
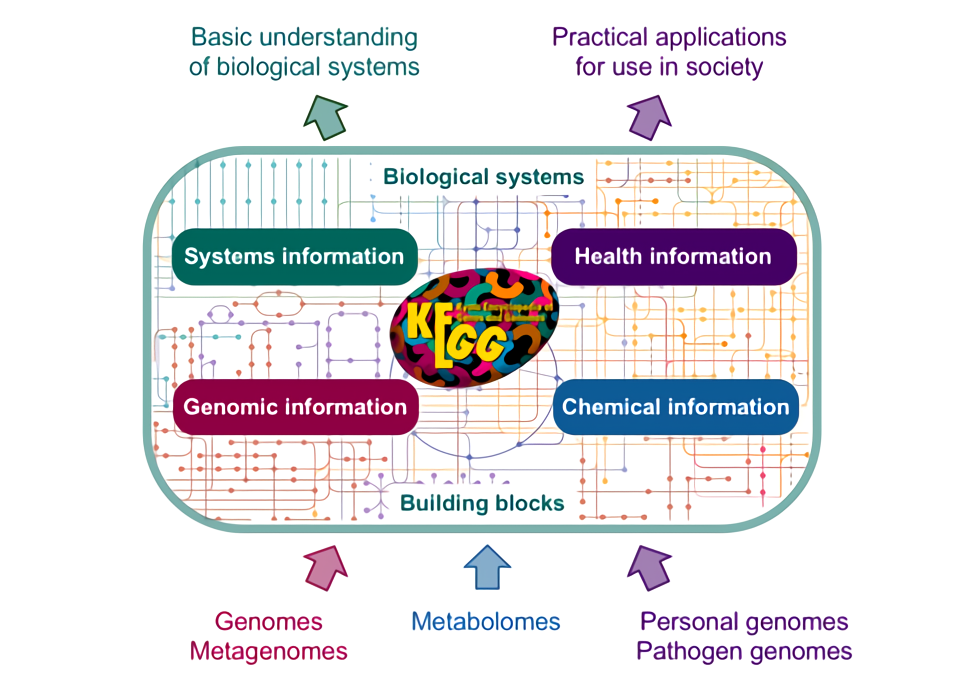
估计阅读时长: 16 分钟KEGG 里面目前并没有“现成的每个 KO 一条代表性序列 FASTA”这种官方序列数据库,假若我们需要基于KEGG数据库中的KO信息的注释,那我们一般会需要自己从 KEGG GENES 里面把每个 KO 对应的基因/蛋白序列抓出来,再按 KO 编号组织成 fasta 集合构建出对应的数据库。基于所建立好的KEGG基因序列数据库,我们就可以实现下面的一些基因注释工作: 在全基因组规模代谢网络重建工作中,进行我们的目标基因组中的代谢网络中的酶节点的直系同源推断,从而将我们的目标基因组中的基因映射到具体的KEGG代谢网络上的节点位置,从而重建出代谢网络模型(使用带有KO编号的蛋白序列做比对注释) 假若我们在进行宏基因组的基因丰度的计算,则可以基于所建立的KEGG基因序列数据库作为参考库,进行宏基因组测序数据中的KO基因丰度的计算(使用带有KO编号的基因序列做比对注释) […]
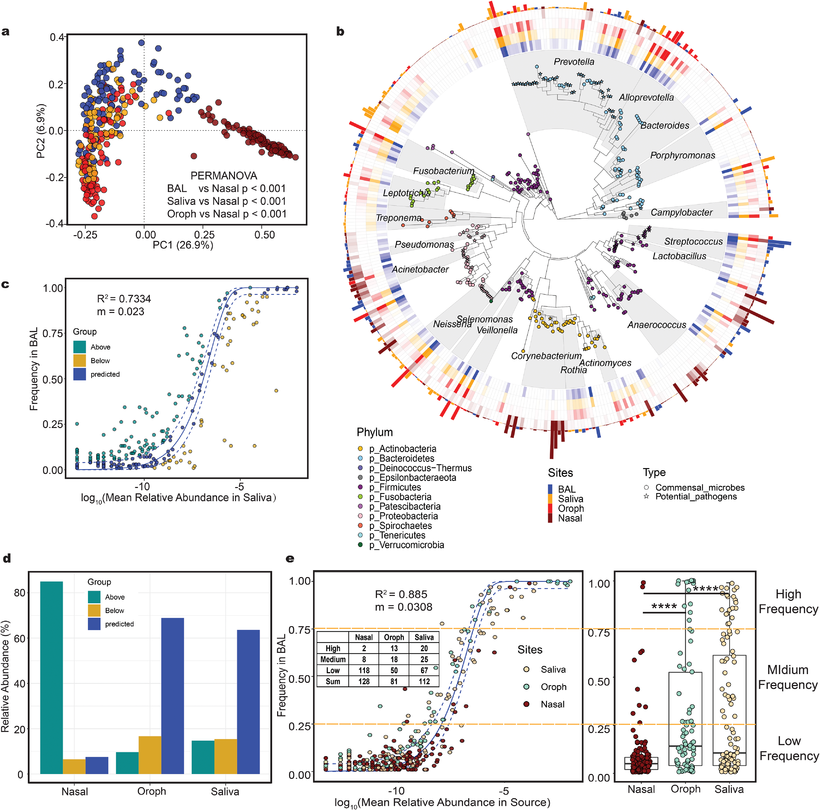
估计阅读时长: < 1 分钟环境中的微生物往往以复杂群落的形式存在,不同物种之间通过代谢相互作用形成协同或竞争关系,共同完成生物地球化学循环、维持生态系统功能。近年来,随着高通量基因组测序技术的发展,研究者可以从环境样本中获取海量微生物基因组数据,为构建基因组尺度代谢模型(Genome-scale metabolic models, GEMs)提供了基础。GEMs将微生物的全基因组注释与生化反应网络相结合,可以用于模拟微生物在特定环境条件下的代谢能力,预测其生长和代谢产物。在单菌株层面,GEMs已被广泛用于解析微生物对环境变化的代谢适应机制、指导代谢工程设计以及预测药物靶点等。在群落层面,通过将多个GEMs耦合,可以研究微生物之间的相互作用,例如通过代谢物交换实现的协同或竞争关系。 