
文章阅读目录大纲
LCA算法是现代宏基因组学分析的核心技术之一,主要用于解决序列比对结果的分类不确定性问题。例如,我们在处理宏基因组测序reads的物种来源分类注释工作的时候,经常会思考一个问题:在宏基因组分析中,一个测序read通常与多个参考序列产生比对结果,这些结果可能指向不同的分类单元。那这条reads最可能的物种分类来源位置是怎样的,怎样可以通过一个算法,基于一系列的物种匹配结果来推断出一个合适的物种来源,既避免过度分类,又保证分类的准确性。
在宏基因组 reads 分类中,LCA(Lowest Common Ancestor,最低共同祖先)算法的核心作用是解决当一条测序序列可能匹配到多个不同物种的基因组片段时,如何为其分配一个最精确且可靠的物种标签。简单来说,它试图在物种分类学的“家族树”上,为一条序列找到一个最合适的“家”。下面我们先简单的来理解下LCA算法的工作原理基础。
LCA算法的理论基础
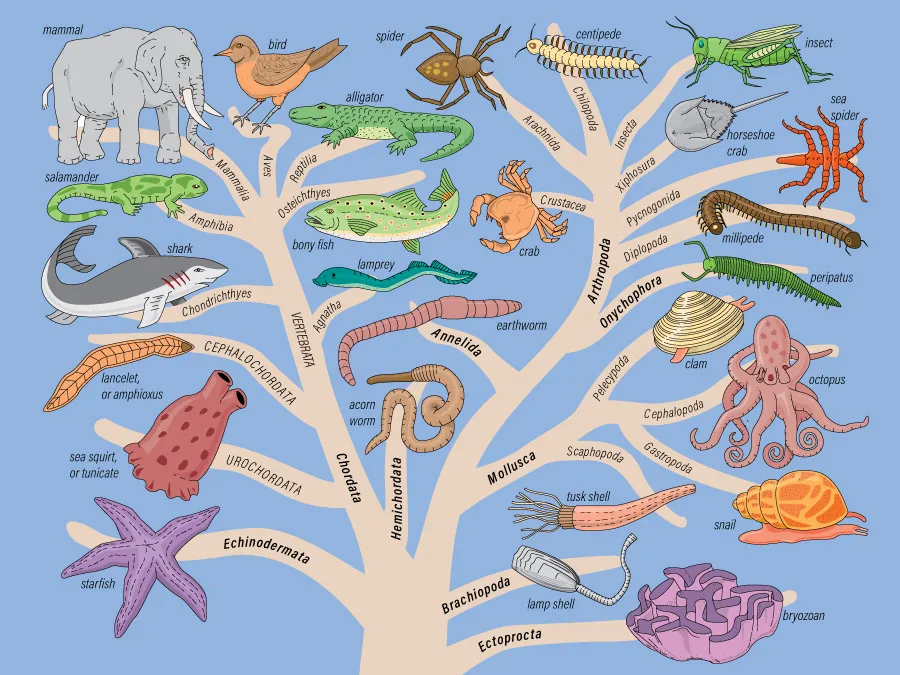
在树状分类学结构中,两个节点的最低共同祖先(LCA)是指同时是这两个节点后代的、且在进化树中位置最低的节点。例如,对于物种A和物种B,它们的LCA就是两者在分类学树中相遇的第一个共同祖先节点。这个概念是LCA算法的核心理论基础。LCA这个算法可以主要分为非加权和加权这两种方法。
对于非加权的LCA方法,我们称之为Naive LCA算法,这种Naive LCA算法是MEGAN软件中采用的基础分类方法。其基本的原理我们可以通过分析MEGAN软件的算法实现了解到:对于每个read的比对结果集,算法收集所有匹配的分类节点,然后找到这些节点在分类树中的最低共同祖先作为最终分类结果。这种方法简单直观,能够有效处理分类不确定性问题。将这个算法进行简单总结和描述,可以得到下面的一些关键的算法步骤:
- 匹配收集:收集read与参考序列比对产生的所有有效匹配结果
- 祖先查询:对于每个匹配的分类节点,获取其在分类树中的完整祖先路径
- LCA计算:比较不同匹配结果的祖先路径,找到最深层的共同祖先节点
- 分类分配:将read分配给计算得到的LCA节点
上面所描述的基础非加权的LCA算法非常简单有效,但是准确度仍然会存在一定的问题。所以为了提高分类准确性,MEGAN引入了加权LCA算法。该方法考虑比对分数、序列覆盖度等因素,为不同的匹配结果赋予不同权重,使得更可靠的匹配结果在LCA计算中具有更大影响力。在这个加权的算法中,主要考虑了下面的方面来做权重计算:
- 序列相似度权重:基于比对分数(如bit score)计算权重
- 覆盖度权重:考虑参考序列的长度和覆盖范围
- 分类等级权重:高等级分类节点赋予更高权重
那,现在我们有了LCA算法之后,就可以进行针对reads的分类不确定性问题的处理了:当一个read与多个不同分类单元产生匹配时,LCA算法通过计算共同祖先自然处理这种不确定性。LCA结果反映了read能够被可靠分类的最高分类等级。以MEGAN软件为例子,在实际的分类计算过程中还会做一些阈值过滤来提高分类注释结果的准确度。例如为控制分类精度,MEGAN支持设置最小支持阈值(min support)和分数阈值等参数。低于阈值的分类结果会被过滤或提升到更高分类等级。
LCA方法的方法学位置比较
为了更全面地理解LCA的方法学地位,我们在这里与主流方法进行了一些简单比较:
