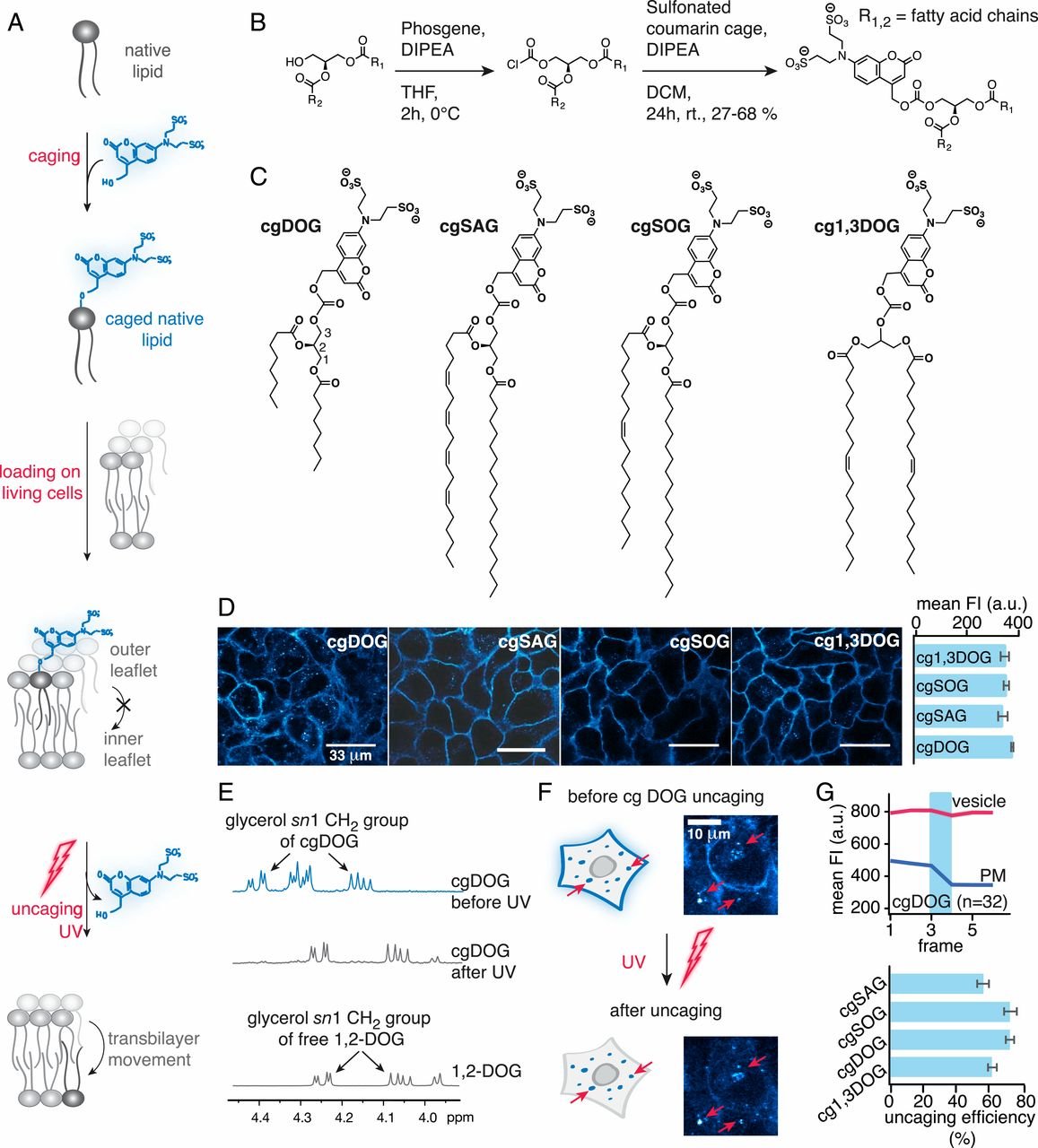
估计阅读时长: 3 分钟引言 二酰甘油(Diacylglycerol,DAG)是细胞内一类重要的脂质分子,作为生物膜的重要组成部分,同时也参与多种生物学功能和代谢途径。Diacylglycerol (DAG, 16:0_18:1) 是甘油二酯的一种异构体,其结构为sn-1位连接棕榈酸(16:0)、sn-2位连接油酸(18:1)。它在脂质代谢中具有多重角色,涉及合成、分解、信号传导及能量调节等过程。

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?