Attachments The-taxonomic-composition-of-various-type-samples-and-the-results-of-neutral-model • 500 kB • 508 click 2026年1月4日
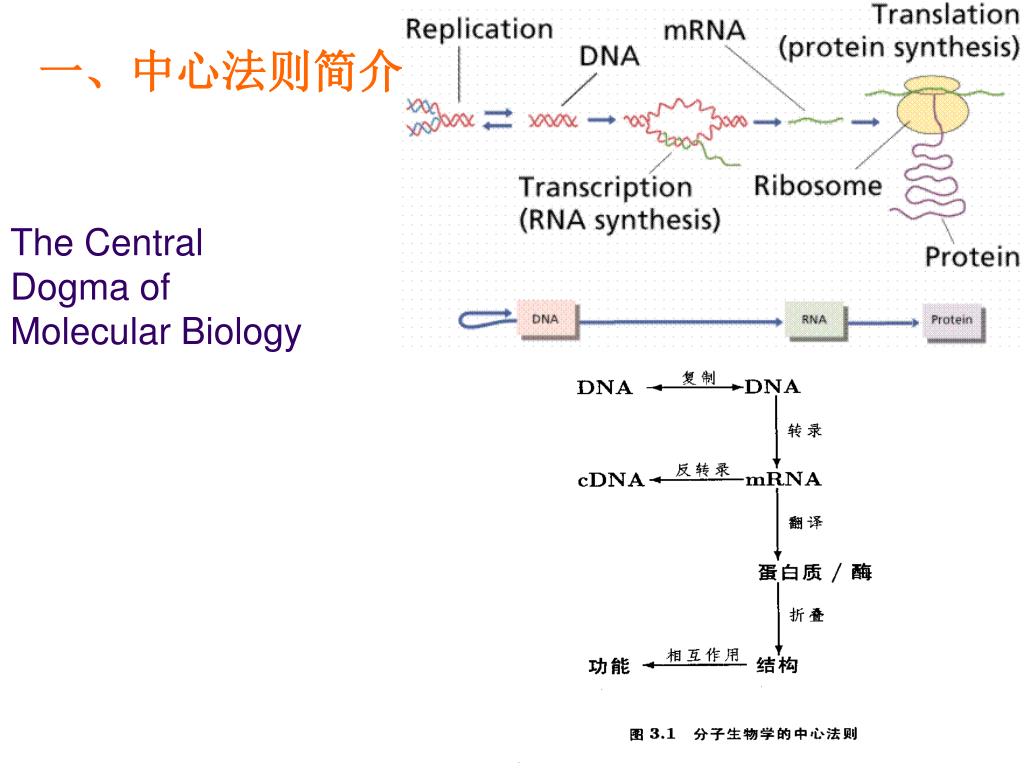
估计阅读时长: 8 分钟原核生物细胞内的中心法则是指遗传信息从DNA经RNA到蛋白质的传递过程,具有高效和经济的特点。DNA复制、转录和翻译均在细胞质中进行,且转录与翻译高度偶联——新生mRNA尚未完全合成,核糖体便已结合并开始翻译,极大提升了蛋白质合成速率。原核生物mRNA常为多顺反子结构,一条mRNA可编码多个功能相关的蛋白质,且无内含子、无需剪接,可直接作为翻译模板。此外,原核mRNA半衰期极短,便于快速响应环境变化。基因表达主要通过操纵子结构在转录水平进行精细调控,如乳糖操纵子和色氨酸操纵子,使原核生物能够灵活适应多变环境。这些机制共同构成了原核生物中心法则的核心,体现了其高度优化的遗传信息传递系统。 Attachments the-central-dogma-of-molecular-biology1-l • 70 kB • 566 click 2025年12月21日
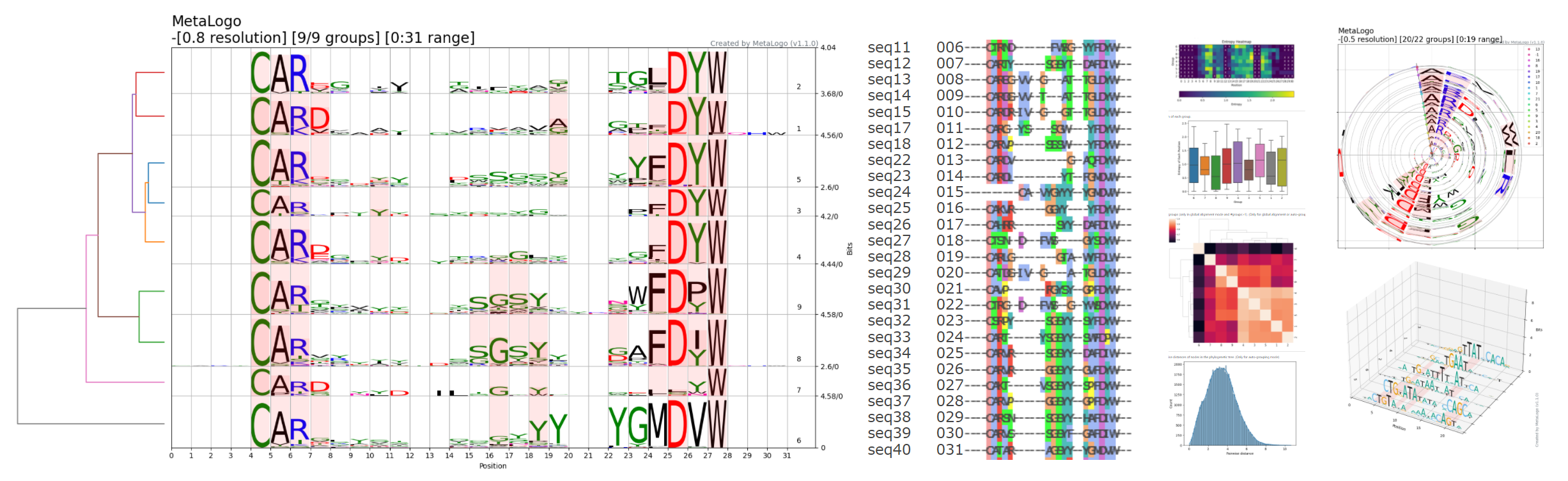
估计阅读时长: 23 分钟Sequence Logo 是一种可视化 DNA 或蛋白质序列保守性的图形表示方法。每个位置(列)上的字母堆叠高度代表该位点的信息含量(以 bits 为单位),而每个字母的高度则与其在该位点出现的频率成正比。高信息量的位置字母堆得高,低信息量的位置则矮甚至接近零。Sequence Logo的绘制遵循信息熵原理,我们可以很直观的通过某一个位置的总高低来了解该处位置的信息含量有多少,高信息量的位置,字母堆的高,一般会出现某一个字符特别高,表明该处非常保守。 