- 与直接比对(BWA-MEM)的比较:一些专利方案提到结合k-mer/LCA和BWA-MEM两种算法,用后者校正前者,特别是在低丰度物种识别上显示出优势。这说明LCA方法与直接序列比对方法可以形成互补。
- 与标记基因法(如MetaPhlAn)的比较:标记基因法依赖于预先确定的、物种特异的标记基因,通常分辨率更高、更快速。而基于k-mer和LCA的方法(如Kraken2)不依赖特定基因,理论上能检测数据库内任何物种的任何基因组区域,可能发现更广泛的物种,但计算资源消耗更大。
LCA 算法在基于Kmer的宏基因组学物种注释工作中的应用
Kmer方法是针对宏基因组测序reads序列进行物种来源注释的一种方法,目前主流的基于kmer方法的工具主要为Kraken系列工具。下面的流程图向大家展示了在Kraken工具中,针对某一条reads序列进行基于kmer方法做物种来源注释的工作流程:

从上面的流程图可以看得到,现在假设我们需要针对某一条测序reads序列结果做物种来源分类,则首先需要针对这条reads序列进行kmer的提取,然后进行数据库查找,得到所有的kmer可能的物种来源信息。那现在每一条待注释的reads就可以基于kmer数据库的查询结果得到了非常多的物种来源结果。最后,我们就可以基于LCA算法从得到的物种来源列表做注释推断,通过查找他们的最小的公共祖先分类,得到了这条reads的具体物种分类结果。
在通过LCA方法处理基于kmer的reads物种分类注释的时候,我们可以引入适当的权重处理来提升准确性,例如,可以做加权投票(为匹配度高的k-mer分配更大权重)或设置最小匹配k-mer数量的阈值,从而在保守与精确之间取得更好平衡。
从上面的讨论中,我们可以了解到,LCA算法在宏基因组分类中会扮演着“保守的仲裁者”角色。其最大的优势在于有效控制假阳性(False Positive)。当一条reads因为测序错误、存在跨物种的保守区域(如看家基因)或数据库不完整而匹配到多个物种时,LCA机制防止了将其武断地分配给某一个特定物种(尤其是低分类水平),从而提高了结果的可信度。但是这种分类机制也为我们的分析工作带来了一些分析代价,例如其保守策略的直接后果是可能导致分类分辨率(分辨率)的降低。我们可以想象一下,一条本属于某个特定菌株的reads,因为其k-mer也匹配到近缘物种,最终可能只能被鉴定到“属”甚至“科”的水平,这就很可能会造成信息缺失。这也是为什么像KMCP这样的新工具会引入基因组覆盖度等额外信息来优化,以期在保持低假阳性的同时,提升分辨率。
LCA 算法代码的实现
现在假设我们有如下所示的基于NCBI的物种分类树的数据结构对象:
''' <summary>
''' The tree node calculation model for <see cref="NcbiTaxonomyTree"/>, a labeled tree node for a specific ncbi taxid.
''' </summary>
Public Class TaxonomyNode
' the NCBI taxonomy id
Public Property taxid As Integer
' the scientific name of current taxonomy node
Public Property name As String
' One of the value in array collection <see cref="NcbiTaxonomyTree.stdranks"/>.
