
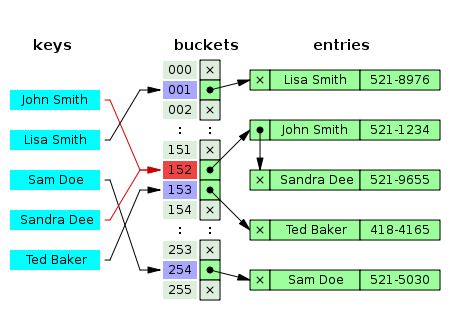
估计阅读时长: 8 分钟在之前的BioDeep代谢物数据库整合工作之中,所提取的代谢物注释信息的唯一编码是来自于数据库表之中的递增主键。由于数据库之中的递增主键的唯一编码值是与数据内容完全无关的数据,所以在基于图数据库做数据库整合的结果在两次整合操作之后,可能会因为先后输出顺序不一致的原因,得到的在关系型数据库中的唯一递增编号可能会完全不一样了。这个问题会对数据库更新操作造成非常大的困扰。 Order by Date Name Attachments 450px-Hash_table_5_0_1_1_1_1_1_LL • 26 kB • 496 click 2022年4月16日metadata-table • 58 […]

[…] 在前面写了一篇文章来介绍我们可以如何通过KEGG的BHR评分来注释直系同源。在KEGG数据库的同源注释算法中,BHR的核心思想是“双向最佳命中”。它比简单的单向BLAST搜索(例如,只看你的基因A在数据库里的最佳匹配是基因B)更为严格和可靠。在基因注释中,这种方法可以有效减少因基因家族扩张、结构域保守等原因导致的假阳性注释,从而更准确地识别直系同源基因,而直系同源基因通常具有相同的功能。在今天重新翻看了下KAAS的帮助文档之后,发现KAAS系统中更新了下面的Assignment score计算公式: […]
不常看到, 没有多余矫饰的表达。敬意。
[…] 在前面写了一篇文章来介绍我们可以如何通过KEGG的BHR评分来注释直系同源。在今天重新翻看了下KAAS的帮助文档之后,发现KAAS系统中更新了下面的Assignment score计算公式: […]
thanks for your comment
What's up, this weekend is nice designed for me, for the reason that this moment i am reading this great…