位置权重矩阵(Position Weight Matrix, PWM)是描述基因组调控因子结合位点序列模式的核心模型。它通过统计在结合位点序列中每个位置上各核苷酸(或氨基酸)出现的频率,来量化该位置对不同碱基的偏好程度。PWM通常以矩阵形式表示,行对应核苷酸(A、C、G、T/U),列对应序列中的位置,矩阵元素即为该位置该核苷酸相对于背景的权重得分。这一模型简洁且易于计算,因此在转录因子结合位点(TFBS)等调控元件的识别和表征中被广泛采用。 Order by Date Name […]
估计阅读时长: 34 分钟在前面写了一篇文章来介绍我们可以如何通过KEGG的BHR评分来注释直系同源。在KEGG数据库的同源注释算法中,BHR的核心思想是“双向最佳命中”。它比简单的单向BLAST搜索(例如,只看你的基因A在数据库里的最佳匹配是基因B)更为严格和可靠。在基因注释中,这种方法可以有效减少因基因家族扩张、结构域保守等原因导致的假阳性注释,从而更准确地识别直系同源基因,而直系同源基因通常具有相同的功能。在今天重新翻看了下KAAS的帮助文档之后,发现KAAS系统中更新了下面的Assignment score计算公式: We define a score for each ortholog group in order to assign the best […]

估计阅读时长: 5 分钟将复杂的生物学过程拆解为单元化学反应,是进行定量模拟的基石。转录是基因表达调控的关键环节,决定了细胞在特定时间、特定环境下合成哪些蛋白质,对生命活动至关重要。最近的工作中需要将原本非常粗糙的虚拟细胞转录事件模型拆解为更加细分化的多步骤生物化学过程,以适应针对细胞群落生长的建模计算。下面为我将原核生物的转录过程拆解为一系列可以用化学式表示的单元步骤的结果。 在介绍这些分步骤之前,我们会需要首先来定义一下模型中会用到的各种“化学物质”(分子和复合物): RNAP: RNA聚合酶全酶(包含核心酶和σ因子)。 