Public Property rank As String
' 当前的节点的父节点的编号: ``<see cref="taxid"/>``
Public Property parent As String
Public Property children As String()
End Class然后我们可以基于NCBI的物种分类树对象的GetAscendantsWithRanksAndNames

那,现在基于上面的信息就足够我们来计算出任意两个物种之间的最短公共祖先节点了,对应的计算代码如下所示:
''' <summary>
''' 使用路径比较法计算两个taxid的最近公共祖先(LCA)
''' </summary>
''' <param name="taxid1">第一个taxonomy ID</param>
''' <param name="taxid2">第二个taxonomy ID</param>
''' <returns>最近公共祖先的TaxonomyNode,如果找不到返回Nothing</returns>
Public Function GetLCA(taxid1 As Integer, taxid2 As Integer) As TaxonomyNode
If taxid1 = taxid2 Then
Return _taxonomyTree.GetAscendantsWithRanksAndNames(taxid1).FirstOrDefault()
End If
' 获取两个taxid到根节点的完整路径
Dim path1 = _taxonomyTree.GetAscendantsWithRanksAndNames(taxid1)
Dim path2 = _taxonomyTree.GetAscendantsWithRanksAndNames(taxid2)
If path1.Length = 0 OrElse path2.Length = 0 Then
Return Nothing
End If
' 反转路径,使其从根节点开始
Dim reversedPath1 = path1.Reverse().ToArray()
Dim reversedPath2 = path2.Reverse().ToArray()
' 找到最后一个共同的祖先
Dim lcaNode As TaxonomyNode = Nothing
Dim minLength = Math.Min(reversedPath1.Length, reversedPath2.Length)
For i As Integer = 0 To minLength - 1
If reversedPath1(i).taxid = reversedPath2(i).taxid Then
lcaNode = reversedPath1(i)
Else
Exit For
End If
Next
Return lcaNode
End Function如何来理解这个最简单的LCA方法的实现:首先我们会需要根据需要做计算的两个物种编号之间,通过物种树拿到物种的分类路径。然后我们根据所拿到的两条路径,从根分类节点开始,一直往下找,一直直到找到不同的节点为止。这个时候,找到的这个节点就是我们需要做计算的两个目标节点的公共祖先节点了。

那现在有了上面的基于对任意两个物种间的LCA节点的计算,现在我们就可以基于这个基础方法做外推,编写出可以用于宏基因组数据处理的,基于输入任意物种编号集合,拿到这个集合所对应的LCA节点计算的方法:
''' <summary>
''' 计算多个taxid的最近公共祖先
''' </summary>
''' <param name="taxids">taxonomy ID集合</param>
''' <returns>最近公共祖先的TaxonomyNode</returns>
Public Function GetLCA(taxids As IEnumerable(Of Integer)) As TaxonomyNode
If taxids Is Nothing OrElse Not taxids.Any() Then
Return Nothing
End If
' 将第一个taxid的路径作为起始的LCA
Dim taxidList = taxids.ToList()
Dim currentLCA As TaxonomyNode = _taxonomyTree.GetAscendantsWithRanksAndNames(taxidList(0)).FirstOrDefault()
If currentLCA Is Nothing Then
Return Nothing
End If
' 从第二个taxid开始,依次与当前的LCA进行计算
For i As Integer = 1 To taxidList.Count - 1
Dim nextTaxid As Integer = taxidList(i)
currentLCA = GetLCA(currentLCA.taxid, nextTaxid)
If currentLCA Is Nothing Then
Exit For
End If
Next
Return currentLCA
End Function在这里我们可以看得到,做宏基因组的reads里面所有kmer匹配出来的物种信息的LCA的计算,其实就是不断地基于任意两个物种的LCA节点计算的For循环的迭代实现,一直进行公共祖先节点交集的计算,直到查找出能够包含有所有输入的物种的LCA节点。那,基于上面的算法实现基础,我们就可以写出如下所示的带有阈值过滤参数的,可以直接用在宏基因组reads物种注释分类的LCA计算函数:
''' <summary>
''' LCA计算结果
''' </summary>
Public Class LcaResult
Public Property lcaNode As TaxonomyNode
Public Property supportRatio As Double
Public Property supportedTaxids As Integer()
Public Overrides Function ToString() As String
If lcaNode Is Nothing Then
Return "LCA not found"
Else
Return $"LCA: {lcaNode.name} (taxid: {lcaNode.taxid}, rank: {lcaNode.rank}), Support: {supportRatio:P2}"
End If
End Function
End Class
''' <summary>