DNA: 基因组DNA双链。 DNA_P: 包含启动子区域的DNA。 DNA_T: 包含终止子区域的DNA。 NTP: 核糖核苷三磷酸(ATP, UTP, GTP, CTP的统称)。 PPi: […]

估计阅读时长: 27 分钟宏基因组测序直接从环境样本获取所有生物的遗传物质,产生的海量短读序列(reads)需要被快速准确地分类到不同物种或功能类别。然而,宏基因组数据具有复杂性高、物种多样且未知序列多等特点,这给分类算法带来了巨大挑战。传统的序列比对方法虽然准确,但在面对庞大的参考数据库时计算开销巨大,难以满足实时分析的需求。因此,研究者开发了多种基于k-mer(长度为k的子序列)的快速分类方法,其中布隆过滤器(Bloom Filter)作为一种高效的概率数据结构,在针对测序reads做物种上的快速分类这项工作中起到了一些关键作用。 Attachments Capture • 112 kB • 616 click 2025年12月19日
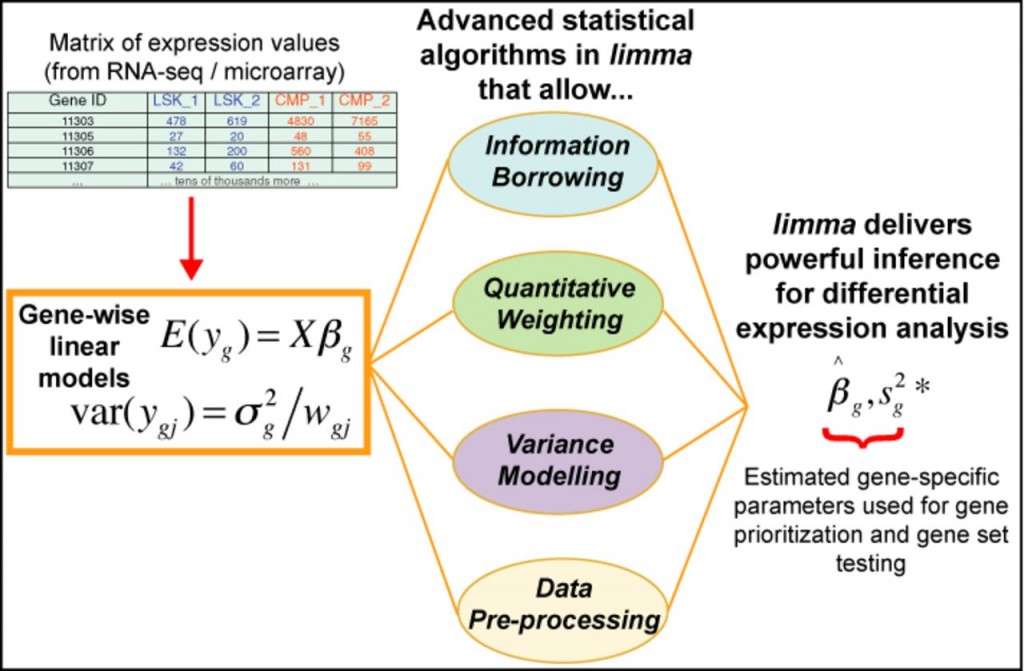
估计阅读时长: 22 分钟limma(Linear Models for Microarray Data)是一个基于R语言的Bioconductor包,最初用于微阵列数据的差异表达分析,现已扩展支持RNA-seq数据。其核心思想是利用线性模型(Linear Models)对基因表达数据进行建模,并结合经验贝叶斯(Empirical Bayes)方法在小样本情况下增强统计推断的稳健性。 Order by Date Name Attachments limma • 119 kB […]