''' 在宏基因组分类场景中常用的LCA方法:找到覆盖所有输入taxid的最小公共分类单元
''' </summary>
''' <param name="taxids">k-mer匹配到的所有taxonomy ID集合</param>
''' <param name="minSupport">最小支持度阈值(0-1之间)</param>
''' <returns>LCA结果及其支持度信息</returns>
Public Function GetLCAForMetagenomics(taxids As IEnumerable(Of Integer), Optional minSupport As Double = 0.5) As LcaResult
If taxids Is Nothing OrElse Not taxids.Any() Then
Return New LcaResult With {
.lcaNode = Nothing,
.supportRatio = 0,
.supportedTaxids = New Integer() {}
}
End If
Dim taxidList = taxids.Distinct().ToArray()
If taxidList.Count = 1 Then
Return New LcaResult With {
.lcaNode = _taxonomyTree.GetAscendantsWithRanksAndNames(taxidList(0)).FirstOrDefault(),
.supportRatio = 1.0,
.supportedTaxids = taxidList
}
End If
' 计算所有taxid的LCA
Dim lcaNode As TaxonomyNode = GetLCA(taxidList)
If lcaNode Is Nothing Then
Return New LcaResult With {
.lcaNode = Nothing,
.supportRatio = 0,
.supportedTaxids = New Integer() {}
}
End If
' 计算支持度:有多少taxid是LCA的后代
Dim supportedCount = taxidList.AsEnumerable.Count(Function(taxid) Check(taxid, lcaNode))
Dim supportRatio = supportedCount / taxidList.Length
' 如果支持度低于阈值,尝试在更高层级寻找LCA
If supportRatio < minSupport Then
Dim currentLca = lcaNode
While currentLca IsNot Nothing AndAlso currentLca.parent IsNot Nothing
Dim parentNode = _taxonomyTree(Integer.Parse(currentLca.parent))
Dim parentSupportedCount = taxidList.AsEnumerable.Count(Function(taxid) Check(taxid, parentNode))
Dim parentSupportRatio = parentSupportedCount / taxidList.Length
If parentSupportRatio >= minSupport Then
lcaNode = parentNode
supportRatio = parentSupportRatio
Exit While
End If
currentLca = parentNode
End While
End If
Return New LcaResult With {
.lcaNode = lcaNode,
.supportRatio = supportRatio,
.supportedTaxids = taxidList.Where(Function(taxid) Check(taxid, lcaNode)).ToArray
}
End Function在R#语言中的LCA算法实例
将上面所描述的LCA算法导出为GCModeller程序中的一个工具函数后,我们就可以在R#脚本语言中进行相关的LCA祖先节点的计算,下面为一个demo脚本:
require(GCModeller);
imports "taxonomy_kit" from "metagenomics_kit";
let ncbi_tax = Ncbi.taxonomy_tree("D:\\datapool\\taxdump");
let humanTaxid = 9606; # Homo sapiens
let mouseTaxid = 10090; # Mus musculus
let ratTaxid = 10116; # rat
str(ncbi_tax |> taxonomy_kit::LCA(c(humanTaxid, mouseTaxid, ratTaxid), min.supports = 0.5));
# List of 3
# $ support_ratio : num 1
# $ supported_taxids : int [1:3] 9606 10090 10116
# $ lca : List of 5
# ..$ taxid : int 314146
# ..$ name : chr "Euarchontoglires"
# ..$ rank : chr "superorder"
# ..$ parent : <NULL>
# ..$ childs : any [1:0] [
#
# ]
在上面的demo中,我们假设做宏基因组测序,某一条reads做kmer数据库查询,得到了三个来源物种的物种编号信息。然后我们现在需要基于这个kmer查询的结果,对这条reads做物种分类注释,那么就可以一通过LCA算法来做注释分类计算:

结果显示,我们通过测序得到的reads很有可能是来源于灵长总目(学名:Euarchontoglires)这个物种分类。灵长总目(学名:Euarchontoglires)是哺乳纲真兽亚纲下的一个总目,包含啮齿目、兔形目、树鼩目、皮翼目和灵长目。
- 最低共同祖先(Lowest Common Ancestor, LCA)算法讲解 - 2025年12月2日
- 宏基因组去除宿主序列的主流算法原理与基于kmer的方法详解 - 2025年11月29日
- 微生物全基因组代谢网络(GEM)模型发展历史与原理综述 - 2025年11月25日

No responses yet