估计阅读时长: 30 分钟零分布(null distribution)是指在假设零假设(null hypothesis)成立的情况下,某个统计量随机取值的概率分布。在统计假设检验中,我们通常提出一个零假设(例如“两组数据没有显著差异”或“观察到的模式仅由随机因素造成”),然后根据观测数据计算一个检验统计量。零分布描述了这个统计量在零假设为真时的分布情况。通过将实际观测到的统计量与零分布进行比较,我们可以计算出P-value:即在零假设下,出现等于或更极端观测结果的概率。如果P-value很小(例如低于预设的显著性水平α),我们就认为零假设不太可能成立,从而拒绝零假设,认为观测结果是统计显著的。 Order by Date Name Attachments image-2 • 66 kB • 591 click 2025年12月16日NULL-pvalue […]
估计阅读时长: 14 分钟宏基因组测序所处理的对象是直接对环境样本中的所有DNA进行测序。达到无需培养即可揭示微生物群落的组成和功能潜力的目的。在数据处理中,一个核心任务是从海量短读序列中估算物种丰度(即每个物种在样本中的相对含量)和基因丰度(即每个基因或功能单元的相对含量)。传统的基于序列比对的方法计算成本高昂,而基于k-mer的方法通过利用固定长度的子序列(k-mer)信息,能够在不依赖完整比对的情况下快速估算丰度。 k-mer是指长度为k的连续子序列,例如在k=2的时候,DNA序列“ATCG”包含的2-mers有“AT”、“TC”、“CG”。通过统计读序列中k-mer的出现频率,并将其与参考数据库中的k-mer频率进行比较,我们可以推断出样本中各物种或基因的丰度。这种方法具有计算速度快、内存效率高的优势,并且无需对每个读进行精确比对,因此在处理大规模宏基因组数据时非常实用。 Order by Date Name Attachments workflow1 • 272 kB • 548 click 2025年12月8日workflow2 • […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?